操作系统
计算机系统概述
操作系统: 控制和管理整个计算机系统的硬件和软件资源
组成:
一.驱动程序:最底层的、直接控制和监视各类硬件的部分。它们的职责是隐藏硬件的具体细节,并向其它部分提供一个抽象的、通用的接口。
二.内核:操作系统的内核部分通常运行在最高特权级,负责提供基础性、结构性的功能。
三.接口库:是一系列特殊的程序库。它们的职责在于把系统所提供的基本服务包装成应用程序所能够使用的编程接口(API)。这是最靠近应用程序的部分。
四.外围:指操作系统中除以上三类以外的所有其它部分,通常是用于提供特定高级服务的部件。
最基本的特征: 并发 共享
- 并发(同一时间间隔)(并行是指同时) 计算机系统重同时存在多个运行的程序, 注意区分并行(同一时刻) os 的并发是通过分时实现的
- 共享 资源可被多个并发的进程共同使用, 分为
- 互斥共享方式: 在一段时间内只允许一个进程访问该资源, 这种资源叫临界资源
- 同时访问方式: 允许在一段时间内多个进程同时(并发)访问, 如磁盘
- 虚拟 虚拟处理器: 多道程序设计技术, 使多个程序并发执行, 把一个物理上的 cpu 虚拟为多个逻辑的 cpu 虚拟存储器: 逻辑上扩充存储器的容量 虚拟外部设备: 将一台物理 io 虚拟为多个逻辑上的 io 可归纳为: 时分复用技术, 空分复用技术
- 异步 进程的执行是走走停停
操作系统的功能
- 作为计算机资源的管理者
- 处理机管理: 对进程的管理, 如进程控制, 进程通步, 进程通信, 死锁处理, 处理机调度等
- 存储器管理: 内存分配回收, 地址映射, 内存保护与共享, 内存扩充
- 文件管理: 文件系统
- 设备管理: 完成用户的 io 请求
- 作为用户与计算机硬件系统之间的接口
- 命令接口
- 联机命令接口(交互式命令接口)
- 脱机命令接口(批处理命令接口)
- 程序接口 由一组系统调用组成
- 命令接口
- 对计算机资源的扩充 没有任何软件支持的计算机叫裸机 把覆盖了软件的机器称为 扩充机器或虚拟机
操作系统发展历程
cpu 执行两种不同的程序
- 操作系统内核程序
- 用户自编程序(应用程序)
内核: Kernel is central component of an operating system that manages operations of computer and hardware. It basically manages operations of memory and CPU time. It is core component of an operating system. Kernel acts as a bridge between applications and data processing performed at hardware level using inter-process communication and system calls.
Kernel has a process table that keeps track of all active processes
It decides which process should be allocated to processor to execute and which process should be kept in main memory to execute. It basically acts as an interface between user applications and hardware. The major aim of kernel is to manage communication between software i.e. user-level applications and hardware i.e., CPU and disk memory.
Objectives of Kernel :
- To establish communication between user level application and hardware.
- To decide state of incoming processes.
- To control disk management.
- To control memory management.
- To control task management.
