为什么这么设计
https://draveness.me/whys-the-design/
为什么设计系列文章总结
为什么 TCP 建立连接需要三次握手
什么是连接: The reliability and flow control mechanisms described above require that TCPs initialize and maintain certain status information for each data stream. The combination of this information, including sockets, sequence numbers, and window sizes, is called a connection.
主要原因: 阻止历史的重复连接初始化 使用三次握手和 RST 控制消息(Reset the connection)将是否建立连接的最终控制权交给了发送方,因为只有发送方有足够的上下文来判断当前连接是否是错误的或者过期的,这也是 TCP 使用三次握手建立连接的最主要原因。
- 『两次握手』:无法避免历史错误连接的初始化,浪费接收方的资源; 想象一下这个场景,如果通信双方的通信次数只有两次,那么发送方一旦发出建立连接的请求之后它就没有办法撤回这一次请求,如果在网络状况复杂或者较差的网络中,发送方连续发送多次建立连接的请求,如果 TCP 建立连接只能通信两次,那么接收方只能选择接受或者拒绝发送方发起的请求,它并不清楚这一次请求是不是由于网络拥堵而早早过期的连接。 三次握手由发起方判断是否是历史连接
- 『四次握手』:TCP 协议的设计可以让我们同时传递
ACK和SYN两个控制信息,减少了通信次数,所以不需要使用更多的通信次数传输相同的信息;
为什么使用通信来共享内存
『不要通过共享内存来通信,我们应该使用通信来共享内存』,这是一句使用 Go 语言编程的人经常能听到的观点
- 首先,使用发送消息来同步信息相比于直接使用共享内存和互斥锁是一种更高级的抽象,使用更高级的抽象能够为我们在程序设计上提供更好的封装,让程序的逻辑更加清晰;
- 其次,消息发送在解耦方面与共享内存相比也有一定优势,我们可以将线程的职责分成生产者和消费者,并通过消息传递的方式将它们解耦,不需要再依赖共享内存;
- 最后,Go 语言选择消息发送的方式,通过保证同一时间只有一个活跃的线程能够访问数据,能够从设计上天然地避免线程竞争和数据冲突的问题;
为什么 Redis 选择单线程模型
- 使用单线程模型能带来更好的可维护性,方便开发和调试;
- 使用单线程模型也能并发的处理客户端的请求;I/O 多路复用机制
- Redis 服务中运行的绝大多数操作的性能瓶颈都不是 CPU;
为什么 DNS 使用 UDP 协议
为什么 DNS 会使用 UDP 传输数据』以及『为什么 DNS 不止会使用 UDP 传输数据』两个问题
- DNS 在设计之初就在区域传输中引入了 TCP 协议,在查询中使用 UDP 协议;
- 当 DNS 超过了 512 字节的限制,我们第一次在 DNS 协议中明确了『当 DNS 查询被截断时,应该使用 TCP 协议进行重试』这一规范;
- 随后引入的 EDNS 机制允许我们使用 UDP 最多传输 4096 字节的数据,但是由于 MTU 的限制导致的数据分片以及丢失,使得这一特性不够可靠;
- 在最近的几年,我们重新规定了 DNS 应该同时支持 UDP 和 TCP 协议,TCP 协议也不再只是重试时的选择;
udp 与 mtu
当我们发送的UDP数据大于1472的时候会怎样呢? 这也就是说IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation). 把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组. 这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便 无法重组数据报.将导致丢弃整个UDP数据报。
因此,在普通的局域网环境下,我建议将UDP的数据控制在1472字节以下为好.
