计算机组成原理
组成原理
第1章 计算机系统概述
1.1 计算机发展历程
1.1.1 计算机硬件的发展
1.1.2 计算机软件的发展
1.2 计算机系统层次结构
1.2.1. 计算机系统的组成
计算机系统 = 硬件系统+软件系统
1.2.2 计算机硬件
冯诺依曼思想(存储程序)
采用存储程序的工作方式
存储程序思想: 将实现编制好的程序和原始数据送入主存后才能执行, 程序一旦启动无须人为干涉
计算机硬件系统包括: 运算器, 存储器, 控制器, 输入输出 五大部分
指令和数据以同等的地位存储在存储器中, 形式上无区别, 但计算机应能区分他们, 区分是根据指令阶段区分
指令和数据均由二进制表示
以运算单元为中心
存储器是按地址访问、线性编址的空间
控制流由指令流产生
指令由操作码和地址码组成
存储器:
- MAR 地址寄存器(memory address register), MDR 数据寄存器(memory data register) MAR 代表 PC 长度, 是虚拟memory地址空间的大小 MDR 代表存储字长, 即数据的位数
- 存储体包含存储单元, 存储单元包含存储元件 存储元件存储 1bit, 存储单元存储 1 存储字, 长度称为存储字长, byte 的2^n倍
运算器: 包含若干通用寄存器, 程序状态寄存器(PSW, Program Status Word)
控制器: 包括
- 程序计数器(PC Program Counter), 可自加 1(1 是一条指令的长度), 与主存的 MAR 有直接通路
- 指令寄存器(IR instruction register), 内容来自 MDR, 其内容中的操作码送往 CU, 地址送往 MAR
- 控制单元(CU control unit)
CPU总体结构
┌────┐ ┌────┐ ┌───┐ |
缓存结构
┌───────────┐ |
在CPU中至少要有六类寄存器:指令寄存器(IR)、程序计数器(PC)、地址寄存器(AR)、数据寄存器(DR)、累加寄存器(AC)、程序状态字寄存器(PSW)
数据寄存器 数据寄存器(Data Register,DR)又称数据缓冲寄存器,其主要功能是作为CPU和主存、外设之间信息传输的中转站,用以弥补CPU和主存、外设之间操作速度上的差异。
数据寄存器用来暂时存放由主存储器读出的一条指令或一个数据字;反之,当向主存存入一条指令或一个数据字时,也将它们暂时存放在数据寄存器中。数据寄存器的作用是 :
(1)作为CPU和主存、外围设备之间信息传送的中转站;
(2)弥补CPU和主存、外围设备之间在操作速度上的差异;
(3)在单累加器结构的运算器中,数据寄存器还可兼作操作数寄存器。
地址寄存器 地址寄存器(Address Register,AR)用来保存CPU当前所访问的主存单元的地址。
由于在主存和CPU之间存在操作速度上的差异,所以必须使用地址寄存器来暂时保存主存的地址信息,直到主存的存取操作完成为止。
当CPU和主存进行信息交换,即CPU向主存存入数据/指令或者从主存读出数据/指令时,都要使用地址寄存器和数据寄存器。
如果我们把外围设备与主存单元进行统一编址,那么,当CPU和外围设备交换信息时,我们同样要使用地址寄存器和数据寄存器。
程序状态字寄存器 程序状态字(Program Status Word,PSW)用来表征当前运算的状态及程序的工作方式。
程序状态字寄存器用来保存由算术/逻辑指令运行或测试的结果所建立起来的各种条件码内容,如运算结果进/借位标志(C)、运算结果溢出标志(O)、运算结果为零标志(Z)、运算结果为负标志(N)、运算结果符号标志(S)等,这些标志位通常用1位触发器来保存。
除此之外,程序状态字寄存器还用来保存中断和系统工作状态等信息,以便CPU和系统及时了解机器运行状态和程序运行状态。
因此,程序状态字寄存器是一个保存各种状态条件标志的寄存器。
指令寄存器 指令寄存器(Instruction Register,IR)用来保存当前正在执行的一条指令。
当执行一条指令时,首先把该指令从主存读取到数据寄存器中,然后再传送至指令寄存器。
指令包括操作码和地址码两个字段,为了执行指令,必须对操作码进行测试,识别出所要求的操作,指令译码器(Instruction Decoder,ID)就是完成这项工作的。指令译码器对指令寄存器的操作码部分进行译码,以产生指令所要求操作的控制电位,并将其送到微操作控制线路上,在时序部件定时信号的作用下,产生具体的操作控制信号。
指令寄存器中操作码字段的输出就是指令译码器的输入。操作码一经译码,即可向操作控制器发出具体操作的特定信号。
程序计数器 程序计数器(Program Counter,PC)用来指出下一条指令在主存储器中的地址。
在程序执行之前,首先必须将程序的首地址,即程序第一条指令所在主存单元的地址送入PC,因此PC的内容即是从主存提取的第一条指令的地址。
当执行指令时,CPU能自动递增PC的内容,使其始终保存将要执行的下一条指令的主存地址,为取下一条指令做好准备。
但是,当遇到转移指令时,下一条指令的地址将由转移指令的地址码字段来指定,而不是像通常的那样通过顺序递增PC的内容来取得。
因此,程序计数器的结构应当是具有寄存信息和计数两种功能的结构。
累加寄存器 累加寄存器通常简称累加器(Accumulator,AC),是一个通用寄存器。
累加器的功能是:当运算器的算术逻辑单元ALU执行算术或逻辑运算时,为ALU提供一个工作区,可以为ALU暂时保存一个操作数或运算结果。
显然,运算器中至少要有一个累加寄存器。
1.2.3 计算机软件
分为系统软件: OS, DBMS
和应用软件: 科学计算
翻译程序:
- 汇编程序: 汇编语言 -> 机器语言
- 解释程序: 源程序按顺序逐句翻译为机器指令并执行
- 编译程序: 高级语言 -> 汇编语言/机器语言
1.2.4 计算机系统的层次结构

1.2.5 计算机系统的工作原理
从源程序到可执行文件
flowchart TD; |
指令执行过程
- 取指令 PC->MAR->MM->MDR->IR 根据 PC 内容取指令存入 IR
- 分析指令 OP(IR) -> CU 分析 IR 中的 OP 产生控制信号
- 执行指令 Address(IR) -> MAR -> MM -> MDR -> ALU 根据 IR 中的地址取操作数传入 ALU
- (PC)+1 -> PC
1.3 计算机的性能指标
1.3.1 计算机的主要性能指标
字长(机器字长): 一次定点整数运算能处理的二进制数据的位数, 通常和 cpu 寄存器位数, 加法器有关 指令字长一般是存储字长的整数倍(多个存取周期)
数据通路带宽: 外部数据总线一次能传送的信息的位数, 与 cpu 内部数据总线宽度可能不同
主存容量: MAR 的长度反应存储单元的个数, MDR 的长度反应了存储字长
\(吞吐量 = \frac{处理请求数量}{时间}\) 主要与主存的存取周期有关
\(响应时间 = 收到响应结果时刻 - 发送请求时刻\)
CPI clock per instruction
\(CPU执行时间 = \frac{CPU 时钟周期数}{主频} = \frac{指令数量*CPI}{主频}\)
MIPS 106 instructions per second \(MIPS = \frac{指令数量}{执行时间*10^6} = \frac{主频}{CPI*10^6}\)
| 10n | 詞頭 | 記号 | 表記 |
|---|---|---|---|
| 1024 | yotta | Y | 一秭 |
| 1021 | zetta | Z | 十垓 |
| 1018 | exa | E | 百京 |
| 1015 | peta | P | 千兆 |
| 1012 | tera | T | 兆 |
| 109 | giga | G | 十億 |
| 106 | mega | M | 百萬 |
| 103 | kilo | k | 千 |
| 102 | hecto | h | 百 |
| 101 | deca,deka | da | 十 |
| 10 | 一 | ||
| 10−1 | deci | d | 十分之一 / 分 |
| 10−2 | centi | c | 百分之一 / 厘 |
| 10−3 | milli | m | 千分之一 / 毫 |
| 10−6 | micro | µ | 百万分之一 / 微 |
| 10−9 | nano | n | 十億分之一 / 奈 |
| 10−12 | pico | p | 一兆分之一 / 皮 |
| 10−15 | femto | f | 千兆分之一 / 飛 |
| 10−18 | atto | a | 百京分之一 |
| 10−21 | zepto | z | 十垓分之一 |
| 10−24 | yocto | y | 一秭分之一 |
1.3.2 几个专业术语
系列机: 有基本相同的体系结构(Computer Architecture) , 使用相同基本指令系统的不同计算机组成的产品系列
体系结构: 机器语言或汇编语言程序员能看到的传统机器的属性, 包括: 指令集, 数据类型, 存储器寻址技术等抽象属性
计算机组成: 如何实现体系结构所体现的属性, 对大部分程序员是透明的, 如: 如何执行指令周期, 如何实现乘法等
兼容:
- 向前兼容(向上兼容): 现在的版本对未来兼容 forward
- 向后兼容(向下兼容): 现在的版本对过去兼容 backward 软件一般向后兼容, 现在的机器可以使用老的软件 数据一般向前兼容, 新的数据可以被用在旧的系统中
固件: 程序固化在 ROM 中组成的部件称为固件
第2章 数据的表示和运算
2.1数制与编码
2.1.1 进位计数制及其相互转换
十进制转换为 r 进制:
- 整数部分: 除基数取余, 先得到的余数是低位
- 小数部分: 乘基数取整, 先得到的整数是高位
机器数: 计算机中将数据及其符号数字化, 常用的表示方法有: 原码, 补码, 反码
*2.1.2 BCD码 binary-coded decimal
- 8421 码: 进位+6 修正
- 余 3 码: 在 8421 码的基础上加 0011
- 2421 码
2.1.3 定点数的编码表示
通常用: 定点补码表示正数, 定点原码小数(纯小数, .xxxxx)表示浮点数尾数, 移码表示浮点数阶码
对于 n 位数, 原码范围: -(2n-1-1) ~ 2n-1-1 补码范围: -2n-1 ~ 2n-1-1 正数范围: 0~2n-1
原码: 最高位是符号位
补码: 纯小数(字长为 n+1, 整数部分 1, 小数部分 n)
\[[x]_补= \begin{cases} x,\quad &0\le x <1 \\ 2+x=2-|x|,\quad &-1 \le x <0 \end{cases} (mod2) \]
纯整数(字长为 n+1)
\[[x]_补= \begin{cases} 0, x,\quad &0\le x <2^n \\ 2^{n+1}+x=2^{n+1}-|x|,\quad &-2^n \le x <0 \end{cases} (mod2^{n+1}) \]
负真数->补码: 符号位取 1, 其余位取反末位+1
正真数->补码: 不变
负补码->真数: 各位取反末位+1
正补码->真数: 不变
对于负数, 不看符号位, 补码+原码应该进位
2.1.4 整数的表示
2.2 运算方法和运算电路
2.2.1 基本运算部件
一位全加器 FA
\(S_i = A_i \oplus B_i \oplus C_{i-1}\)
\(C_i = A_i B_i + (A_i \oplus B_i)C_{i-1}\)

