python xjb学
python 环境
virtual env
A virtual environment is a Python tool for dependency management and project isolation. They allow Python site packages (third party libraries) to be installed locally in an isolated directory for a particular project, as opposed to being installed globally (i.e. as part of a system-wide Python).
Well, a virtual environment is just a directory with three important components:
- A
site-packages/folder where third party libraries are installed. - Symlinks to Python executables installed on your system.
- Scripts that ensure executed Python code uses the Python interpreter and site packages installed inside the given virtual environment.
cd test-project/ |
to set a project
python3 -m venv venv/ |
how does it work?
when acitvate venv, it changes $PATH /Users/akunda/project/pythonenv/venv/bin:...
pycharm
conda venv existed
python 手册
https://docs.python.org/zh-cn/3/reference/import.html
词法分析
编码声明
# -*- coding: <encoding-name> -*-显式拼接行
\字符串前缀:
bbytes 实例;r原始字符串, 把反斜杠当做原义字符, 不执行转义操作;rb; 三引号包含未转义的换行和引号;!--code2-->字符串合并
"hello"'world' == "helloworld"
数据模型
每个对象都有各自的标识号、类型和值。一个对象被创建后,它的 标识号 就绝不会改变;你可以将其理解为该对象在内存中的地址。 'is' 运算符可以比较两个对象的标识号是否相同;id() 函数能返回一个代表其标识号的整数。
对象的类型决定该对象所支持的操作 (例如 "对象是否有长度属性?") 并且定义了该类型的对象可能的取值。type() 函数能返回一个对象的类型 (类型本身也是对象)。与编号一样,一个对象的 类型 也是不可改变的
对象绝不会被显式地销毁;然而,当无法访问时它们可能会被作为垃圾回收。
有些对象包含对其他对象的引用;它们被称为 容器。容器的例子有元组、列表和字典等。这些引用是容器对象值的组成部分。在多数情况下,当谈论一个容器的值时,我们是指所包含对象的值而不是其编号;但是,当我们谈论一个容器的可变性时,则仅指其直接包含的对象的编号。因此,如果一个不可变容器 (例如元组) 包含对一个可变对象的引用,则当该可变对象被改变时容器的值也会改变。
None,
整型 (int)
此类对象表示任意大小的数字,仅受限于可用的内存 (包括虚拟内存)。在变换和掩码运算中会以二进制表示,负数会以 2 的补码表示,看起来像是符号位向左延伸补满空位。
布尔型 (bool)
此类对象表示逻辑值 False 和 True。代表 False 和 True 值的两个对象是唯二的布尔对象。布尔类型是整型的子类型,两个布尔值在各种场合的行为分别类似于数值 0 和 1,例外情况只有在转换为字符串时分别返回字符串 "False" 或 "True"。
字典
此类对象表示由几乎任意值作为索引的有限个对象的集合。不可作为键的值类型只有包含列表或字典或其他可变类型,通过值而非对象编号进行比较的值,其原因在于高效的字典实现需要使用键的哈希值以保持一致性。用作键的数字类型遵循正常的数字比较规则: 如果两个数字相等 (例如 1 和 1.0) 则它们均可来用来索引同一个字典条目。字典会保留插入顺序,这意味着键将以它们被添加的顺序在字典中依次产生。 替换某个现有的键不会改变其顺序,但是移除某个键再重新插入则会将其添加到末尾而不会保留其原有位置。字典是可变的;它们可通过 {...} 标注来创建 (参见 字典显示 小节)。扩
函数(可调用对象)
特殊属性
__doc__ |
该函数的文档字符串,没有则为 None;不会被子类继承。 |
可写 |
|---|---|---|
__name__ |
该函数的名称。 | 可写 |
__qualname__ |
该函数的 qualified name。3.3 新版功能. | 可写 |
__module__ |
该函数所属模块的名称,没有则为 None。 |
可写 |
__defaults__ |
由具有默认值的参数的默认参数值组成的元组,如无任何参数具有默认值则为 None。 |
可写 |
__code__ |
表示编译后的函数体的代码对象。 | 可写 |