为什么需要无意义 id
因为 id 有实际意义会导致可用位变少
为什么 MySQL 使用 B+ 树
为什么 MongoDB 使用 B 树
为什么 TCP 协议有性能问题
- TCP 的拥塞控制算法会在丢包时主动降低吞吐量;
- TCP 的三次握手增加了数据传输的延迟和额外开销;
- TCP 的累计应答机制导致了数据段的传输;
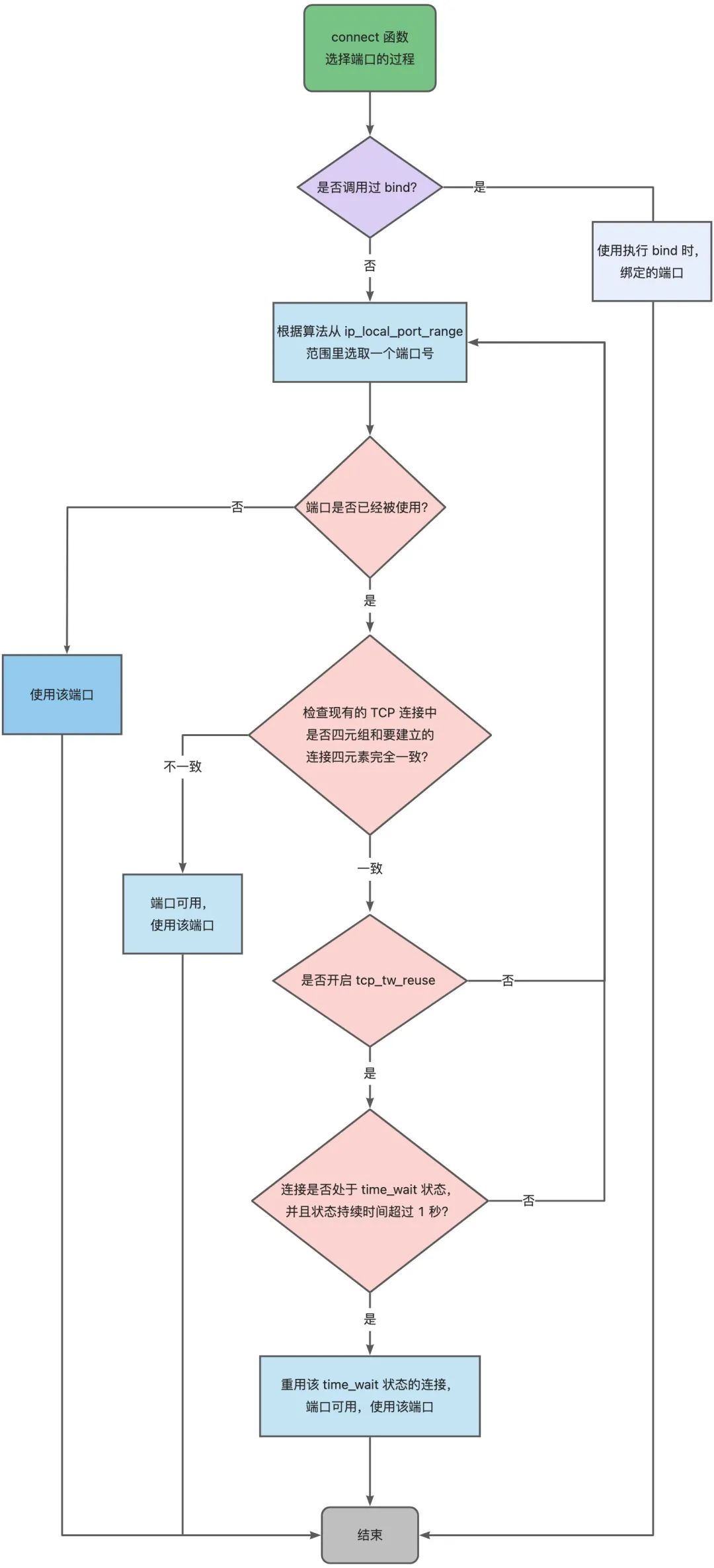
TCP 和 UDP 可以同时绑定相同的端口吗?
