redis设计与实现读书笔记
数据结构
简单动态字符串 simple dynamic string SDS
除了字符串外还用做缓冲区, 二进制安全(api 以处理二进制的方式处理 buf 数组)
struct sdshdr{ |
空间预分配:
- 修改后 SDS<1MB, 分配 free=len, 且有额外一个字节保存空字符\0
- 修改后 SDS>=1MB, 分配 free=1MB
惰性空间释放: 修改只修改 free 而不释放空间
链表
双向链表有头尾结点, 有链表结点数量
字典
使用哈希表实现
typedef struct dict{ |
rehash:
- 扩容
- 如果是扩展操作, ht[1]大小为第一个 >= ht[0].used * 2 的 2 的 n 次方
- 如果是收缩操作, ht[1]大小为第一个 >= ht[0].used 的 2 的 n 次方
- 将 ht[0] 的键值对转移到 ht[1]
- 释放 ht[0], ht[1]取代 ht[0], 新建空白 ht[1]
扩容条件:
- 处于 BGSAVE 或 BGREWRITEAOF 命令中, 且哈希因子>=5
- 哈希因子>=1
收缩条件: 哈希因子<=0.1
跳跃表
是有序集合键和集群节点内部数据结构的实现
原理: 实际上是通过层, 实现了一种类似二分法的索引
比树更简单, 不需要调整平衡, 更局部
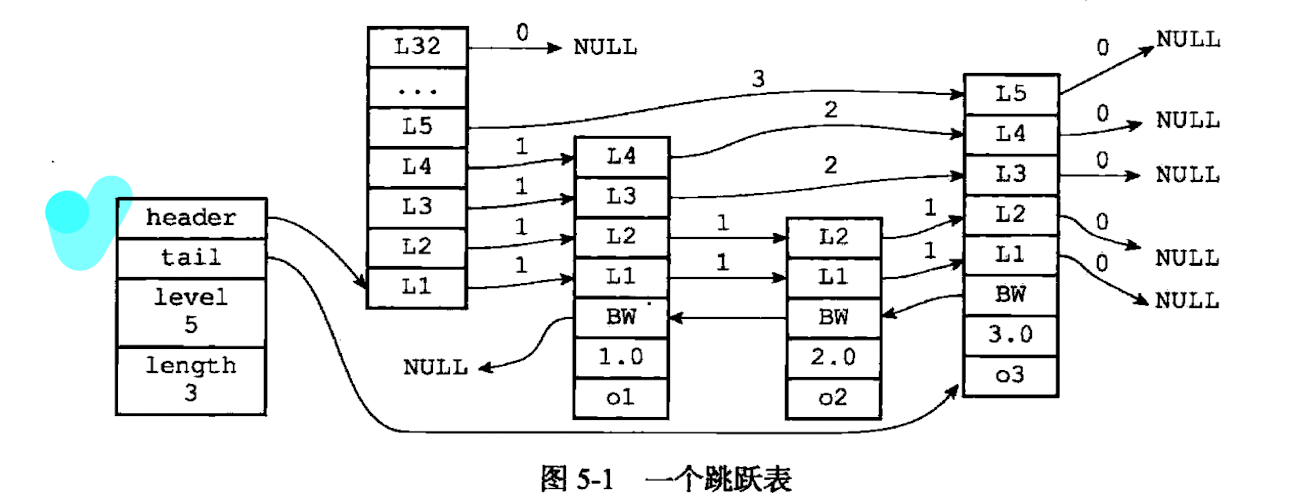
typedef struct zskiplistNode{ |
压缩链表
是列表键和哈希键的实现之一
减少了内存空间的使用, 连续空间顺序读写
typedef struct zlist{ |
连锁更新: 扩展(压缩)一个节点导致后续节点连续更新
对象
typedef struct redisObject{ |
embstr 是对段字符串的一种优化编码方式, 是只读的, 修改需要转换类型到 raw
- embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。
- 释放 embstr编码的字符串对象只需要调用一次内存释放函数,而释放 raw 编码的 字符串对象需要调用两次内存释放函数。
- 因为 embstr编码的字符串对象的所有数据都保存在一块连续的内存(即 void* ptr 紧跟在 object 后面)里面,所以这 种编码的字符串对多比起raw 编码的字符对象能的重好地利用缓存带来的优势
列表对象: 短的一般用 ziplist 实现, 如果
- 保存的字符串元素有长度超过 64 字节
- 或保存字符串元素超过512 个
改用 linkedlist 实现
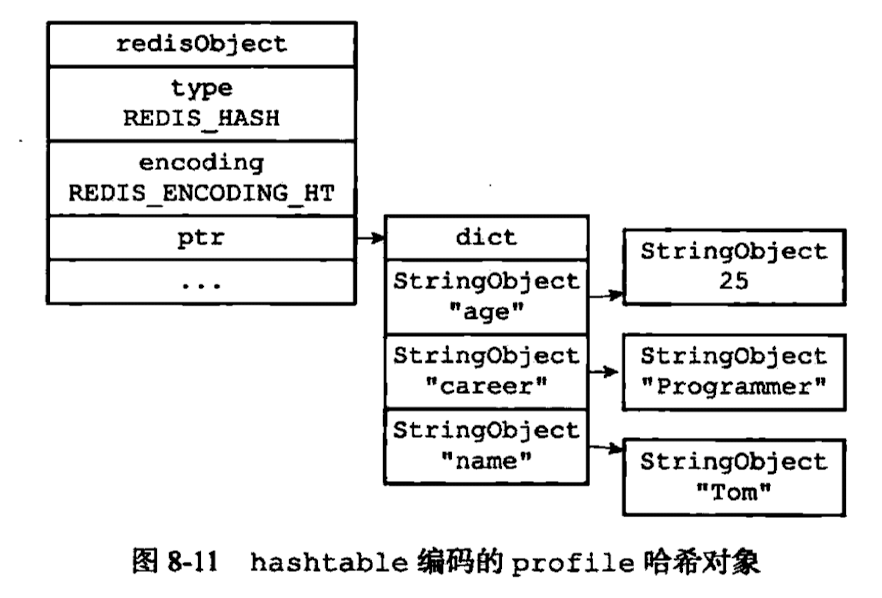
哈希对象
使用 zlist 实现的哈希对象:

当哈希对象较大时用 hashtable 实现
集合对象: 用 intset 或 hashtable(较大) 实现
有序集合: 用 ziplist 或 skiplist(较大) 实现
内存回收:
单机数据库
每个数据库有 expires 字典保存数据库中所有键的过期时间
删除过期键的方式: 惰性删除和定期删除结合 惰性删除: 读写前检查是否过期, 过期则删除 定期删除: 规定时间内分多次遍历数据库的 expires 字典, 从中随机检查一部分过期时间 过期的键: 生成 RDB 时会忽略, AOF 会增加 delete 命令
复制模式:
- 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个 DEL命令,告知从服务器删除这个过期键。
- 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键。