串行进位加法器

并行进位加法器
令进位产生函数\(G_i = A_i B_i\), 进位传递函数\(P_i = A_i \oplus B_i\)
\(C_i = G_i+P_i C_{i-1}\)

带符号加法器

溢出\(OF = C_n \oplus C_{n-1}\)
符号\(SF = F_{n-1}\)
零标志 ZF = 1 当且仅当 F=0
进位/借位\(CF = C_{out} \oplus C_{in}\)
ALU

2.2.2 定点数的移位运算
算数移位: 对有符号数, 逻辑移位: 对无符号数
循环移位: 分为带进位位和不带进位位
2.2.3 定点数的加减运算
补码定点数加减电路

补码判断溢出的方法:
一位符号位 V=1 表示溢出 \(V=A_s B_s \overline S_s + \overline{A_s B_s}S_s\)
双符号位 V=1 表示溢出, 此时最高位为真正的符号
\(V=S_{s1}\oplus S_{s2}\)
一位符号位+进位情况 V=1 表示溢出
\(V=C_{s}\oplus C_{1}\), 其中 Cs为最高位进位
2.2.4 定点数的乘除运算
无符号数乘法电路

补码一位乘法(booth 乘法)

补码乘法电路

原码除法
补码除法

除法电路

2.2.5 C语言中的整数类型及类型转换
强制类型转换位值不变, 只改变解释方式
隐式转换优先级, 从下转换到上
long double |
2.2.6 数据的存储和排列
按照 byte 编址
大端: 高位在低地址
小端: 低位在低地址
边界对齐
2.2.7 汇编加减乘除
;自增自减 inc dec |
2.3 浮点数的表示与运算
2.3.1 浮点数的表示
\(N=(-1)^S * M * R^E\)
浮点数的规格化: 调整尾数和阶码, 使得尾数的最高位上是有效值
IEEE 754 标准
偏置值: 2E-1-1 = 127 或 1023 尾数: 1.xxxx , 1 隐藏可以多表示 1 位
32 位浮点数
0 1 9 32 |
64 位浮点数
0 1 12 64 |
80 位浮点数
0 1 16 80 |
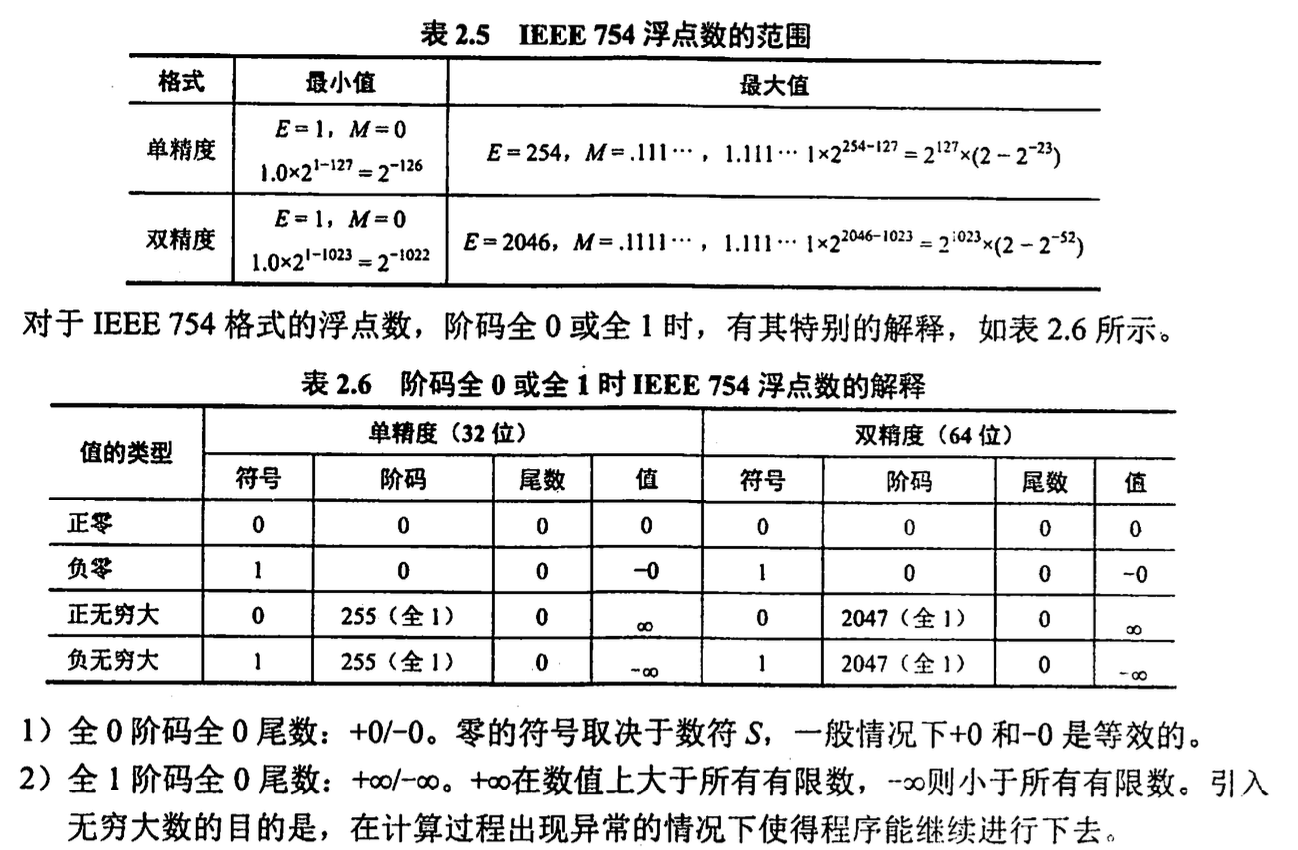
例如:178.125 |
2.3.2 浮点数的加减运算
- 对阶, 小阶向大阶看齐
- 尾数求和
- 规格化 左规(尾数左移1位,阶码减1)右规(尾数右移1位,阶码加1)
- 舍入: 将右移移出的保留两位参与计算
- 0 舍 1 入
- 恒置 1
- 溢出判断, 判断阶数是否溢出
舍入方式
1、就近舍入: 即十进制下的四舍五入。但是也会出现以下几种情况: 多余数字是1001,它大于0.5,故最低位进1。 多余数字是0111,它小于0.5,则直接舍掉多余数字。 多余数字是1000,正好是等于0.5的特殊情况;那么此时最低位为0则舍掉多余位,最低位为1则进位1。 注意这里说明的数位都是指二进制数。因为这是尾数,所以在计算这些二进制和0.5的关系的时候,也即转为10进制的时候,我们用每一位的权重乘以2^(-i)然后求和即可。
2、朝0舍入:即朝数轴零点方向舍入,所以我们直接截尾即可。
3、朝正无穷舍入:对正数而言,多余位全为0则直接截尾,不全为0则向最低有效位进1;负数的话不管多余位是多少直接截尾即可。
4、朝负无穷舍入:对负数而言,多余位全为0则直接截尾,不全为0则向最低有效位进1;正数的话不管多余位是多少直接截尾即可。
第3章 存储系统
3.1 存储器概述
3.1.1 存储器的分类
按作用(层次)
- 主存 main memory
- 辅助存储器(外存)
- Cache
按存储介质
磁表面存储器(磁盘磁带), 磁芯存储器, 半导体存储器, 光存储器(光盘)
按存取方式
- RAM: 随机存取
- ROM: 现代 ROM 有些也可以重复读写, 也为随机读写, 保留了断电内容保留的特点, 写比读要慢很多
- 串行访问存储器: 按物理位置的先后顺序寻址, 如磁带, 磁盘, 光盘
3.1.2 存储器的性能指标
存储容量(存储字数*字长), 单位成本(总成本/总容量) 存储速度:
- 数据传输率 = 数据宽度/存取周期
- 存取时间 Ta 从启动一次存储器操作到完成操作所用的时间, 分为读出时间和写入时间
- 存取周期(读写周期, 访问周期) Tm 存储器进行一次完整的读写操作所需的全部时间, 也是两次独立访问存储器操作之间所需的最小时间间隔
- 主存带宽 Bm 也叫数据传输率, 表示每秒从主存进出信息的最大数量
通常存取周期 > 存取时间, 因为存储器在读写操作之后有一段复原时间, 特别是对破坏性读出的存储器
3.1.3 多级层次的存储系统
3.2 主存储器
3.2.1 SRAM 芯片和 DRAM 芯片
| 特性 | SRAM | DRAM |
|---|---|---|
| 读取 | 非破坏性 | 破坏性 |
| 优点 | 存取快 | 易集成, 价格低, 功耗低 |
| 缺点 | 集成度低, 功耗大, 价格贵 | 存取慢 |
| 原理 | MOS 管 | 电容 |
| 刷新 | no | yes |
| 送行列地址 | 同时 | 分两次 |
DRAM 刷新: 一个刷新周期中有许多存取周期
- 集中刷新: 每个刷新周期内用固定时间对所有行逐行刷新, 此期间存储器停止读写操作, 称为死时间
- 分散刷新: 每个存取周期中增加刷新(如刷新其中一行), 没有了死时间, 但是增加了存取周期
- 异步刷新: 两次刷新操作的时间间隔\(t = \frac{刷新周期}{行数}\) 每隔时间 t 产生一次刷新请求, 刷新其中的一行, 即每次刷新只有一行处于死时间
DRAM 刷新对 CPU 透明, 刷新单位是行, 刷新不需要选片, 所有芯片同时刷新
存储器芯片结构
- 存储体(存储矩阵): 通过行选择线 X 列选择线 Y 选择访问单元
- 地址译码器: 将地址转换为译码输出线上的电平驱动读写电路
- IO 控制电路: 控制被选中的单元的读写, 具有放大信息的作用
- 片选控制信号: 选中芯片
- 读写控制信号
3.2.2 只读存储器
特点:
- 结构简单, 位密度比可读写存储器高
- 非易失性
ROM 类型
- 掩模式只读存储器 MROM 写入后人和人无法改变其内容, 由半导体制造商写入, 便宜但灵活性差
- 一次可编程只读存储器 PROM 允许用户用专门的设备写入程序, 一旦写入就无法改变
- 可擦除可编程只读存储器 EPROM 可以用编程器写入并且可以多次改写, 但编程次数有限且写入时间长(不能代替 RAM)
- 电子式可擦除可编程只读存储 EEPROM 写入更简单
- FLASH 存储器 闪存 既可以在不加电情况下长期保存信息, 又可以在线快速擦除和重写, 兼具 EPROM 和 EEPROM 优点
- 固态硬盘 SSD 保留了 Flash 的特性, 比传统硬盘读写速度快, 功耗低, 但价格高
3.2.3 主存储器 MM 的基本组成
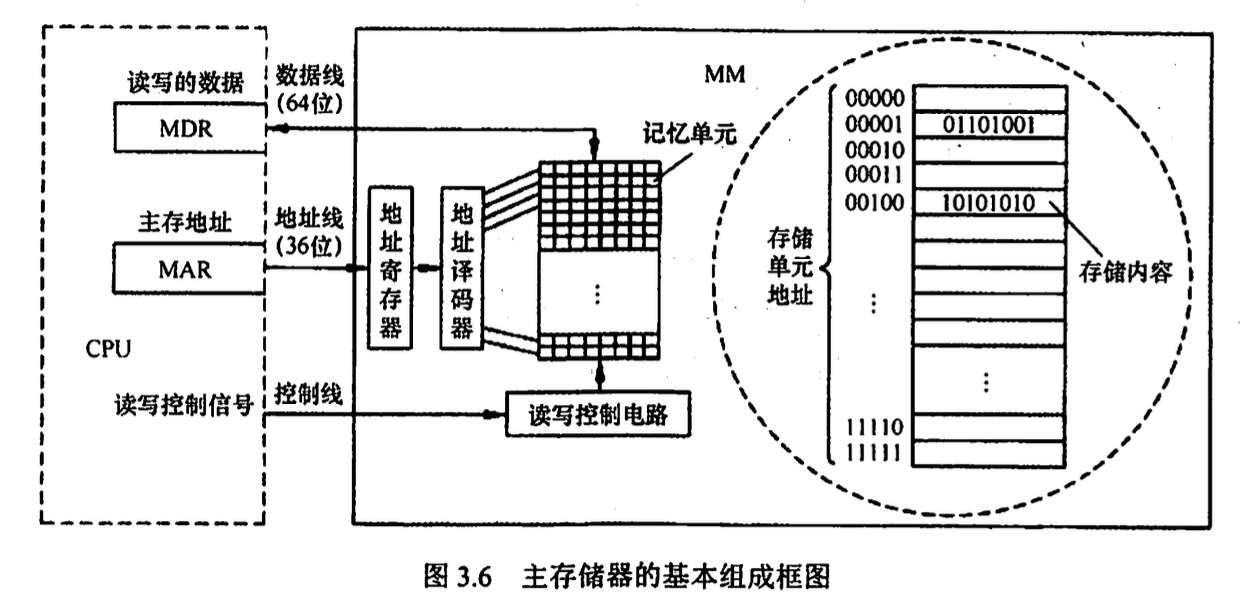
地址引脚复用: 行地址和列地址通过相同引脚先后两次输入
3.2.4 多模块存储器
多个存储模块并行工作
- 单体多字存储器 一个存储体, 每个存储单元存 m 个字, 总线宽度为 m 个字, 一次并行读出 m 个字 提高了存取效率, 但当指令数据不是连续存放时效果不明显
- 多体并行存储器
- 高位交叉编址(顺序方式) 高位地址表示体号, 低位地址表示体内地址, 这种方式仍是串行存取, 顺序存储器
- 低位交叉编址(交叉方式) 低位地址表示体号, 高位地址表示体内地址, 这种方式是并行存取 设字长=数据总线宽度, 一个字的存取周期=T, 总线传送周期=r, 为实现流水线, 应满足\(m=\frac T r\) m 称为交叉存取度, 模块数应>=m, 连续存取 m 个字需要的时间为 \(t_1 = T +(m-1)r\)
3.3 主存储器与 CPU 的连接
3.3.1 连接原理
- MM 通过数据总线, 地址总线, 控制总线与 CPU 连接
- 数据总线的位数 * 工作频率 = k * 数据传输率
- 地址总线位数决定寻址最大内存空间
- 控制总线指出总线周期的类型和本次输入输出操作完成的时刻
3.3.2 主存容量的扩展
位扩展 CPU数据线数 > 存储芯片数据位数, 此时增加存储字长, 片选信号\(\overline{CS}\)要连接到所有芯片