传输层有两个传输协议分别是 TCP 和 UDP,在内核中是两个完全独立的软件模块。
当主机收到数据包后,可以在 IP 包头的「协议号」字段知道该数据包是 TCP/UDP,所以可以根据这个信息确定送给哪个模块(TCP/UDP)处理,送给 TCP/UDP 模块的报文根据「端口号」确定送给哪个应用程序处理。
因此, TCP/UDP 各自的端口号也相互独立,如 TCP 有一个 80 号端口,UDP 也可以有一个 80 号端口,二者并不冲突。
两个 tcp 服务不能绑定同一个端口, 但是,因为只要客户端连接的服务器不同,端口资源可以重复使用的。
tcp 快启:
请求Fast Open Cookie
- 客户端发送SYN数据包,该数据包包含Fast Open选项,且该选项的Cookie为空,这表明客户端请求Fast Open Cookie;
- 支持TCP Fast Open的服务器生成Cookie,并将其置于SYN-ACK数据包中的Fast Open选项以发回客户端;
- 客户端收到SYN-ACK后,缓存Fast Open选项中的Cookie。
实施TCP Fast Open
以下描述假定客户端在此前的TCP连接中已完成请求Fast Open Cookie的过程并存有有效的Fast Open Cookie。
- 客户端发送SYN数据包,该数据包包含数据(对于非TFO的普通TCP握手过程,SYN数据包中不包含数据)以及此前记录的Cookie;
- 支持TCP Fast Open的服务器会对收到Cookie进行校验:如果Cookie有效,服务器将在SYN-ACK数据包中对SYN和数据进行确认(Acknowledgement),服务器随后将数据递送至相应的应用程序;否则,服务器将丢弃SYN数据包中包含的数据,且其随后发出的SYN-ACK数据包将仅确认(Acknowledgement)SYN的对应序列号;
- 如果服务器接受了SYN数据包中的数据,服务器可在握手完成之前发送数据;
- 客户端将发送ACK确认服务器发回的SYN以及数据,但如果客户端在初始的SYN数据包中发送的数据未被确认,则客户端将重新发送数据;
- 此后的TCP连接和非TFO的正常情况一致。
注:客户端在请求并存储了Fast Open Cookie之后,可以不断重复TCP Fast Open直至服务器认为Cookie无效(通常为过期)。[4]
为什么 TCP/IP 协议会拆分数据
- IP 协议会分片传输过大的数据包(Packet)避免物理设备的限制;
- TCP 协议会分段传输过大的数据段(Segment)保证传输的性能;
- IP 协议拆分数据是因为物理设备的限制,一次能够传输的数据由路径上 MTU 最小的设备决定,一旦 IP 协议传输的数据包超过 MTU 的限制就会发生分片,所以我们需要通过路径 MTU 发现获取传输路径上的 MTU 限制;
- TCP 协议拆分数据是为了保证传输的可靠性和顺序,作为可靠的传输协议,为了保证数据的传输顺序,它需要为每一个数据段增加包含序列号的 TCP 协议头,如果数据段大小超过了 IP 协议的 MTU 限制, 就会带来更多额外的重传和重组开销,影响性能。
一个IP数据报在以太网中传输,如果它的长度大于当前链路MTU值,就要进行分片传输(这里指IP层分片),使得每片数据报的长度都不超过MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络IP层完成的。
为什么 HTTPS 需要 7 次握手以及 9 倍时延
tls 过程
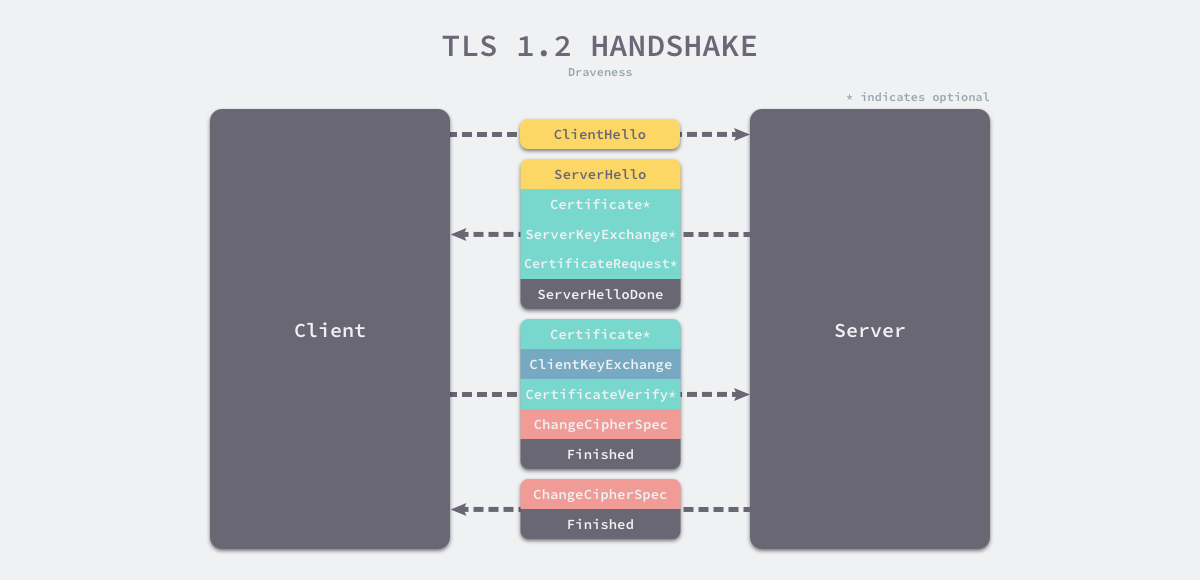
- 客户端向服务端发送 Client Hello 消息,其中携带客户端支持的协议版本、加密算法、压缩算法以及客户端生成的随机数;
- 服务端收到客户端支持的协议版本、加密算法等信息后;
- 向客户端发送 Server Hello 消息,并携带选择特定的协议版本、加密方法、会话 ID 以及服务端生成的随机数;