__globals__ |
对存放该函数中全局变量的字典的引用 --- 函数所属模块的全局命名空间。 | 只读 |
__dict__ |
命名空间支持的函数属性。 | 可写 |
__closure__ |
None 或包含该函数可用变量的绑定的单元的元组。有关 cell_contents 属性的详情见下。 |
只读 |
__annotations__ |
包含形参标注的字典。 字典的键是形参名,而如果提供了 'return' 则是用于返回值标注。 有关如何使用此属性的更多信息,请参阅 对象注解属性的最佳实践。 |
可写 |
__kwdefaults__ |
仅包含关键字参数默认值的字典。 | 可写 |
模块
模块的名称。
__doc__ |
模块的文档字符串,如果不可用则为 None。
被加载模块所对应文件的路径名称,如果它是从文件加载的话。 对于某些类型的模块来说 __file__ 属性可能是缺失的,例如被静态链接到解释器中的 C 模块。 对于从共享库动态加载的扩展模块来说,它将是共享库文件的路径名称。
__annotations__ |
包含在模块体执行期间收集的 变量标注 的字典。 有关使用 __annotations__ 的最佳实践,请参阅 对象注解属性的最佳实践。
特殊的只读属性: __dict__ 为以字典对象表示的模块命名空间。
执行模型
作用域 定义了一个代码块中名称的可见性。 如果代码块中定义了一个局部变量,则其作用域包含该代码块。 如果定义发生于函数代码块中,则其作用域会扩展到该函数所包含的任何代码块,除非有某个被包含代码块引入了对该名称的不同绑定。
如果 global 语句出现在一个代码块中,则所有对该语句所指定名称的使用都是在最高层级命名空间内对该名称绑定的引用。 名称在最高层级命名内的解析是通过全局命名空间,也就是包含该代码块的模块的命名空间,以及内置命名空间即 builtins 模块的命名空间。 全局命名空间会先被搜索。 如果未在其中找到指定名称,再搜索内置命名空间。 global 语句必须位于所有对其所列出名称的使用之前。
global 语句与同一代码块中名称绑定具有相同的作用域。 如果一个自由变量的最近包含作用域中有一条 global 语句,则该自由变量也会被当作是全局变量。
导入系统
常规包
通常以一个包含 __init__.py 文件的目录形式实现。 当一个常规包被导入时,这个 __init__.py 文件会隐式地被执行,它所定义的对象会被绑定到该包命名空间中的名称。__init__.py 文件可以包含与任何其他模块中所包含的 Python 代码相似的代码,Python 将在模块被导入时为其添加额外的属性。
例如,以下文件系统布局定义了一个最高层级的 parent 包和三个子包:
导入 parent.one 将隐式地执行 parent/__init__.py 和 parent/one/__init__.py。 后续导入 parent.two 或 parent.three 则将分别执行 parent/two/__init__.py 和 parent/three/__init__.py。
parent/ |
命名空间包
命名空间包是由多个 部分 构成的,每个部分为父包增加一个子包。 各个部分可能处于文件系统的不同位置。 部分也可能处于 zip 文件中、网络上,或者 Python 在导入期间可以搜索的其他地方。 命名空间包并不一定会直接对应到文件系统中的对象;它们有可能是无实体表示的虚拟模块。
命名空间包的 __path__ 属性不使用普通的列表。 而是使用定制的可迭代类型,如果其父包的路径 (或者最高层级包的 sys.path) 发生改变,这种对象会在该包内的下一次导入尝试时自动执行新的对包部分的搜索。
命名空间包没有 parent/__init__.py 文件。 实际上,在导入搜索期间可能找到多个 parent 目录,每个都由不同的部分所提供。 因此 parent/one 的物理位置不一定与 parent/two 相邻。 在这种情况下,Python 将为顶级的 parent 包创建一个命名空间包,无论是它本身还是它的某个子包被导入。
另请参阅 PEP 420 了解对命名空间包的规格描述。
class
class Complex: |
class Dog: |
继承
class DerivedClassName(BaseClassName): |
Python有两个内置函数可被用于继承机制:
- 使用
isinstance()来检查一个实例的类型:isinstance(obj, int)仅会在obj.__class__为int或某个派生自int的类时为True。 - 使用
issubclass()来检查类的继承关系:issubclass(bool, int)为True,因为bool是int的子类。 但是,issubclass(float, int)为False,因为float不是int的子类。
逻辑值检测
任何对象都可以进行逻辑值的检测,以便在 if 或 while 作为条件或是作为下文所述布尔运算的操作数来使用。
一个对象在默认情况下均被视为真值,除非当该对象被调用时其所属类定义了 __bool__() 方法且返回 False 或是定义了 __len__() 方法且返回零。 1 下面基本完整地列出了会被视为假值的内置对象:
- 被定义为假值的常量:
None和False。 - 任何数值类型的零:
0,0.0,0j,Decimal(0),Fraction(0, 1) - 空的序列和多项集:
'',(),[],{},set(),range(0)
类的字符串化