字扩展 增加存储器中字的数量, 字长不变
将地址的一部分(如高位)作为片选信号

字位同时扩展

3.3.3 存储芯片的地址分配和片选
先片选再片内字选, 片选的方法有
- 线选法 用片内字选之外的高位地址线直接接到存储芯片的片选端(0 代表有效?) 不需要地址译码器, 线路简单 但是地址空间不连续, 选片地址线必须分时为低电平(不能同时有效), 没有充分利用存储器空间(高几位相当于没有了)
- 译码片选 用片内字选意外的高位地址线通过地址译码器产生片选信号
3.3.4 存储器与 CPU 的连接
- 选择 ROM 还是 RAM, 芯片的数量
- 地址线连接(片选)
- 数据线连接(扩位)
- 读写命令线, 通常高电平读低电平写
- 片选线
3.4 外部存储器.
3.4.1 磁盘存储器
容量大, 成本低, 可反复使用, 可长期保存, 非破坏性读出, 但存取速度慢, 机械结构复杂
磁盘存储器
磁盘设备的组成:
- 硬盘存储器的组成:
- 磁盘驱动器: 磁头组件和盘片组件
- 磁盘控制器: 硬盘存储器和主机的接口, 标准有 IDE, SCSI, SATA
- 盘片
- 存储区域 一块硬盘有若干记录面, 记录面划分为若干磁道, 磁道划分若干扇区(块 block), 扇区是磁盘读写最小单位
- 磁头数: 即记录面数
- 柱面数: 即磁道数, 不同记录面的相同位置的磁道组成柱面
- 扇区数: 每个磁道上有多少扇区
磁记录原理: 磁头和磁性记录介质相对运动, 通过电磁转换完成读写
磁盘性能指标:
- 记录密度: 单位面积上记录的二进制信息量
- 道密度: 磁盘半径方向单位长度的磁道数
- 位密度: 磁道单位长度能记录的二进制数据位数
- 面密度: 道密度 * 位密度
- 磁盘容量
- 非格式化容量: 磁盘记录表面可利用的磁化单元总数, 由道密度和位密度计算
- 格式化容量: 安装某种特点的记录格式所能存储信息的总量, 一般小于非格式化容量
- 平均存取时间: = 寻道时间(磁头找到目的磁道) + 旋转延迟时间(磁头找到目的扇区, 转半圈) + 传输时间(传输数据, 一般一个扇区, 即每转时间/每个磁道的扇区数)
- 寻找时间 \(T_s = m*n+s\) m为磁盘驱动器速度常数, n 为跨越的磁道数, s 为启动磁臂时间
- 旋转延迟时间 \(T_r = \frac 1 {2r}\) r为磁盘旋转速度, (即转半圈需要的时间)
- 传输时间 \(T_t = \frac{b}{rN}\) b为读写字节数, r 为磁盘转速, N 为同一个磁道上的字节数
- 数据传输率: 设磁盘转速 r 转/秒, 每条磁道容量 N byte, 则数据传输率 Dr = rN
磁盘地址 主机向磁盘控制器发送地址 扇区地址可以划分为: 驱动器号, 柱面(磁道)号, 盘面号, 扇区号
硬盘工作流程: 寻址, 读盘, 写盘; 每个操作对应一个控制字 硬盘的读写是串行的, 不能同时读写, 也不能同时读(写)多组数据
磁盘调度算法(针对磁道, 磁道是从 1~N~1 是一个来回)
- FCFS
- 最短寻找时间优先 SSTF (shortest seek time first) 可能饥饿
- 扫描算法 SCAN(电梯调度算法) 在当前移动方向上选择最近的进行服务
- 循环扫描 C-SCAN 返回时移动至起始端而不进行任何服务
- look 调度, 在扫描算法基础上, 不严格从磁盘的一端到另一端, 而是到达最远请求即可
磁盘阵列
- raid0: 无冗余无校验, 并行访问
- raid1: 镜像
- raid2: 有纠错的海明码阵列
- raid3: 位交叉奇偶校验
- raid4: 块交叉奇偶校验
- raid5: 无独立校验的奇偶校验, 恢复码分散到所有磁盘中
3.4.2 固态硬盘 SSD
以 page 为单位读写, 只有在 page所在的 block 全部擦除后才能对这个 page 写