- 向客户端发送 Certificate 消息,即服务端的证书链,其中包含证书支持的域名、发行方和有效期等信息;
- 向客户端发送 Server Key Exchange 消息,传递公钥以及签名等信息;
- 向客户端发送可选的消息 CertificateRequest,验证客户端的证书;
- 向客户端发送 Server Hello Done 消息,通知服务端已经发送了全部的相关信息;
- 客户端收到服务端的协议版本、加密方法、会话 ID 以及证书等信息后,验证服务端的证书;
- 向服务端发送 Client Key Exchange 消息,包含使用服务端公钥加密后的随机字符串,即预主密钥(Pre Master Secret);
masterkey = PRF(pre_master_key, clienthello.random+serverhello_random)其中 prf 是一个算法 - 向服务端发送 Change Cipher Spec 消息,通知服务端后面的数据段会加密传输;
- 向服务端发送 Finished 消息,其中包含加密后的握手信息;
- 向服务端发送 Client Key Exchange 消息,包含使用服务端公钥加密后的随机字符串,即预主密钥(Pre Master Secret);
- 服务端收到 Change Cipher Spec 和 Finished 消息后;
- 向客户端发送 Change Cipher Spec 消息,通知客户端后面的数据段会加密传输;
- 向客户端发送 Finished 消息,验证客户端的 Finished 消息并完成 TLS 握手;
What is a Client Certificate?
Client certificates are, as the name indicates, used to identify a client or a user, authenticating the client to the server and establishing precisely who they are. To some, the mention of PKI or ‘Client Certificates’ may conjure up images of businesses protecting and completing their customers’ online transactions, yet such certificates are found throughout our daily lives, in any number of flavors; when we sign into a VPN, use a bank card at an ATM, or a card to gain access to a building or within public transport smart cards. These digital certificates are even found in petrol pumps, the robots on car assembly lines and even in our passports.
In Continental Europe and in many other countries, the use of client certificates is particularly widespread, with governments issuing ID cards that have multiple uses, such as to pay local taxes, electricity bills and for drivers’ licenses. And the reason why is simple—client certificates play a vital role in ensuring people are safe online.