- 从服务器只有在接到主服务器发来的 DEL 命令之后,才会删除过期键。
这样保证由主服务器控制删除过期键, 保证一致性
RDB 文件 redis database
- SAVE 阻塞存储
- BGSAVE 开子进程存储
BGSAVE 自动间隔性保存 有数组记录保存的参数(间隔时间, 读写多少次就开始保存) 有 dirty 计数器记录进行了多少次修改 有 lastsave 记录上一次保存的时间戳
RDB 文件
 其中 database0 和 database3 分别存放对应数据库中的所有键值对 键值对的形式为: expiretime, type, key, value
其中 database0 和 database3 分别存放对应数据库中的所有键值对 键值对的形式为: expiretime, type, key, value
AOF append-only file
比 RDB 频率更高
过程
- 命令追加 执行写命令后追加 AOF
- 文件写入 服务器每结束一个时间循环前考虑是否要将 aof_buf 缓冲区的内容写入 AOF
- 文件同步
AOF 重写: 减小 AOF 文件大小
多机数据库
复制
从服务器 复制 主服务器
sync 命令非常消耗资源, 过程: 主服务器 BGSAVE 产生 RDB, 将 RDB 传给从服务器, 从服务器载入 RDB 并阻塞直至同步完成
- 完整重同步用于处理初次复制情况:完整重同步的执行步骤和SYNC命令的执行步骤基本一样,它们都是通过让主服务器创建并发送 RDB文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步。
- 而部分重同步则用于处理断线后重复制情况:当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。
复制偏移量: 保持主从服务器复制偏移量一致, 以用于检查从服务器是否同步
主服务器除了将命令发给从服务器, 还会另外发给 复制积压缓冲区, 其中还记录了每个命令的复制偏移量, 用于部分重同步
哨兵
单独的 redis 服务器, 监视主服务器状态, 如果下线寻找对应的从服务器替代, 将其升级为主服务器
集群
槽指派: 一共 2^14 个槽, 分给所有集群服务器, 必须每个槽都有服务器才能上线
每个服务器自己保存一个二进制数组记录自己管理的槽 每个服务器还保存一个数组记录每个槽都由哪个服务器管理
有两个数组记录的原因: 当程序需要将某个节点的槽指派信息通过消息发送给其他节点时,程序只需要 将相应节点的 clusterNode.slots 数组整个发送出去就可以了。 另一方面,如果Redis 不使用clusterNode.slots 数组,而单独使用clusterstate.slots 数组的话,那么每次要将节点A的槽指派信息传播给其他节点时,程序必须先遍历整个 clusterstate.slots 数组,记录节点A负责处理哪些槽,然后才能发送节点 A的槽指派信息,这比直接发送 clusterNode.slots数组要麻烦和低效得多。
计算键属于哪个槽: 将 key 的 crc16 校验和 & 2^14-1
独立功能的实现
watch 功能, 如果在 watch 的期间有别的服务器写了该数据, 则打开REDIS DIRTY CAS 标识
- 如果客户端的 REDIS DIRTYCAS 标识已经被打开,那么说明客户端所监视的键当中,至少有一个键已经被修改过了,在这种情况下,客户端提交的事务已经不再安全,所以服务器会拒绝执 行客户端提交的事务。
- 如果客户端的 REDIS_DIRTY_CAS 没有打开, 则事务安全可以执行