磨损均衡:
- 动态磨损均衡: 写入数据时自动选择较新的闪存块
- 静态磨损均衡: 无数据写入时也会进行数据分配, 让老闪存块承担无需写的存储任务
3.5 高速缓冲存储器
3.5.1 程序访问的局部性原理
时间, 空间局部性
3.5.2 Cache 的基本工作原理
基本单位: cache 和主存都被划分成相等的块, cache 中的块又叫 cache 行, 由若干 byte 组成
cache line -> memory block
cache line 缺失时, 从主存读取数据到 cache line 再访问 cacheline, 即访问两次, 缺页同理访问两次
3.5.3 Cache 和主存的映射方式
地址映射
直接映射 主存的每一block 只能装入 cache 的唯一 line, 如果冲突就直接替换(无需替换算法) cache_line_number = MM_block_number mod cache_line_count 地址结构:
address in MM
─────────────────────────────────────►
────► ────────────────► ─────────────► ─►
tag cache_line_number address_in_line valid全相联映射 每一块可以装入 cache 中的任何位置, cpu 访问 cache 时需要对所有 cache line 比较
address in MM
───────────────────►
────► ─────────────► ─►
tag address_in_line valid组相联映射 cache 分为若干组, 每个内存 block 可以存入固定组中的任意一行, 即组间直接映射, 组内全相联映射, 每组有 r 行, 称为 r 路组相联 例如1000 行 2 路组相联, 即 500 组每组 2 行, 2 行是全相联
address in MM
────────────────────────────────────────►
────► ───────────────────► ─────────────► ─►
tag cache_group_number address_in_line valid
─────────────────────────►
MM_block_number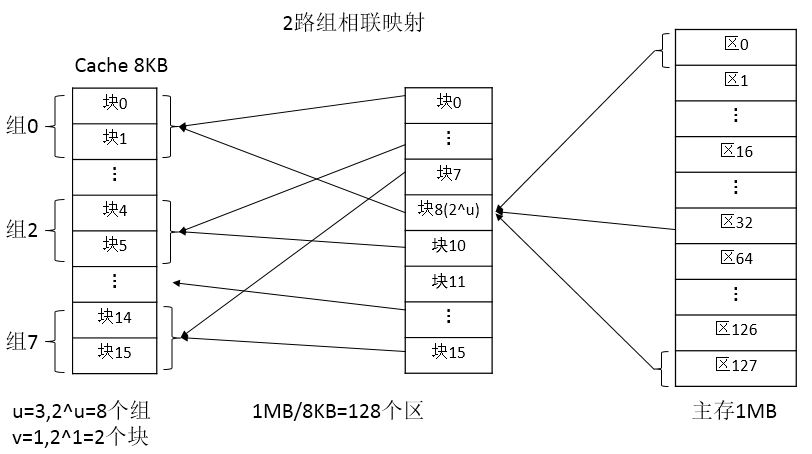
使用哪种存疑
3.5.4 Cache 中主存块的替换算法
- 随机算法
- FIFO 算法
- 近期最少用算法(LRU) 为每个 cache line 设置计数器, 计数器位数 = r 组相联路数 步骤:
- 命中时, 计数值比其低的line 的计数器+1, 其余不变, 所在 line 计数器=0,
- 未命中但还有空闲 line 时, 新装 line 的计数器=0, 其余+1
- 未命中且无空闲line 时, 计数值为 2r-1 的块被淘汰, 计数值=0, 其余计数值+1
- 最不经常用算法 LFU 每行设置一个计数器, 新建行计数器=0, 每访问一次计数器+1, 需要替换时将计数值最小行换出
3.5.5 Cache 写策略
写命中
- 全写法 write through 当 cpu 对 cache 写命中时, 必须把数据同时写入 cache 和 MM
- 写缓冲: 在 cache 和 MM 之间增加写缓冲, cpu 同时将数据写入 cache 和写缓冲中, 写缓冲再控制将内容写入 MM 写缓冲是一个 FIFO 队列
- 回写法 write back 当 cpu 对 cache 写命中时, 只写入 cache, 只有当此 line 被换出时才写入 MM
- 需要增加修改位(脏位, dirty bit, 1 代表修改过)
写不命中
- 写分配法 write allocate + 回写 加载MM 中的块到 cache(利用空间局部性), 然后更新这个 cache line 这样每次写不命中都要访存
- 非写分配法 non-write allocate +全写 只写入MM 不进行调块
3.6 虚拟存储器
主存+辅存, 对应用程序透明
即, 主存作为辅存的 cache
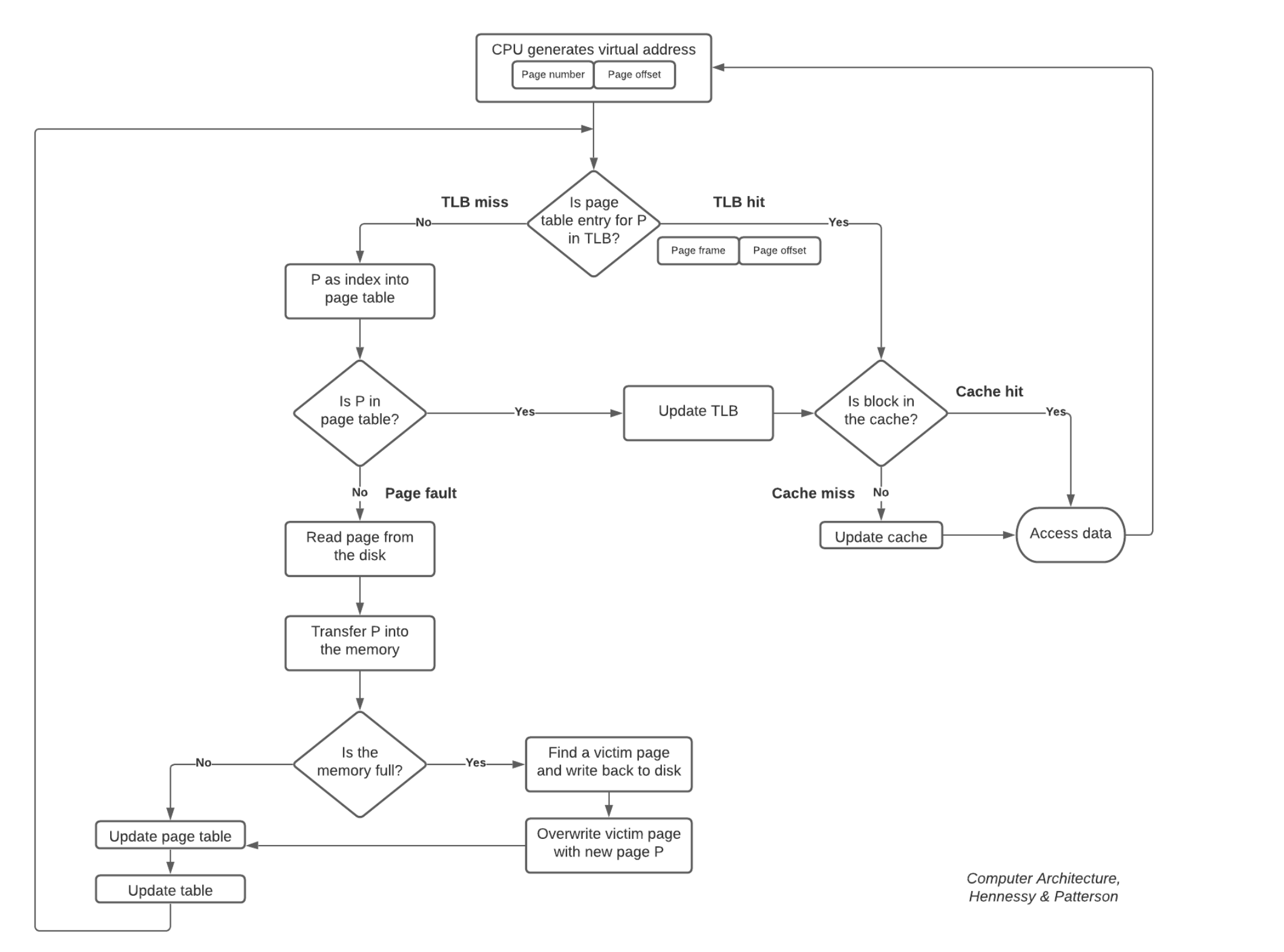
3.6.1 虚拟存储器的基本概念
将主存或辅存的地址空间统一编址
全相联映射, 回写法
cpu 使用虚拟地址时, 通过辅助硬件找出虚拟地址与实地址之间的对应关系, 如果已经在主存中就直接访问, 如果不在就将该字所在的 page(segment) 调入 MM 后再由 cpu 访问
3.6.2 页式虚拟存储器
以 page 为基本单位, 虚拟空间和主存空间都被划分成同样大小的page MM 的 page叫做实页, 页框; 虚拟空间的 page 叫做虚页 虚拟地址划分为字段: 虚页号, 页内地址
virtual address |
虚拟地址到物理地址的转换由页表实现, 页表记录虚页调入 MM 被安排的主存位置, 页表一般长久的保存在 MM 中
页表 page table entry in page table
key=virtual_page_number, valid_bit, dirty_bit, ref_bit, physical_page_addressvalid_bit 有效位: 1 代表在内存中 dirty_bit: 回写法脏位 ref_bit: 引用位, 用于替换策略的计数器 页表基址寄存器存放进程的页表首地址, 根据页表: 将虚拟页号映射到物理页号, 再通过一样的页内地址找到物理地址vaddr = vpage_num + offset_in_page = ppage_num + offset_in_page快表 TLB (translation lookaside buffer) 一般由 SRAM 构成, TLB也是 cache 的一种 把经常访问的页表项存储在 TLB 中, TLB 是由高速缓冲组成的, 每个 cpu 有自己的 tlb(专门用于页表的高速缓存) TLB 通常采用全相联或组相联 注意: 不同的进程的虚拟地址会对应不同的物理地址, 也就是说在进程切换时 tlb 需要 flush(全部失效), 里面有机制识别进程 id 或者是否是内核空间不需要 flush
virtual_address_number
─────────────────────────►
────► ───────────────────► ─────────────►
tag cache_group_number page_table_record有 TLB 和 cache 的多级存储系统 查找时, TLB 和 page table 可以同时查找取较快的那一个的结果 此时一次虚拟地址数据的查找可能会有:
- 访存 1: 可能访问 MM 中的页表
- 访外存: 页表不在主存内(缺页异常)
- 访存 2: cache 不命中
3.6.3 段式虚拟存储器
segment 是按照程序的逻辑结构划分的, 各个 segment长度因程序而异
virtual address |
vaddr->paddr 由段表实现 entry in segment table key=segment_number, valid_bit(1代表已装入主存), segment_begin_physical_addr, segment_length
vaddr = segment_num + offset_in_segment = segment_begin_physical_addr + offset_in_segment
段表基址寄存器
3.6.4 段页式虚拟存储器
把程序按逻辑结构划分成 segment, 每个 segment 划分成 page
每个程序对应一个 segment table, 每个 segment 对应一个 page table, segment 长度是 page 的整数倍, segment 起点是 page 的起点 virtual address
──────────────────────────────────►
───────────► ───────► ────────────►
segment_num page_num address_in_page
先根据段表寄存器得到段表基址, 根据段号得到页表基址, 根据页号得到实页号, 根据页内地址得到物理地址
但是需要两次查表
3.6.5 虚拟存储器与 Cache 的比较
第4章指令系统
4.1 指令系统
指令系统是 ISA 最核心的部分
指令集体系结构 ISA(Instruction set architecture), 完整定义了软件和硬件之间的接口, 规定的内容主要包括: 指令格式, 数据类型和及格式, 操作数存放方式, 程序可访问寄存器, 存储空间大小和编址, 寻址方式, 指令执行过程的控制方式等.
4.1.1 指令的基本格式
instruction |
指令长度和机器字长无固定关系, 但一般为机器字长整数倍, 如: 单字长指令, 半字长指令, 双字长指令
按指令长度, 指令系统可分为定长指令系统, 变长指令系统
按操作数地址码数量可分为:
OP, a1, a2, a3, a4
零地址指令 通常操作数隐含与栈中, 结果再压入栈
一地址指令
OP(a1) -> a1
(ACC)OP(a1) -> ACC, 另一个操作数由 acc 累加器提供
二地址指令 (a1)OP(a2) -> a1
三地址指令 (a1)OP(a2) -> a3
四地址指令 (a1)OP(a2) -> a3, a4 为下一条要执行的指令地址
4.1.2 定长操作码指令格式
最高若干位(定长)为操作码 当计算机字长>=32 时这是常规方法
4.1.3 扩展操作码指令格式
指令字长一定, 操作码的长度可变
要注意: 不允许短码是长码的前缀, 操作码不能重复, 使用频率高的指令用短码
4.1.4 指令的操作类型
4.2 指令的寻址方式
形式地址 A, 有效地址 EA, 地址为 A 的地址的数值(A)
4.2.1.指令寻址和数据寻址
- 指令寻址: 寻找下一条要执行的指令的地址
- 顺序寻址: PC+1
- 跳跃寻址
- 数据寻址: 操作数的地址 指令=
操作码, 寻址特征, 形式地址 A
4.2.2 常见的数据寻址方式
- 隐含地址: 如零地址指令, 但是需要增加硬件配合隐含的操作数地址
- 立即数寻址 地址字段不是操作数地址而是操作数本身, 采用补码表示, 取操作数不需要访问主存
- 直接寻址 EA = A, 只需要一次访存, 但是 A 的位数限制了寻址范围
- 间接寻址 EA = (A), key 扩大寻址范围, 但是需要2次访存(多次间接寻址需要更多次访存)