https时延总结
- TCP 协议需要通过三次握手建立 TCP 连接保证通信的可靠性(1.5-RTT);
- TLS 协议会在 TCP 协议之上通过四次握手建立 TLS 连接保证通信的安全性(2-RTT);
- HTTP 协议会在 TCP 和 TLS 上通过一次往返发送请求并接收响应(1-RTT);
为什么 TCP 协议有粘包问题
- TCP 协议是面向字节流的协议,它可能会组合或者拆分应用层协议的数据;
- 应用层协议的没有定义消息的边界导致数据的接收方无法拼接数据;
如果我们能在应用层协议中定义消息的边界,那么无论 TCP 协议如何对应用层协议的数据包进程拆分和重组,接收方都能根据协议的规则恢复对应的消息。在应用层协议中,最常见的两种解决方案就是基于长度或者基于终结符(Delimiter)
为什么 TCP 协议有 TIME_WAIT 状态
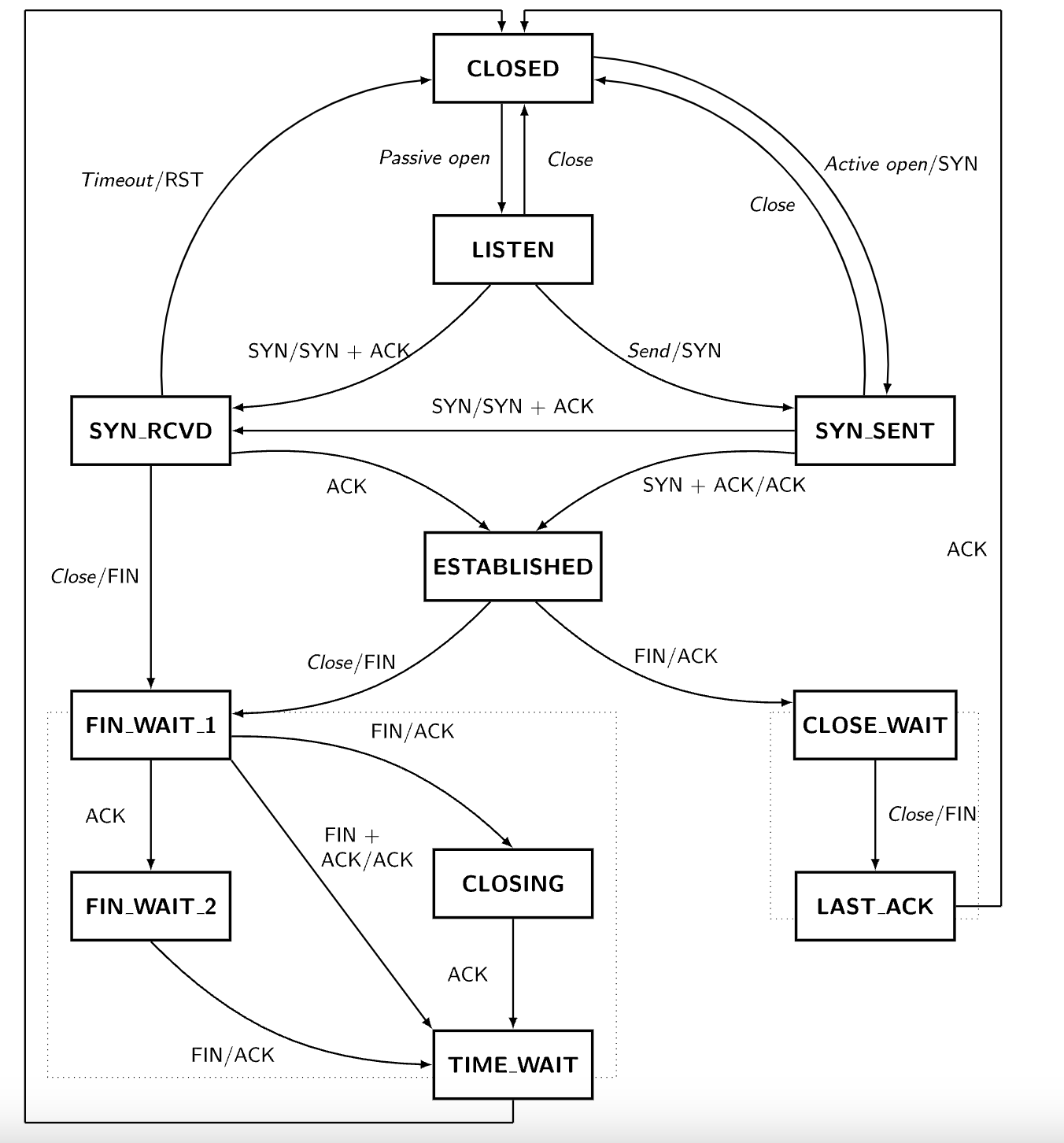
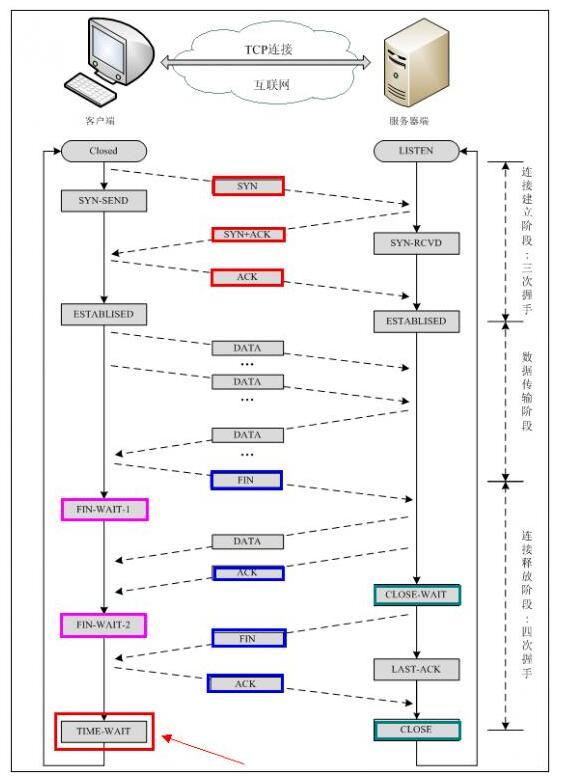
网络中可能存在来自发起方的数据段,当这些发起方的数据段被服务端处理后又会向客户端发送响应,所以一来一回需要等待 2 倍的时间。
数据库为什么不使用外键
假设我们的数据库中包含 posts(id, author_id, content) 和 authors(id, name) 两张表,在执行如下所示的操作时都会触发数据库对外键的检查:
- 向
posts表中插入数据时,检查author_id是否在authors表中存在; - 修改
posts表中的数据时,检查author_id是否在authors表中存在; - 删除
authors表中的数据时,检查posts中是否存在引用当前记录的外键;
想要在应用程序中模拟数据库外键的功能其实比较容易,我们只需要遵循以下的几个准则:
- 向表中插入数据或者修改表中的数据时,都应该执行额外的
SELECT语句确保它引用的数据在数据库中存在; - 在删除数据之前需要执行额外的
SELECT语句检查是否存在当前记录的引用;