def __repr__(self): |
python 编程之美
pip install autopep8 |
def func(positional, keyword=value, *args, **kwargs): pass
位置参数是强制性的,且没有默认值。 关键字参数是可选的,有默认值。 任意数量参数列表是可选的,没有默认值。 任意数量关键字参数字典是可选的,没有默认值。
私有属性和实现细节的主要约定是为所有“内部”变量名称加“_”前缀(例如,sys._ getframe)。如果使用方代码打破了这个规则并访问了这些变量,那么任何由代码修改引 发的不当行为或问题都由使用方负责。
d = {'hello': 'world'} |
# 列表解析 |
()用来续行 instead of
解包:
filename, ext = "my_photo.orig.png".rsplit(".", 1) |
four_nones = [None] * 4 |
with 语句和上下文管理协议使得代 码可读性更高。该协议包含两个方法 :__enter__() 和 __exit__(),如果一个对象实现了这两个方法,就能用在 with 语句中
因为处理文件 I/O 的对象已经定义了 __enter__() 和 __exit__() 方法 ,所以可以直接用在 with 语句中,不需要 closing。
import threading |
新列表仅会在函数定义时被创建一次,后续每次函数调用都使用同一个列表。在函 数被定义时而不是在每次函数调用时(如 Ruby 中那样),就会计算 Python 的默认 参数。这意味着如果使用一个可变默认参数并修改它,那么也就修改了后续调用该 函数时使用的那个对象。
def time_consuming_function(x, y, cache={}): |
Python闭包
1.什么是闭包,闭包必须满足以下3个条件:
必须是一个嵌套的函数。 闭包必须返回嵌套函数。 嵌套函数必须引用一个外部的非全局的局部自由变量。 举个栗子
# 嵌套函数但不是闭包 |
2.闭包优点
避免使用全局变量 可以提供部分数据的隐藏 可以提供更优雅的面向对象实现 优点1,2 就不说了,很容易理解,关于第三个,例如当在一个类中实现的方法很少时,或者仅有一个方法时,就可以选择使用闭包。
举个栗子
# 用类实现一个加法的类是这样 |
闭包的概念差不多就是这样了。
Python 延迟绑定
def multipliers(): |
下面来解释为什么输出结果是[6,6,6,6]。
运行代码,代码从第13行开始运行,解释器碰到了一个列表解析,循环取multipliers()函数中的值,而multipliers()函数返回的是一个列表对象,这个列表中有4个元素,每个元素都是一个匿名函数(实际上说是4个匿名函数也不完全准确,其实是4个匿名函数计算后的值,因为后面for i 的循环不光循环了4次,同时提还提供了i的变量引用,等待4次循环结束后,i指向一个值i=3,这个时候,匿名函数才开始引用i=3,计算结果。所以就会出现[6,6,6,6],因为匿名函数中的i并不是立即引用后面循环中的i值的,而是在运行嵌套函数的时候,才会查找i的值,这个特性也就是延迟绑定)
为了便于理解,你可以想象下multipliers内部是这样的(这个是伪代码,并不是准确的):
def multipliers(): |
因为Python解释器,遇到lambda(类似于def),只是定义了一个匿名函数对象,并保存在内存中,只有等到调用这个匿名函数的时候,才会运行内部的表达式,而for i in range(4) 是另外一个表达式,需等待这个表达式运行结束后,才会开始运行lambda 函数,此时的i 指向3,x指向2
添加了一个i=i后,就给匿名函数,添加了一个默认参数,而python函数中的默认参数,是在python 解释器遇到def(i=i)或lambda 关键字时,就必须初始化默认参数,此时for i in range(4),每循环一次,匿名函数的默认参数i,就需要找一次i的引用,i=0时,第一个匿名函数的默认参数值就是0,i=1时,第二个匿名函数的默认参数值就是1,以此类推。
为了便于理解,你可以想象下multipliers内部是这样的(这个是伪代码只是为了理解):
def multipliers(): |
模块
首先,import modu 语句会在调用者所在的当前目录下查找 modu.py 文件, 如果存在则直接调用它。如果没找到,那么 Python 解释器将在 Python 搜索路径中递归查找该文件,若仍然没找到,则抛出 ImportError 异常。搜索路径与平台相关,包含环境变量 $PYTHONPATH(或 Windows 中的 %PYTHONPATH%)中用户或者系统定义的任意文件目录,可以在 Python 会话中 检查或修改搜索路径。
一旦找到 modu.py 文件,Python 解释器将在隔离作用域执行这个模块。modu.py 中的所 有顶层语句都会被执行,包括可能存在的其他模块导入。函数和类的定义保存在模块字 典中。
包
任何包含 init.py 文件的目录都会被视作一个 Python 包。包含 init.py 的顶级目 录是根包(root package)9。导入包里的各个模块和导入普通模块的方式类似,不过 __ init__.py 文件用于收集所有包范围(package-wide)的定义。