- 寄存器寻址 EA = R, 操作数在寄存器 R 中, 不需要访存
- 寄存器间接寻址 EA = (R), 操作数地址在寄存器 R 中, 需要一次访存
- 相对寻址 EA = (PC)+A, 操作数地址由 PC 的值和 A 共同决定, 多用于转移指令 对于
jmp A, 若此时 pc=x, 则执行后pc = x+A+1 - 基址寻址 EA = (BR) + A, BR 是基址寄存器, 基址寄存器是面向操作系统的(如页表段表基址?), BR 中的值不变
- 变址寻址 EA = (IX)+A, IX 为变址寄存器, 变址寄存器是面向用户的, A 的值不变, 多用于循环
- 堆栈寻址 堆栈的读写单元地址由特定寄存器 SP 提供 (硬堆栈: 由寄存器组成, 软堆栈: 由内存的一部分组成) 如零地址指令
4.3 程序的机器级代码表示
4.3.1 常用汇编指令介绍
| 项目 | Intel风格(dosbox使用的是这种) | AT&T风格 |
|---|---|---|
| 操作数顺序 | 目标操作数在前 | 源操作数在前 |
| 寄存器 | 原样 | 加%前缀 |
| 立即数 | 原样 | 加$前缀 |
| 16进制立即数 | 用后缀B与H分别表示二进制与十六进制 对于16进制字母开头的要加前缀0 | 加前缀0x |
| 访问内存长度的表示 | 前缀BYTE PTR, WORD PTR, DWORD PTR和QWORD PTR表示字节,字,双字和四字 | 后缀b,w,l,q表示字节,字,双字和四字 |
| 引用全局或静态变量var的值 | [var] | var |
| 引用全局或静态变量var的地址 | var | $var |
| 引用局部变量 | 需要基于栈指针(rsp) | |
| 绝对寻址 | [imm] | imm |
| 间接寻址 | [reg] | (%reg) |
| 基址相对寻址 | [reg +imm] | imm(%reg) |
| 变址寻址 | [base+index] | (base,index) |
| 变址寻址 | imm[base+index] | imm(base,index) |
| 比例变址寻址 | imm[base + index * scale ] | imm(base, index, scale) |
| scale只能是1,2,4,8其中的一个数字(1省略不写就是普通变址寻址) | ||
| 代码注释 | 单行注释用;+注释内容。例如:mov rax, rdx ;这里是注释 | |
| 注意 | 这里imm为立即数,base和index为寄存器,scale为伸缩量 |
4.3.2 过程调用的机器级表示
执行步骤: 假设 caller 调用 called
- caller 将参数放在 called 能访问的地方
- caller 将返回地址放在特定的地方, 控制转移给 called //call
- called 保存 caller 现场, 为自己的非静态局部变量分配空间
- 执行 called
- called 恢复 caller 现场, 将结果放在 caller 能访问的地方, 释放局部变量
- called 取出返回地址, 控制转移给 caller //ret
4.3.3 选择语句的机器级表示
标志位:(标志寄存器)
zf: 零标志位, 相关指令执行后结果为 0 则 zf=1, 否则 0 mov ax,1 sub ax,1
pf: 奇偶标志位, 结果中 1 为偶数 pf=1, 否则 0
sf: 符号标志位, 结果为负, sf=1, 否则为 0, 无符号数计算 sf 恒等于 0
cf: 进位标志位, 在进行无符号数运算的时候,CF记录了运算结果的最高有效位向更高有效位向更高位的进位值/借位值,产生进位或向更高位借位都会使CF=1
加法 A+B: 进位输出为1,则CF标志位为1,反之则为0 减法 A-B:[A]补+[-B]补:进位输出为1,则CF标志位为0,反之则为1(与加法相反) a 补 +(- b)补 原式化作 a-b+2^n; 此时再考察运算结果,不难发现,如果进位输出C_out为1,则表示该结果大于等于 2^n,即 a-b+2^n >= 2^n,则 a-b >= 0,计算时无需借位,借位标志 CF 为0。反之,当进位输出为0时,计算结果小于 2^n,a-b < 0,计算时需要借位,借位标志 CF 为 1
of: 溢出标志位, 有符号运算结果太大或太小 of=1, 否则 0
cmp, test分别相当于sub, add, 但是不会改变其他寄存器而 只改变标志位
4.3.4 循环语句的机器级表示
4.4 CISC 和RISC 的基本概念
4.4.1 复杂指令系统计算机 (CISC)
特点
- 指令数目多(>200)
- 指令长度不固定, 格式多, 寻址方法多
- 可以访存的指令不受限制
- 指令使用频率相差大
- 指令执行时间相差大, 大多数指令需要多个时钟周期
- 控制器多采用微程序控制
- 难以优化编译
4.4.2 精简指令系统计算机 (RISC)
特点:
复杂指令由简单指令的组合实现
指令长度固定, 格式少, 寻址方式少
只有 load/store 指令访存, 其他指令都在寄存器之间进行
cpu 中通用寄存器数量多
到底有多少个寄存器,和编译时的寄存器分配关系很大——寄存器太少的话,就要经常把寄存器上的内容倒腾到内存里去,这一来一回用时实在是太大了;寄存器太多的话,根本用不完,白白花了材料钱和制作费。Patterson在他的《计算机体系结构:量化研究方法》这本教材里给出了一个寄存器数目的效用曲线,寄存器数目在16-32个之间,对于目前的编译技术而言是最优的选择。
所以回过头,我们来看RISCV,五位寄存器编码,刚好32个寄存器。
最后说一下CISC的寄存器。按照本篇回答的观点,寄存器在16-32个效用最高,再加上x86的历史遗留的寻址问题,导致x86不可能支持过多的通用寄存器——一是成本和收益不对等,二是通用寄存器会挤占别的特殊寄存器(比如寻址需要用到的基地址寄存器等)。除此之外,寄存器过多,会使得指令编码难以设计,尤其是解码器难以快速解码。
比如你原来有32个通用寄存器,然后你有一套用在32个寄存器上的CISC指令。现在突然变成64个寄存器,怎么在兼容原有指令的基础之上给新加的32个寄存器编码呢?一种思路是直接在所有指令后面加上几位,用来指示各个寄存器的“新旧”,这样设计的话,本来就复杂的CISC解码器就更复杂了...另外一种思路是在原来的那套指令上就留好冗余,用于扩展,但这样浪费太大,一条指令可能也就32到64位,里面有三到四位留作冗余...
risc 一定采用流水线技术, 大部分指令在一个时钟周期内完成
以硬布线控制为主
重视编译优化工作
4.4.3 CISC 和RISC 的比较
risc 的优点:
- risc 更能利用芯片面积, 硬布线控制比微程序控制占用面积小
- risc 更能提高运算速度
- risc 便于设计
- risc 利于编译代码优化
第5章中央处理器
5.1 CPU 的功能和基本结构
5.1.1 CPU 的功能
由运算器和控制器组成
具体功能有:
- 指令控制: 取指令, 分析指令, 执行指令
- 操作控制: 产生指令的操作信号
- 时间控制: 为每条指令按时间顺序昌盛控制信号
- 数据加工: 数据算数和逻辑运算
- 中断处理
5.1.2 CPU 的基本结构
- 运算器
- 算数逻辑单元: 算数逻辑运算
- 暂存寄存器: 暂存MM 来的数据
- 累加寄存器ACC: 通用寄存器, 暂时存放 ALU 运算的结果
- 通用寄存器组, ax, bx, cx, dx, sp 等
- 程序状态字寄存器 PSW
- 移位器
- 计数器: 控制乘除运算操作步数
- 控制器
- 程序计数器 PC
- 指令寄存器IR: 保存当前在执行的指令(CIR current instruction register)
- 指令译码器
- 存储器地址寄存器 MAR
- 存储器数据寄存器 MDR
- 时序系统: 产生时序信号
- 微操作信号发生器, 根据 IR PSW 时序信号产生控制信号, 包括组合逻辑型和存储逻辑型两种
5.2 指令执行过程
5.2.1 指令周期
指令周期定义: cpu从主存取出并执行一条指令的时间称为指令周期, 通常用机器周期表示, 一个机器周期代表一个基本操作所需要的时间(如取指令一个时钟周期, 执行指令一个时钟周期等), 一个机器周期包含若干时钟周期, 时钟周期是 cpu 操作的基本单位
完整的指令周期: 取指周期, 间址周期, 执行周期, 中断周期(处理中断请求)
对应四个标志触发器: FE, IND, EX, INT(fetch, indirect, execute, Interupt)
5.2.2 指令周期的数据流
取指周期
根据 PC 取指令从 MM 到 IR, PC+=1
- PC -> MAR -> address bus -> MEM
- CU -读命令-> control bus -> MEM
- MEM -> data bus -> MDR -> IR
- CU -控制信号-> PC+1
间址周期 根据 IR 内地址取数据从 MM 到 MDR
get EA
- IR address part -> MAR -> address bus -> MEM
- CU -read-> control bus -> MEM
- MEM -> data bus -> MDR
执行周期
根据 IR 中的操作码从 ALU 获得执行结果
中断周期
处理中断请求, 假设断点存入堆栈
- CU -> SP-1, SP -> MAR -> address bus -> MEM 找到栈顶位置
- CU -write-> control bus -> MM 准备写
- PC -> MDR -> data bus -> MEM 将 PC 值存入栈顶
- CU -> PC 中断程序入口地址存入 PC 开始执行
5.2.3 指令执行方案
- 单指令周期 所有指令用相同执行时间完成, 每条指令都在一个时钟周期内完成
- 多指令周期 对不同指令用不同的执行步骤, 所需时钟周期也不同
- 流水线方案 让多条指令同时执行单处于不同执行步骤中
5.3 数据通路的功能和基本结构
5.3.1 数据通路的功能
数据通路由 CU 控制
5.3.2 数据通路的基本结构
cpu 内:
- cpu 内部单总线方式 所有寄存器输入输出连在同一个 bus 上, 会出现数据冲突
- cpu 内部多总线方式 多条 bus
- 专用数据通路方式 根据指令执行过程中的数据流动方向安排线路, 避免冲突, 但硬件量较大
例子
寄存器到寄存器
(PC) -> MARMM 与 CPU: 读指令
(PC) -> MAR