外键提供的几种在更新和删除时的不同行为都可以帮助我们保证数据库中数据的一致性和引用合法性,但是外键的使用也需要数据库承担额外的开销,在大多数服务都可以水平扩容的今天,高并发场景中使用外键确实会影响服务的吞吐量上限。在数据库之外手动实现外键的功能是可能的,但是却会带来很多维护上的成本或者需要我们在数据一致性上做出一些妥协。我们可以从可用性、一致性几个方面分析使用外键、模拟外键以及不使用外键的差异:
- 不使用外键牺牲了数据库中数据的一致性,但是却能够减少数据库的负载;
- 模拟外键将一部分工作移到了数据库之外,我们可能需要放弃一部分一致性以获得更高的可用性,但是为了这部分可用性,我们会付出更多的研发与维护成本,也增加了与数据库之间的网络通信次数;
- 使用外键保证了数据库中数据的一致性,也将全部的计算任务全部交给了数据库;
为什么 Linux 需要 Swapping
Swap 分区是硬盘上的独立区域,该区域只会用于交换分区,其他的文件不能存储在该区域上,我们可以使用
swapon -s命令查看当前系统上的交换分区;Swap 文件是文件系统中的特殊文件,它与文件系统中的其他文件也没有太多的区别;
Swapping 可以直接将进程中使用相对较少的页面换出内存,立刻给正在执行的进程分配内存;
Swapping 可以将进程中的闲置页面换出内存,为其他进程未来使用内存做好准备;
当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。
- Swapping 可以直接将进程中使用相对较少的页面换出内存:当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性;
- Swapping 可以将进程中的闲置页面换出内存:应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程,我们可以将这部分只使用一次的内存交换到磁盘上为其他内存申请预留空间;
offer 北京: 20k 五险一金 时间: 周三;