pack 目录下的 modu.py 文件可以通过 import pack.modu 语句导入。首先,解释器会在 pack 目录下查找 init.py 文件并执行其中的所有顶级语句。然后,查找文件 pack/ modu.py 并执行其中的所有顶级语句。这些操作执行后,modu.py 中定义的任何变量、 函数或者类都能在 pack.modu 命名空间中找到。
散
变量作用域和生存周期
Python的作用域一共有4层,分别是:
- L (Local) 局部作用域, 例如函数内
- E (Enclosing) 闭包函数外的函数中, 例如函数有函数, 外层函数中的局部变量相对于内层函数就是 enclosing
- G (Global) 全局作用域
- B (Built-in) 内建作用域
L –> E –> G –>B的规则查找变量
x = int(2.9) # 内建作用域,查找int函数 |
想要在函数内部修改外面的全局变量, 使用global关键字 inner内部想使用outer里面的变量, 用 nonlocal 关键字
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
正则表达式(re)
- r"string"的内容不会转义
re.match 返回匹配对象Match
Match.group()可以找匹配对应的内容(在Pattern里加好括号)
或者直接以数组形式访问
匹配中文字符的正则表达式: [-]
idPattern = re.compile( |
删除文件
os.remove(filepath)
range
range(3)
0,1,2
numpy
ndarray类
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
ndarray属性
属性 说明 ndarray.ndim 秩,即轴的数量或维度的数量 ndarray.shape 数组的维度,对于矩阵,n 行 m 列 ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值 ndarray.dtype ndarray 对象的元素类型 ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位 ndarray.flags ndarray 对象的内存信息 nd,array.real ndarray元素的实部 ndarray.imag ndarray 元素的虚部 ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 dtype类
创建数组:
numpy.empty(shape, dtype = float, order = 'C')
numpy.zeros(shape, dtype = float, order = 'C')
numpy.ones(shape, dtype = None, order = 'C')
numpy.asarray(a, dtype = None, order = None) # a为输入数组,如列表,元组等
numpy.arange(start, stop, step, dtype)数组运算(broadcast)
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
- 数组拥有相同形状。
- 当前维度的值相等。
- 当前维度的值有一个是 1。
若条件不满足,抛出 "ValueError: frames are not aligned" 异常。
.T数组转置
最大最小
numpy.amin(array, axis) 用于计算数组中的元素沿指定轴的最小值。
numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
极差np.ptp(a, axis = 0
算数平均值numpy.mean()
加权平均值numpy.average()
标准差
std = sqrt(mean((x - x.mean())**2))
np.std([1,2,3,4])
方差numpy.var()
部分函数
numpy.sum
import numpy as np
a = np.array([[1, 5, 5, 2],
[9, 6, 2, 8],
[3, 7, 9, 1]])
print(np.sum(a, axis=0))
# 为了描述方便,a就表示这个二维数组,np.sum(a, axis=0)的含义是a[0][j],a[1][j],a[2]j对应项相加的结果.即[1,5,5,2]+[9,6,2,8]+[3,7,9,1]=[13,18,16,11].numpy.tile
说白了,就是把数组沿各个方向复制
比如 a = np.array([0,1,2]), np.tile(a,(2,1))就是把a先沿x轴(就这样称呼吧)复制1倍,即没有复制,仍然是 [0,1,2]。 再把结果沿y方向复制2倍,即最终得到
array([[0,1,2],
[0,1,2]])
b = np.array([[1, 2], [3, 4]])
np.tile(b, 2) #沿X轴复制2倍
array([[1, 2, 1, 2],
[3, 4, 3, 4]])
np.tile(b, (2, 1))#沿X轴复制1倍(相当于没有复制),再沿Y轴复制2倍
array([[1, 2],
[3, 4],
[1, 2],
[3, 4]])
函数自动添加注释
输入```后再输入回车
def AddLoglevel(table, pre_number): |
##关键词?