其中内核程序可以执行特权指令, 应用程序不能执行特权指令
- 特权指令: io 指令, 置中断指令
- 非特权指令: 仅限于访问用户的地址空间
cpu 运行模式分为
- 用户态(目态)
- 核心态(管态, 内核态)
应用程序通过访管指令向操作系统请求服务, 产生中断从用户态切换到核心态
内核是计算机的底层软件, 管理系统资源, 是连接应用程序和硬件的桥梁, 包括:
- 时钟管理
- 计时
- 时钟中断(时间片轮转)
- 中断 中断机制中的: 保护恢复中断现场, 转移控制权到相关程序, 属于内核部分
- 原语 是一些公用小程序, 各自完成一个规定的操作, 特点:
- 处于操作系统最底层, 最接近硬件
- 有原子性, 只能一气呵成
- 运行时间短, 频繁调用
- 系统控制的数据结构及处理 如作业控制块, 进程控制块, 消息队列, 缓冲区, 内存分配表等 常见的操作有:
- 进程管理
- 存储器管理
- 设备管理
1.3.2 中断和异常的概念
从用户态到核心态需要中断或异常, 这是通过硬件实现的
1.3.3 系统调用
用户在程序中调用操作系统提供的一些子功能, 按功能可分为:
- 设备管理
- 文件管理
- 进程管理
- 进程通信
- 内存管理
用户通过访管指令(trap 指令)发起系统调用
1.4 操作系统结构
分层法
模块化: 内聚, 耦合
宏内核(单内核, 大内核)
微内核: 将非核心功能移到用户控件 微内核将操作系统分为:
- 微内核: 包括
- 与硬件处理紧密相关的部分
- 一些基本的功能
- 客户与服务器之间的通信
- 多个服务器(进程), 如线程管理, 进程管理, 虚拟存储器管理
在用户态, 客户进程与服务器是借助微内核提供的消息传递机制来交互的
功能:
- 进程线程管理: 机制部分(切换, 调度, 同步)放入微内核; 策略部分(分类, 优先级策略)放入服务器
- 低级存储器管理: 如将逻辑地址变为物理地址的页表机制和地址变换机制放入微内核, 这些依赖于硬件; 页面置换算法, 内存分配和回收策略放入服务器
- 中断和陷入处理: 捕获发生的中断事件并进行中断响应处理放入微内核; 之后发送给服务器处理
- 微内核: 包括
外核: 给每个用户整个资源的一个子集
1.5 操作系统引导
定义: 计算机利用 cpu 运行特定程序, 通过程序识别硬盘上的操作系统, 通过程序启动操作系统
过程:
- 激活 cpu 激活的 cpu 读取 ROM 中的 boot 程序, 将 IR 置为 BIOS(基本输入输出系统) 的第一条指令, 并开始执行 BIOS
- 硬件自检 检查硬件是否有故障
- 加载带有操作系统的硬盘 cpu 将该存储设备引导扇区的内容加载到 MM
- 加载主引导记录(MBR) MBR 告诉 cpu 去硬盘的哪个主分区找操作系统
- 扫描硬盘分区表 硬盘分区表在 MBR 中, MBR 识别有操作系统的硬盘分区(活动分区)
- 加载分区引导记录 PBR 读取活动分区第一个扇区, 这个扇区叫做 PBR, 作用是寻找并激活分区根目录下用于引导操作系统的程序(启动管理器)
- 加载启动管理器
- 加载操作系统
1.6 虚拟机
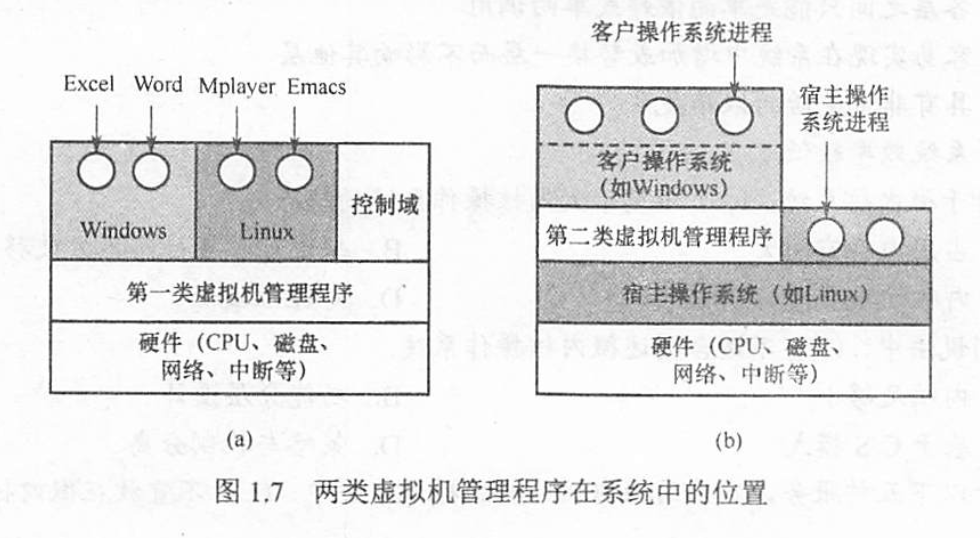
虚拟方法:
- 第一类虚拟机管理程序 是唯一运行在最高特权级的程序, 虚拟机管理程序向上层提供若干台虚拟机 虚拟机作为用户态的一个进程运行, 但虚拟机上的 os 认为自己运行在内核态, 称为虚拟内核态 当虚拟机 os 执行特权指令时, 虚拟机管理程序检查是 os 执行的还是应用程序执行的
- 第二类虚拟机管理程序 虚拟管理程序上的os 称为客户操作系统, 运行在底层的os 称为宿主操作系统
进程与线程