1 -> R //read signal
MEM(MAR) -> MDR
(MDR) -> IR运算
(MDR) -> MAR //EA 存入 MAR
1 -> R //read signal
MEM(MAR) -> MDR
(MDR) -> Y //first param
(ACC) + (Y) -> Z //result in Z
(Z) -> ACC //result in ACC
5.4 控制器的功能和工作原理
5.4.1 控制器的结构和功能
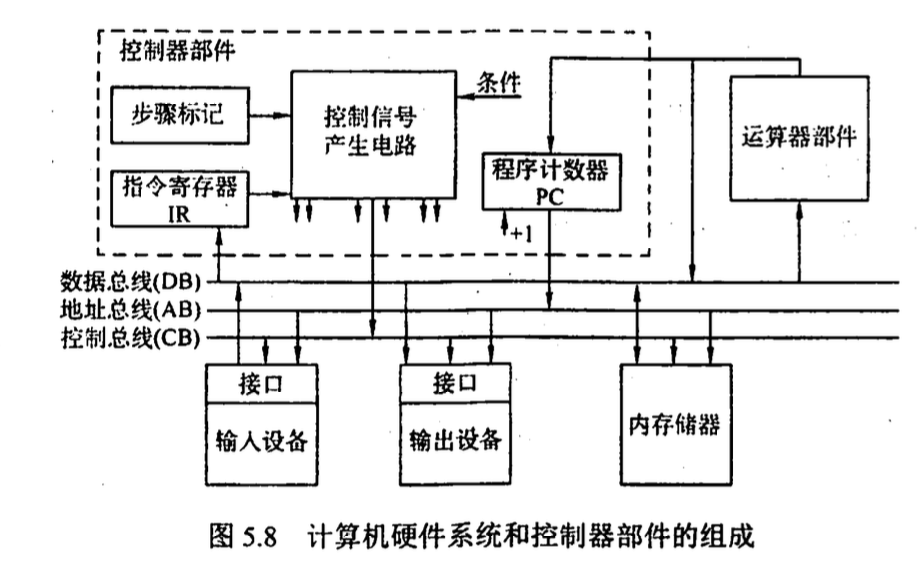
控制器的主要功能:
- 从 MM 取指令, 指出下一条指令的位置
- 指令译码, 产生控制信号
- 控制数据流动方向
5.4.2 硬布线控制器
CU 输入:
- 译码产生的指令信息
- 时序系统产生的机器周期信号和节拍信号(节拍宽度对应一个时钟周期, 机器周期一般以存取周期作为基准时间)
- 执行单位的反馈信息, 即状态标志
- 其他如中断请求, DMA 请求
微操作实现
- 取指令操作
(PC) -> MAR |
- 间址周期操作
ADDRESS PART OF IR -> MAR |
- 执行周期非访存操作
CLA, COM, SHR, CSL, STP 等
- 执行周期访存操作
// ADD X |
- 执行周期转移操作
// JMP X 无条件转移 |
cpu 控制方式
- 同步控制方式 所有控制信号来自统一时钟, 以最长最复杂信号为标准, 电路简单但速度慢
- 异步控制方式 各个部件以固有速度工作, 通过应答方式联络, 电路复杂
- 联合控制方式 大部分同步控制, 小部分异步控制
设计步骤?
5.4.3 微程序控制器
每条机器指令编写成一个微程序(微程序种类数量一般为机器指令种类数量+取指, 间址, 中断等微程序), 每个微程序包含若干微指令, 每条微指令对应若干微操作命令. 这些微程序存储在一个控制存储器中
微操作是计算机中最基本不可再分解的操作 微命令是控制部件向执行部件发出的各种控制命令 微操作与微命令一一对应 微命令之间有互斥和相容
微指令是若干微命令的集合, 存放微指令的控制存储器的单元地址称为微地址, 一条微指令包含至少两部分:
- 操作控制字段: 微操作码字段, 用于产生各种操作控制信号
- 顺序控制字段: 微地址码字段, 用于控制产生下一条微指令地址
微周期是执行一条微指令所需的时间, 通常为一个时钟周期
控制存储器 CM(control memory): 用于存放微程序, 在 cpu 内部, 用 rom 实现
微程序控制器的组成:
- 控制存储器 CM
- 微指令寄存器 CMDR(应该叫控制存储器数据寄存器?)
- 微地址形成部件: 用于产生初始和后继微地址
- 微地址寄存器 CMAR: 接收微地址, 为在 CM 中读取微指令做准备(应该叫控制存储器地址寄存器?)
微程序控制器的工作过程:
- 自动将取指微程序的入口地址送到 CMAR, 根据 CMAR 从 CM 读出微指令送入 CMDR, 取指微程序执行, 执行完后主存中的机器指令存入 IR
- 根据 IR 的操作码字段, 通过微地址形成部件产生对应微程序的入口地址送入 CMAR
- 从 CM 逐条取出微指令并执行
- 完成机器指令后, 回到 1, 重复
微指令编码方式
- 直接编码 无需译码, 微指令的微命令字段中每一个 bit 都代表一个微命令 简单, 执行快, 操作并行性好 但微指令字太长, 导致 CM 容量大
- 字段直接编码 将微指令的微命令字段分成若干字段, 将互斥的微命令放在同一字段中, 相容放在不同字段中, 对每个字段进行译码 缩短了字长, 但是慢
- 字段间接编码 一个字段的某些微命令需要另一个字段中的某些微命令来解释 进一步缩短字长, 但削弱了并行性
微指令地址形成方式
- 由微指令的地址字段直接给出, 又叫断定方式
- 根据机器指令的操作码形成, 由微地址形成部件产生
- 增量计数 (CMAR) + 1 => CMAR
- 根据各种标志决定分支转移地址
- 通过测试网络形成
- 由硬件直接产生(例如刚开机执行取指令微程序)
微指令格式
水平型微指令 直接编码, 字段直接编码, 字段间接编码, 混合编码都属于水平型
A1, A2... 判断测试字段, 后继地址字段垂直型微指令
微操作码, 目的地址, 源地址由微操作码指定微指令功能, 一条垂直指令只能执行一种基本操作混合型
比较:
- 水平: 并行好, 速度快, 灵活性强, 执行一条指令需要的时间短, 用户难以掌握, 微指令字长微程序短
- 垂直: 并行差, 一条指令时间长, 微指令字短微程序长, 用户易掌握
设计?
5.5 异常和中断机制
5.5.1 异常和中断的基本概念
CPU 内部产生的意外事件(与正在执行的指令相关的同步事件)叫异常, 内中断
cpu 外部设备向 cpu 发出的中断请求(通常用于输入输出)叫中断, 外中断
5.5.2 异常和中断的分类
分类问题:[https://stackoverflow.com/questions/3149175/what-is-the-difference-between-trap-and-interrupt]???和王道不符, 采用 stackoverflow???
exception 包括以下3种, 是 cpu 内部的问题
trap(也可以叫访管指令?应该是一种东西) A trap is an exception in a user process. It's the usual way to invoke a kernel routine (a system call) because those run with a higher priority than user code. Handling is synchronous (so the user code is suspended and continues afterwards). In a sense they are "active" - most of the time, the code expects the trap to happen and relies on this fact. trap 后会执行 trap 之后的语句
fault 故障 A fault is an exception that can generally be corrected and that, once corrected, allows the program to be restarted with no loss of continuity. When a fault is reported, the processor restores the machine state to the state prior to the beginning of execution of the faulting instruction. The return address (saved contents of the CS and EIP registers) for the fault handler points to the faulting instruction, rather than to the instruction following the faulting instruction. fault 之后会再次执行 fault 的语句(如果处理不了 fault 会手动增加 return address 得到 trap-like 行为), eg: page fault
abort
An abort is an exception that does not always report the precise location of the instruction causing the exception and does not allow a restart of the program or task that caused the exception. Aborts are used to report severe errors, such as hardware errors and inconsistent or illegal values in system tables.
interrupt, 是 cpu 外部的问题 The term Interrupt is usually reserved for hardware interrupts. They are program control interruptions caused by external hardware events. Here, external means external to the CPU. Hardware interrupts usually come from many different sources such as timer chip, peripheral devices (keyboards, mouse, etc.), I/O ports (serial, parallel, etc.), disk drives, CMOS clock, expansion cards (sound card, video card, etc). That means hardware interrupts almost never occur due to some event related to the executing program.
- 可屏蔽中断 通过可屏蔽中断请求线 INTR 向cpu 发送的中断请求 cpu 可以在中断控制器中设置相应屏蔽词来屏蔽
- 不可屏蔽中断 通过专门的不可屏蔽中断请求线 NMI 向 cpu 发出的中断请求
硬件中断: interrupt + abort, 软件中断: trap + fault
例子:
- interrupt: io 请求, 时钟中断(时间片)
- exception
- trap: 用户态到核心态
- fault: page fault缺页, 非法操作码, 除 0, 运算溢出
- abort: 控制器出错, 存储器校验错
关于 trap 和 systemcall