编码 # -*- coding: UTF-8 -*- 或者 # coding=utf-8
括号 ()元组 []列表 {}字典
global python如果想使用作用域之外的全局变量,则需要加global前缀。
a = 5 |
pycache文件 是产生的二进制文件,如果存在,下次执行代码就可不用编译节省时间
extend & append extend将参数list里的每一个元素加到列表中,append将整个对象加入列表中
切片 L[0:3] 取列表L的前三个元素
list slice
str_object[start_pos:end_pos:step] |
切片以start_pos索引(包括)开始(0),以end_pos索引(排除)结束(长度)。step参数用于指定从开始到结束索引要执行的步骤。
Python字符串切片始终遵循以下规则:s [:i] + s [i:] == s用于任何索引'i'。
foo&bar&baz 意思就是张三李四王二麻子
字典
访问字典就像访问数组一样 dic[key]
判断字典里是否有key的方法
- d.has_key('name')
- ‘name’ in d.keys()
##类class
类的方法第一个参数必须是self,self代表当前类的实例,self.__class__指向类
##python目录
###模块module
import module
module.func()
from module import *
func()
命名空间 dir()函数显示命名空间里所有的变量名字
###包package
文件夹 包含__init__.py
lambda函数
Python中,lambda函数也叫匿名函数,及即没有具体名称的函数,它允许快速定义单行函数,类似于C语言的宏,可以用在任何需要函数的地方。这区别于def定义的函数。 lambda与def的区别: 1)def创建的方法是有名称的,而lambda没有。 2)lambda会返回一个函数对象,但这个对象不会赋给一个标识符,而def则会把函数对象赋值给一个变量(函数名)。 3)lambda只是一个表达式,而def则是一个语句。 4)lambda表达式” : “后面,只能有一个表达式,def则可以有多个。 5)像if或for或print等语句不能用于lambda中,def可以。 6)lambda一般用来定义简单的函数,而def可以定义复杂的函数。 6)lambda函数不能共享给别的程序调用,def可以。 lambda语法格式: lambda 变量 : 要执行的语句
函数传参(可变不可变参数)
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
数据类型转换
- str float bytes 转 int int()
- str int bytes 转 float float()
- str float bytes 转 complex complex()
- str()可转换任意类型
- str 转 bytes bytes()
- list() tuple()
循环
- while,for循环可以用else
- for i in sequence
- 多变量循环 for title, mark in zip(titles, marks): ## GUI
tkinter包
说明:py自带包,跨平台,简单 直接看文档就行 布局:grid pack place master 父组件,frame一般认为master=None StringVar
线程
threading包
先创建,再start,join主线程,分线程结束后主线程才结束 线程安全
format函数
date
#!/usr/bin/python3 |
string转time
from datetime import datetime |
下划线
_var 单个下划线是一个Python命名约定,表示这个名称是供内部使用的。 它通常不由Python解释器强制执行,仅仅作为一种对程序员的提示。
Var_ 有时候,一个变量的最合适的名称已经被一个关键字所占用。 因此,像class或def这样的名称不能用作Python中的变量名称。 在这种情况下,你可以附加一个下划线来解决命名冲突
__var 双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突。这也叫做名称修饰(name mangling) - 解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。
class Test:
def __init__(self):
self.foo = 11
self._bar = 23
self.__baz = 23
t = Test()
dir(t)#内置函数
['_Test__baz', '__class__', '__delattr__', '__dict__', '__dir__',
'__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'__weakref__', '_bar', 'foo']__var__ Python保留了有双前导和双末尾下划线的名称,用于特殊用途。 这样的例子有,__init__对象构造函数,或__call__ --- 它使得一个对象可以被调用。而且不会有名称修饰
_ 单下划线表示一个临时变量。除了用作临时变量之外,“_”是大多数Python REPL中的一个特殊变量,它表示由解释器评估的最近一个表达式的结果。