进程控制块 PCB(process control block)
进程实体(进程映像)包括: 程序段, 相关数据段, pcb
进程的定义:
- 进程是程序的一次执行过程
- 进程是一个程序及其数据在处理机上顺序执行时所发生的活动
- 进程是具有独立功能的程序在一个数据集合上运行的过程, 是系统进行资源分配和调度的一个独立单位
- 进程是进程实体的运行过程
进程的特点:
- 动态性: 是进程最基本的特征, 进程具有一定的生命周期
- 并发性: 是进程的重要特征, 多个进程实体同时存在于 MM, 能在一段时间内同时运行
- 独立性: 进程实体是一个能独立运行, 独立获得资源和独立接受调度的基本单位
- 异步性: 进程按各自独立, 不可预知的速度向前推进
引起进程创建的事件:
- 用户登录: 用户管理进程
- 作业调度
- 提供服务
- 应用请求
2.1.2 进程的状态与转换
进程的状态:
- 基本状态
- 运行态: 进程正在处理机上运行
- 就绪态: 进程获得了除处理机外的一切所需资源, 通常存在于就绪队列
- 阻塞态(等待态): 正在等待某一事件而暂停运行, 即使处理机空闲也不能运行, 并根据阻塞原因存在于不同的阻塞队列
- 其他状态
- 创建态: 创建工作尚未完成, 进程就处在创建态
- 终止态: 进程需要结束运行时, 先被置为终止态, 再进一步释放资源
flowchart LR; |
2.1.3 进程的组成
pcb 进程创建时新建 pcb, 之后该结构常驻内存, 是进程存在的唯一标志 进程执行时, 系统通过 pcb 了解进程状态 进程结束时, 系统回收 pcb pcb 主要包含的内容
- 进程描述信息:
- 进程标识符: 每个进程唯一的标识号
- 用户标识符: 进程归属的用户
- 进程控制和管理信息
- 进程当前状态
- 进程优先级
- 代码运行入口地址
- 程序外存地址
- 进入内存时间
- 处理机占用时间
- 信号量使用
- 资源分配清单
- 代码段数据段堆栈段指针
- 文件描述符, io 等
- 处理机相关信息(处理机上下文)
- 通用寄存器值
- 地址寄存器值
- 控制寄存器值
- 标志寄存器值
- 状态字
pcb 的组织方式: 链接或索引
- 进程描述信息:
程序段: 程序段可以被多个进程共享
数据段
2.1.4 进程控制
一般把进程控制用的程序段称为原语
- 进程的创建 允许一个进程创建另一个进程, 父子关系, 子进程可以继承父进程拥有的资源, 子进程被撤销时将从父进程获得的资源归还父进程, 撤销父进程会撤销其所有子进程 过程:
- 为新进程分配唯一标识, 申请空白 pcb(可能失败)
- 为进程分配所需资源, 资源不足就处于创建态等待
- 初始化 pcb
- 若就绪队列能接纳, 就插入就绪队列
- 进程的终止 过程:
- 根据终止的进程标识符, 检索 pcb
- 若进程处于运行态, 终止执行, 回收处理机资源
- 若进程有子进程, 终止子进程
- 回收资源
- 将 pcb 删除
- 进程阻塞
- 根据进程 uid 找到 pcb
- 若进程为运行态, 保护现场, 转为阻塞态
- 将 pcb 插入对应的等待队列, 回收处理机资源
- 进程唤醒
- 根据进程 uid 找到 pcb
- 从等待队列移出, 转为就绪态
- 将 pcb 插入就绪队列, 等待处理机资源
2.1.5 进程的通信(高级通信)
共享存储 在通信的进程之间存在一块可直接访问的共享空间, 对共享空间进行读写时需要同步互斥工具(PV 操作), 分为两种
- 基于数据结构的共享
- 基于存储区的共享
进程通常时不能访问其他进程的地址空间的, 实现共享存储需要特殊的系统调度 操作系统提供共享的存储空间和同步互斥工具, 数据交换由用户安排