- Traps: A trap is an interrupt generated by the CPU when a user-level program attempts to execute a privileged instruction or encounters an error. When a trap occurs, the CPU transfers control to the kernel and executes a trap handler. The trap handler checks the type of trap and takes appropriate action, such as terminating the program or performing a privileged operation on behalf of the program.
- System calls: A system call is a request made by a user-level program to the OS to perform a privileged operation, such as reading from or writing to a file or allocating memory. To make a system call, the program executes a special instruction that triggers a software interrupt. The OS then transfers control to the kernel and executes a system call handler. The system call handler checks the type of system call and takes appropriate action, such as reading from a file or allocating memory.
- Traps and system calls are similar in that they both involve transferring control to the kernel to perform privileged operations. However, traps are usually generated automatically by the CPU when a program encounters an error or attempts to execute a privileged instruction, while system calls are initiated by the program itself to request privileged operations.
5.5.3 异常和中断响应过程
当遇到中断时步骤:
- 关中断 禁止响应新的中断, 通常设置 中断允许 IF 触发器来实现, 1 为开 0 为关(不响应)
- 保存断点和程序状态 返回地址和程序状态字寄存器 PSWR 保存到栈或者特定寄存器中
- 识别异常和中断 异常大多软件识别, 中断即可软件识别又可硬件识别
- 软件识别是 cpu 内设置一个异常状态寄存器, 用于记录异常原因, 操作系统使用查询程序查询此寄存器来检测种类, 然后转到内核的处理程序
- 硬件识别, 又叫向量中断, 中断处理程序的首地址叫做中断向量, 所有中断向量被放在中断向量表中
- 转到响应处理程序
- 返回
其中 1-3 为 cpu 的操作
单级中断的过程: 其中 1~3 硬件完成, 4~8 中断服务程序完成
- 关中断
- 保存断点
- 识别中断源
- 保存现场(包括: PC, 标志寄存器, 与之对比, 子程序调用只要求保存 PC, 中断的通用寄存器保存由操作系统执行(而不是中断服务程序))
- 中断事件处理
- 恢复现场
- 开中断
- 中断返回
中断隐指令指CPU响应中断之后,经过某些操作,转去执行中断服务程序的一种操作 CPU收到中断信息后,首先引发中断过程,由硬件完成,没有指令对应。即中断隐指令。以8086为例,中断过程做的事:取中断类型码N;EFLAGS进栈;TF=0,IF=0;CS进栈;IP进栈;设置CS、IP为中断处理程序的入口。 而中断处理程序要做的第一件事就是保存通用寄存器的内容。 进一步,在保护模式中,不同特权级对应不同特权栈,用户态下中断处理通常进入内核态,导致栈的切换,此时程序断点就保存在内核栈了;内核态的中断处理还是在内核态,故在内核栈。所以,程序断点在内核栈中。
保护模式下的中断操作(详细)
- CPU检查是否有中断/异常信号 CPU在执行完当前程序的每一条指令后,都会去确认在执行刚才的指令过程中中断控制器(如:8259A)是否发送中断请求过来,如果有那么CPU就会在相应的时钟脉冲到来时从总线上读取中断请求对应的中断向量。 对于异常和系统调用那样的软中断,因为中断向量是直接给出的,所以和通过IRQ(中断请求)线发送的硬件中断请求不同,不会再专门去取其对应的中断向量。
- 根据中断向量到IDT(中断描述符表 Interrupt Descriptor Table)表中取得处理这个向量的中断程序的段选择符
- 根据取得的段选择符到GDT(Global Descriptor Table)中找相应的段描述符, 此时CPU就得到了中断服务程序的起始地址。 这里,CPU会根据当前cs(code segment)寄存器里的CPL和GDT的段描述符的DPL,以确保中断服务程序是高于当前程序的,如果这次中断是编程异常(如:int 80h系统调用),那么还要检查CPL和IDT表中中断描述符的DPL,以保证当前程序有权限使用中断服务程序,这可以避免用户应用程序访问特殊的陷阱门和中断门[3]。https://zhuanlan.zhihu.com/p/590066420?utm_id=0
- CPU根据特权级的判断设定即将运行的中断服务程序要使用的栈的地址 CPU会根据CPL和中断服务程序段描述符的DPL信息确认是否发生了特权级的转换,比如当前程序正运行在用户态,而中断程序是运行在内核态的,则意味着发生了特权级的转换,这时CPU会从当前程序的TSS信息(该信息在内存中的首地址存在TR寄存器中)里取得该程序的内核栈地址,即包括ss和esp的值,并立即将系统当前使用的栈切换成新的栈。这个栈就是即将运行的中断服务程序要使用的栈。紧接着就将当前程序使用的ss,esp压到新栈中保存起来。
- 保护当前程序的现场 CPU开始利用栈保护被暂停执行的程序的现场:依次压入当前程序使用的eflags,cs,eip,errorCode(如果是有错误码的异常)信息。(不包括通用寄存器)
- 跳转到中断服务程序(也叫中断处理子程序, 从此开始属于软件, 也是操作系统的范畴)的第一条指令开始执行 CPU利用中断服务程序的段描述符将其第一条指令的地址加载到cs和eip寄存器中,开始执行中断服务程序。这意味着先前的程序被暂停执行,中断服务程序正式开始工作。
- 中断服务程序处理完毕,恢复执行先前中断的程序 在每个中断服务程序的最后,必须有中断完成返回先前程序的指令,这就是iret(或iretd)。程序执行这条返回指令时,会从栈里弹出先前保存的被暂停程序的现场信息,即eflags,cs,eip重新开始执行
5.6 指令流水线
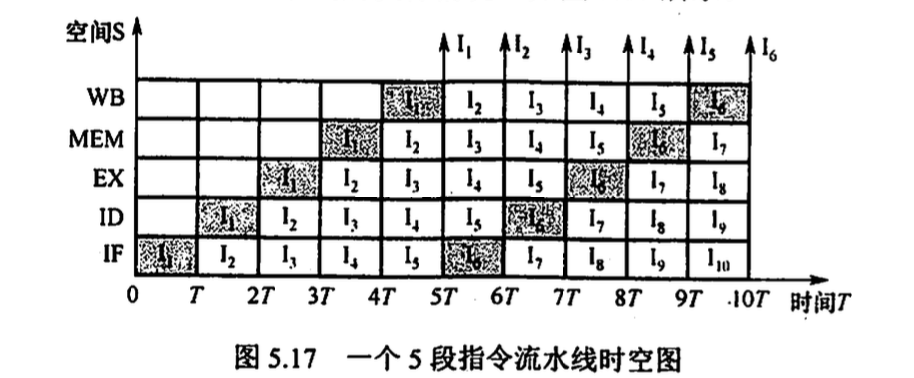
5.6.1 指令流水线的基本概念
时间并行: 一个任务分成多个阶段在不同功能部件上执行
空间并行: 一个处理机内设置多个执行相同功能的部件, 这样的处理机叫超标量处理机
指令流水线:
- 阶段: 取指 IF, 译码/读寄存器 ID, 执行/计算地址 EX, 访存 MEM, 写回 WB
- 实现流水线的指令集的条件
- 指令长度尽量一致
- 指令规格尽量规整
- 使用 load/store 指令
- 数据指令对齐存放
- 流水线的表示方法
5.6.2 流水线的基本实现 (对单周期指令)?
5.6.3 流水线的冒险与处理
流水线冒险: 在流水线中遇到情况使流水线无法正确执行后续指令引起阻塞或停顿
结构冒险(资源冲突) 多条指令同时争夺同一资源 解决方法:
- 前一指令访存时, 后一指令暂停一个时钟周期
- 单独设置数据存储器和指令存储器, 避免冲突
数据冒险 下一条指令会用到当前指令的计算结果 分类
- 写后读 RAW: 当前写完, 下一条才能读
- 读后写 WAR: 当前读完, 下一条才能写
- 写后写 WAW: 当前写完, 下一条才能写
解决方法
- 把数据相关和后续指令都暂停几个时钟周期, 又可分为硬件阻塞(stall) 和软件插入 (NOP)方法
- 设置相关专用通路(数据旁路), 不等待当前指令, 下一条指令直接从 ALU 读取计算结果避免暂停
- 编译优化指令顺序
控制冒险 转移, 调用, 返回会改变 PC 的值, 造成断流 解决方法
- 分支预测(分静态动态), 尽早生成转移目标地址
- 预取转移成功和不成功两个控制流方向上的目标指令
- 加快提前生成条件码
- 提高转移方向预测率
5.6.4 流水线的性能指标
吞吐率 \(TP=\frac n {T_k}\) n 是任务数, Tk 是完成 n 个任务用的总时间, k 是流水线段数, \(\Delta t\)是时钟周期, 在理想连续情况下, 流水线的吞吐率: \(TP = \frac n {(k+n-1)\Delta t}\)
流水线加速比 \(S = \frac {T_0}{T_k}\) T0为不使用流水线的时间, 理想情况下: \(S = \frac {kn\Delta t}{(k-n+1)\Delta t} = \frac{kn}{k+n-1}\)
5.6.5 高级流水线技术
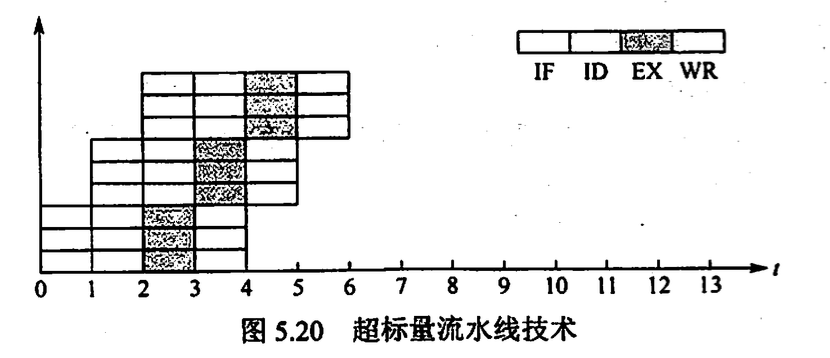
超标量流水线技术(动态多发射技术)
每个时钟周期并发多条独立指令, 为此需要多个处理部件
超长指令字技术(静态多发射技术)
由编译程序挖掘指令潜在的并行性, 将多条可并行指令组合成一条由多操作码字段的超长指令字, 为此需要多个处理部件
超流水线技术 提高流水线 主频
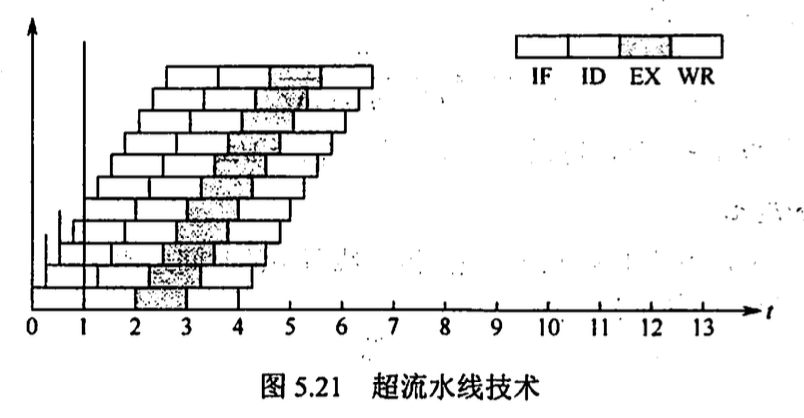
5.7 多处理器的基本概念
5.7.1 SISD、SIMD、 MIMD 的基本概念
- 单指令流单数据流 SISD 一个处理器一个存储器
- 单指令流多数据流 SIMD 数据并行, 一个指令控制部件, 多个处理单元, 处理单元虽然执行相同指令, 但处理不同数据, 例如循环 向量处理器是 SIMD 的变体, 是一种实现了直接操作向量指令集的 cpu
- 多指令流单数据流 MISD 不存在这样的计算机
- 多指令流多数据流 MIMD
- 多计算机系统(消息传递 MIMD) 每个计算机节点有各自私有的存储器, 独立的储存地址, 不能通过存取指令访问其他计算机节点, 而需要消息传递
- 多处理器系统(共享存储多处理器 SMP) 共享的单一地址空间