装饰器
@符号的意义
就是将一个函数包装起来,而且能保持代码结构不变
迭代器
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter()(用于通过列表创建迭代器) 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
with
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
(1)紧跟with后面的语句被求值后,返回对象的“–enter–()”方法被调用,这个方法的返回值将被赋值给as后面的变量; (2)当with后面的代码块全部被执行完之后,将调用前面返回对象的“–exit–()”方法。
with open("1.txt") as file: |
字符串格式化
%[数据名称][对齐标志][宽度].[精度]类型

str.format函数
[[填充字符]对齐方式][符号标志][#][宽度][,][.精度][类型]
'{:S^+#016,.2f}'.format(1234) # 输出'SSS+1,234.00SSSS'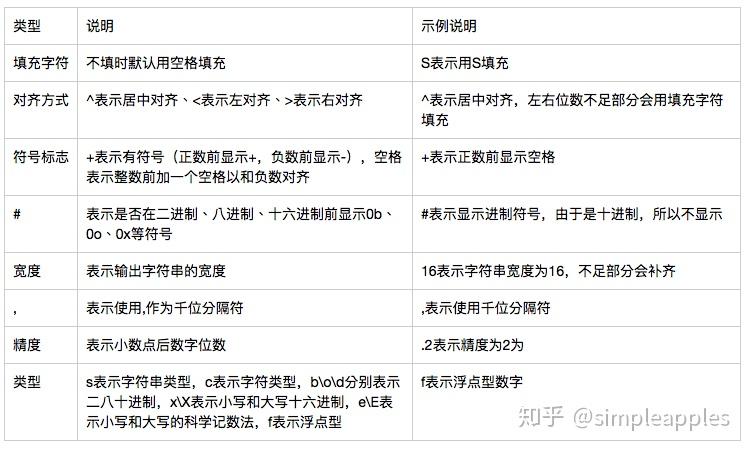
f-string
'My name is %s and i'm %s years old.' % (name, age)
'My name is {} and i'm {} years old.'.format(name, age)
f'My name is {name} and i'm {age} years old.'
虚拟环境
神奇的库
tqdm 进度条
generator&yield
generator参考网站
如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
L = [x * x for x in range(10)] |
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值(每一次generator的值都会更新)
for n in g: |
yield
通常的for...in...循环中,in后面是一个数组,这个数组就是一个可迭代对象,类似的还有链表,字符串,文件。它可以是mylist = [1, 2, 3],也可以是mylist = [x*x for x in range(3)]。 它的缺陷是所有数据都在内存中,如果有海量数据的话将会非常耗内存。
生成器是可以迭代的,但只可以读取它一次。因为用的时候才生成。比如 mygenerator = (x*x for x in range(3)),注意这里用到了(),它就不是数组,而上面的例子是[]。
我理解的生成器(generator)能够迭代的关键是它有一个next()方法,工作原理就是通过重复调用next()方法,直到捕获一个异常。可以用上面的mygenerator测试。
带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代,工作原理同上。
yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行。
简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。
带有yield的函数不仅仅只用于for循环中,而且可用于某个函数的参数,只要这个函数的参数允许迭代参数。比如array.extend函数,它的原型是array.extend(iterable)。
send(msg)与next()的区别在于send可以传递参数给yield表达式,这时传递的参数会作为yield表达式的值,而yield的参数是返回给调用者的值。——换句话说,就是send可以强行修改上一个yield表达式值。比如函数中有一个yield赋值,a = yield 5,第一次迭代到这里会返回5,a还没有赋值。第二次迭代时,使用.send(10),那么,就是强行修改yield 5表达式的值为10,本来是5的,那么a=10
send(msg)与next()都有返回值,它们的返回值是当前迭代遇到yield时,yield后面表达式的值,其实就是当前迭代中yield后面的参数。
第一次调用时必须先next()或send(None),否则会报错,send后之所以为None是因为这时候没有上一个yield(根据第8条)。可以认为,next()等同于send(None)。
anaconda+mac+pycharm
下载安装 anaconda
下载安装 pycharm
anaconda 安装环境, 可以在创建的环境里用 terminal+pip安装难装的库
在pycharm 项目的 interpreter 里选择 anaconda 装好的环境
可以再命令行里用
conda env list命令来找到环境目录, 选择 bin 里的 python 就能使用环境啦!在安装 tensorflow 的时候用了清华的镜像速度快
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
conda create -n tensorflow python=3.7
使用建好的名为 tensorflow 的环境
pip install --upgrade --ignore-installed tensorflow