5.7.2 硬件多线程的基本概念
为每个线程提供单独的通用寄存器组, 单独的PC
实现方式有:
细粒度多线程
多个线程轮流交叉执行指令, 线程之间指令不相关, 可以乱序并行执行, 处理器能在每个时钟周期切换线程
粗粒度多线程 仅在一个线程出现较大开销的阻塞时才切换线程(如 cache 缺失), 切换时必须重载流水线, 开销更大
同时多线程 SMT 同一时钟周期中, 发射多个不同线程的多条指令执行
5.7.3 多核处理器的基本概念
多个处理单元集成到单个 cpu, 每个处理单元为一个核 core, 每个 core 有自己的 cache 也可以共享一个 cache, 核一般对称并共享主存储器
5.7.4 共享内存多处理器的基本概念
共享单一物理地址空间的多处理器叫共享内存多处理器 SMP 处理器通过存储器中的共享变量通信
分类:
- 统一存储访问(UMA)多处理器: 每个存储器对所有存储单元访问时间是大致相同的
- 非统一存储访问(NUMA)多处理器: 某些访存请求比其他快
第6章 总线
6.1 总线概述.
6.1.1 总线基本概念
总线是能为多个部件分时共享的公共信息传送路线
总线设备:
- 主设备: 获得总线控制权的设备
- 被主设备访问的设备, 只能响应从主设备发来的总线命令
6.1.2 总线的分类
- 片内总线 cpu内: 寄存器与寄存器, 寄存器与 ALU 之间的公共连接线
- 系统总线 各功能部件(cpu, MM, IO)之间相互连接的总线, 按传输信息内容分为
- 数据总线: 双向传输, 位数与机器字长存储字长有关, 数据通路是数据流经的路径, 数据总线是承载的媒介
- 地址总线: 单向总线, 位数与主存地址空间大小有关
- 控制总线: cpu 发出的控制命令和外设主存返回给 cpu 的反馈信号
- io 总线 通过 io 接口与系统总线相联, 目的是将低速设备与高速总线分离 其中控制总线, 地址总线是 cpu 到 io 单向, 数据总线是双向
- 通信总线(外部总线) 计算机系统之间传输信息的总线
按时序控制分为同步总线, 异步总线
按数据传输格式分为并行总线, 串行总线
6.1.3 系统总线的结构
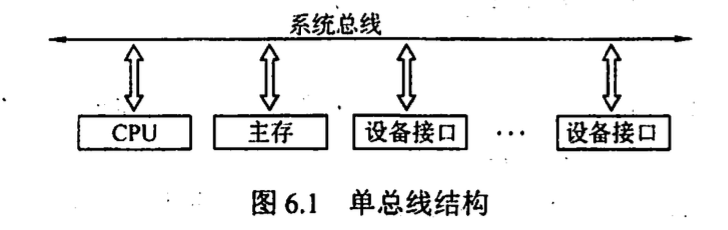
- 单总线结构
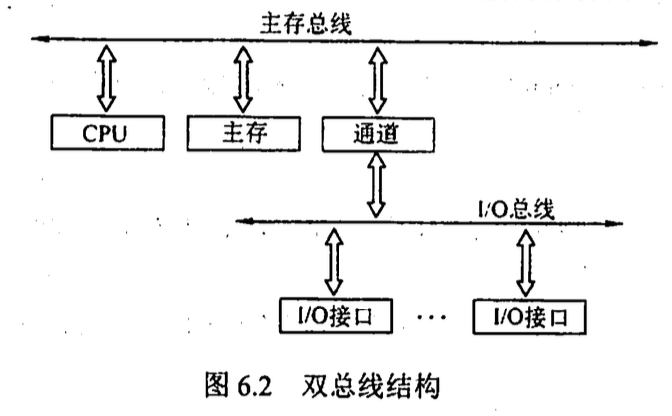
- 双总线结构 一条是主存总线, 连接 cpu 主存和通道, 一条是 io 总线, 连接外部设备和通道
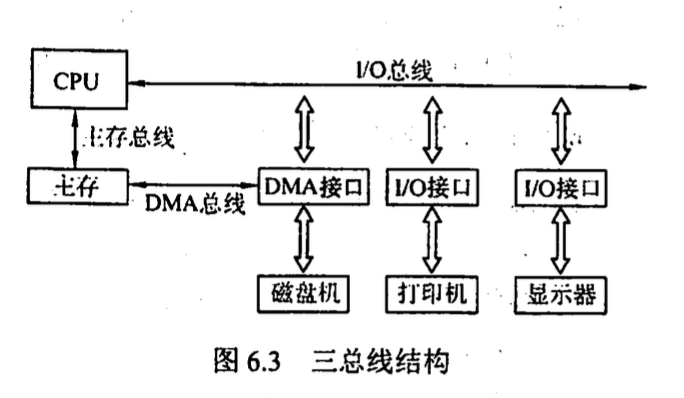
- 三总线结构 主存总线, io 总线, 直接内存访问总线(DMA)
6.1.4 常见的总线标准
- ISA industry standard architecture
- EISA extended industry standard architecture, 为配合 32bit'cpu, 兼容 ISA
- VESA video electronics standards association, 32bit 局部总线, 传送图像
- PCI peripheral component interconnect, 外部设备互联, 高性能 32bit/64bit 总线, 如显卡声卡网卡, 支持即插即用, pci 总线是一个与处理器时钟无关的外围高速总线, 是局部总线
- AGP accelerated graphics port, 传输视频三维图形, 局部总线
- PCI-E PCI-express, 最新
- RS-232C, 串行通信总线, 应用于串行二进制交换的数据终端设备 DTE 和数据通信设备 DCE
- USB, universal serial bus, io 总线, 设备总线, 热插拔, 串行(serial)
- PCMCIA personal computer memory card international association, 扩展功能的小型插槽
- IDE integrated drive electronics, ATA, 硬盘和光驱
- SCSI small computer system interface, 硬盘软驱
- SATA serial advanced technology attachment, 出行硬件驱动器接口, 硬盘接口规范
6.1.5 总线的性能指标
- 总线传输周期: 一次总线操作需要的时间 包括: 申请阶段, 寻址阶段, 传输阶段, 结束阶段. 由若干总线时钟周期组成
- 总线时钟周期: 就是机器的时钟周期
- 总线工作频率: 1/总线传输周期
- 总线时钟频率: 1/总线时钟周期
- 总线宽度: 总线位宽
- 总线带宽: 总线最大传输速率, byte/s, \(总线带宽 = 总线工作频率 * (总线宽度/8)\)
- 总线复用: 一种信号线在不同时间传输不同信息
- 信号线数
6.2 总线事务和定时
6.2.1 总线事务
从请求总线到完成总线使用的操作序列叫总线事务, 步骤有;
- 请求阶段: 发出总线传输请求获得总线控制权
- 仲裁阶段: 总线仲裁部分决定使用权给谁
- 寻址阶段: 主设备通过总线给出要访问的从设备地址及有关命令, 启动从模块
- 传输阶段: 主模块和从模块进行数据交换
- 释放阶段, 主模块信息从总线上撤除, 让出总线使用权
突发传送方式能进行连续成组数据传送, 每个时钟周期传送一个字长但是不释放总线 突发(burst)将多个传输作为一个单元进行执行,而不是独立地处理每个字。
6.2.2 同步定时方式
系统采用统一时钟信号协调发送和接收双发的传送定时关系
简单,速度快, 但不能进行有效性检测
6.2.3 异步定时方式
没有统一时钟, 依靠传送握手信号实现定时控制
可以保证工作速度差距很大的部件可靠的传输数据, 但更复杂速度慢
分类:
- 不互锁: 主设备的请求信号和从设备的响应信号都是发出一段时间后撤回, 不必等待应答
- 半互锁: 主设备请求信号必须接收到从设备的响应信号才撤回, 从设备的响应信号的撤回不必等待请求信号的撤回
- 全互锁: 都必须等待对方才能撤回
第7章输入/输出系统
7.1 I/O系统基本概念
*7.1.1 输入/输出系统
- 外部设备
- 接口: 各个外设与主机传输数据时进行各种协调工作的逻辑部件, 包括速度匹配, 电平, 格式转换等
- io 软件: 驱动程序等
- io 硬件
*7.1.2 I/O控制方式
- 程序查询方式
- 程序中断方式
- DMA 方式
- 通道方式
*7.1.3 外部设备
7.2 I/O接口 (I/O 控制器)
7.2.1 I/O接口的功能
- 地址译码和设备选择
- 实现主机与外设的通信联络控制
- 数据缓冲
- 信号格式转换: 如电平转换, 串并转换, 模数转换
- 传送控制命令和状态信息
7.2.2 I/O 接口的基本结构
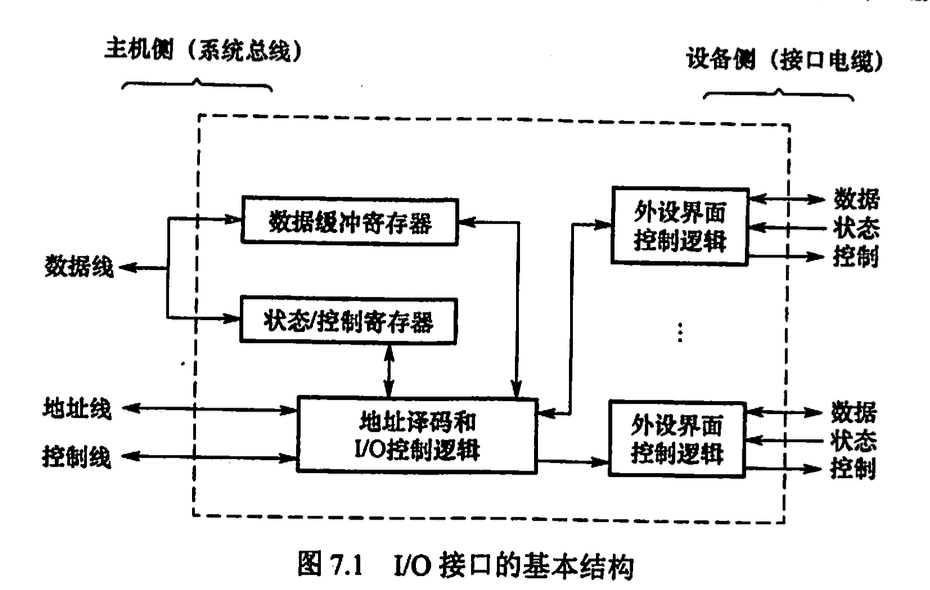
7.2.3 I/O接口的类型
- 并行接口(一字节或一字所有位同时传输)和串行接口(一位一位传输)
- 按主机访问方式: 程序查询接口, 中断接口, DMA 接口
- 按功能灵活性: 可编程接口, 不可编程接口
7.2.4 I/O 端口及其编址
IO 端口是指接口电路中可以被 cpu 直接访问的寄存器, 主要有数据端口, 状态端口, 控制端口 每个端口对应一个端口地址 端口的编址方式有
- 统一编址(存储器映射方式): 把 io 端口当做存储器的单元进行地址分配, 不需要 cpu 设置专门的 io 指令 内存空间变小, 速度慢
- 独立编址(io 映射方式): 需要专门的 io指令访问 io 端口
7.3 I/O方式
7.3.1 程序查询方式
信息交换控制完全由 cpu 执行实现
接口中设置一个数据端口, 一个状态端口, 主机进行 io 时, 先发出询问信号, 读取设备状态决定下一步是传输还是等待
流程:
- cpu 执行初始化程序, 预置传送参数
- 向 io 接口发出命令字, 启动 io 设备
- 不断查询状态端口中的状态, 直到外设准备就绪
- 传送一次数据
- 修改地址和计数器参数
- 判断传送是否结束, 没结束->3, 直到计数器=0
cpu 存在踏步现象
7.3.2 程序中断方式
? 见操作系统
7.3.3 DMA 方式
完全由硬件组成的信息传送控制方式, 数据准备阶段 cpu 和外设平行工作
主存和 DMA 之间有一条直接数据通路, 数据传输不需要经过 cpu 具有以下特点:
- 主存既可以被 cpu 访问, 又可以被外设访问
- 数据块传送时, MM 地址的确定, 传送数据的计数都由硬件电路实现
- 主存中要开辟专门的缓冲区
- DMA 传送速度快, cpu 和外设并行工作
- DMA 在传送开始前要通过程序进行预处理, 结束后要通过中断方式进行后处理
DMA 控制器(DMA 接口)组成 当 io 设备需要进行数据传输时, 通过 DMA 从志气向 cpu 提出传送请求, cpu 响应后让出系统总线, DMA 接管总线进行数据传输, 主要功能有:
- 接受外设发出的 DMA 请求, 并向 CPU 发出总线请求
- cpu 响应发出总线响应信号, DMA 接管总线控制权, 进入 DMA 操作周期
- 确定传送数据的主存单元地址和长度, 自动修改主存地址计数和长度计数
- 规定数据在主存和外设间的传送方向, 发出读写控制信号, 执行数据传送
- 向 cpu 报告 DMA 操作结束
DMA 传送过程中将接管 cpu 的地址数据控制总线, 可见 DMA 控制器必须有控制系统总线的能力
DMA 的传送方式
- 停止访问主存: 当有 DMA 请求时, cpu 停止访问 MM
- 周期挪用: 当 io 的 DMA 与 cpu 同时请求访存时, io 优先级更高(因为 io 不立即访存可能丢失数据), 此时 io 设备挪用几个存取周期, 传送完一个数据后立即释放总线, 是一种单字传输方式
- DMA 与 cpu 交替访存: 适用于cpu 工作周期>存取周期, 此时可将 cpu 工作周期划分为两个周期, 一个专供 DMA 访存, 一个专供 CPU 访存
DMA 传送过程
- 预处理: cpu 执行几条 io 指令测试 io 设备状态, 初始化 DMAC 中的寄存器等, 然后 cpu 继续执行原来程序, 直到 io 向 DMAC 发送 DMA 请求, DMAC 向 cpu 发送总线请求再传输数据
- 数据传输: DMA 数据传输以 byte 或数据块为单位, 这个循环是由 DMAC 实现的, 即数据传输阶段完全由 DMA 控制
- 后处理, DMAC 向 cpu 发送中断请求, cpu 执行 DMA 结束处理, 包括校验, 是否使用 DMA 传输其他数据等