消息传递 进程间数据交换以 message 消息为单位, 操作系统提供消息传递方法 进程使用两个原语进行消息传递: 发送消息, 接收消息
- 直接通信 发送进程把消息发给接受进程, 消息进入接受进程的消息缓冲队列
- 间接通信 发送进程把消息发送给某个中间实体(信箱), 接受进程从中间实体取得消息
管道通信 两个进程通过生产者消费者方式进行通信, 生产者从管道一端写, 消费者从管道一端读, 管道先进先出 为了协调通信, 管道机制必须具有: 互斥, 同步, 确定对方存在的能力 在 linux中, 管道可以克服使用文件通信的两个问题
- 限制管道的大小, 管道文件是一个固定大小的缓冲区, 大小一般为 4KB
- 读进程可能比写进程快, 当管道读空时, 读操作将被阻塞而不是结束通信
由于管道是一种特殊的文件, 子进程会继承父进程打开文件, 所以子进程继承父进程管道 管道的读是一次性的, 管道是单向的(双向需要两个管道)
2.1.6 线程和多线程模型
线程的概念: 为了减小程序在并发执行时付出的时空开销, 是一个基本的 cpu 执行单元, 是程序执行流的最小单元, 是被系统独立调度和分派的基本单位, 线程可与同进程的线程共享进程全部资源和地址空间 线程组成: 线程 id, 程序计数器, 寄存器集合, 堆栈 线程状态: 就绪, 阻塞, 运行
线程控制块内容: 线程标识符, 一组寄存器(PC, 状态寄存器, 通用寄存器), 程序运行状态, 优先级, 线程专有存储区(用于保护现场), 堆栈指针
通常线程被终止后不会立即释放资源, 只有当进程中的其他线程执行了分离函数后, 终止线程才与资源分离
线程的实现方式
用户级线程 ULT 线程管理在用户控件完成, 内核意识不到线程存在, 此时线程越多的进程中的线程执行的越慢(因为 cpu 调度进程, 线程多的进程平均每个线程分得的时间少) 优点:
- 线程切换不需要转换到内核空间
- 调度算法是进程专用的
- 线程实现和操作系统平台无关, 线程管理的代码是用户程序的一部分
缺点
- 当线程执行一个系统调用时, 所在进程的所有线程都会阻塞
- 不能发挥多处理机优势
内核级线程 KLT 线程管理工作在内核中实现 优点
- 能发挥多处理机优势
- 如果一个线程被阻塞, 可以调用其他线程
- 内核支持线程具有很小的数据结构和堆栈, 减小切换开销
- 内核本身可以采用多线程技术
缺点
- 切换开销大
组合方式 内核级线程对应多个用户级线程(用户线程时分复用内核级线程)
多线程模型: 用户线程和内核线程的连接方式
- 多个用户线程对应一个内核线程 一般为同一进程的多个用户线程, 线程调度管理在用户空间完成
- 一个用户线程对应一个内核线程
- n 个用户线程对应m个内核线程(n>m)
2.2 处理机调度
2.2.1 调度的概念
进程争夺处理机, 对处理机进行分配
调度的层次
高级调度(作业调度) 从外存上的后备队列的作业中挑选, 为他们分配内存等资源并建立进程, 进入就绪队列 是MM 与外存之间的调度
中级调度(内存调度)
将暂时不能运行的进程从 MM 调到外存等待, 此时称为挂起, 当可以运行并且MM 空闲时, 再从外存调入 MM, 并比导入就绪队列
低级调度(进程调度) 按照算法从就绪队列中选取进程
2.2.2 调度的目标
\(CPU利用率 = \frac{cpu有效工作时间}{cpu 有效工作时间+cpu 空闲时间}\)
系统吞吐量
\(周转时间 = 作业完成时刻-作业交给系统的时刻\)
\(带权周转时间 = \frac{作业周转时间}{作业实际运行时间}\)
等待时间: 进程处于等处理机的时间之和
响应时间: 提交请求时刻到系统响应时刻的时间
2.2.3 调度的实现
调度程序 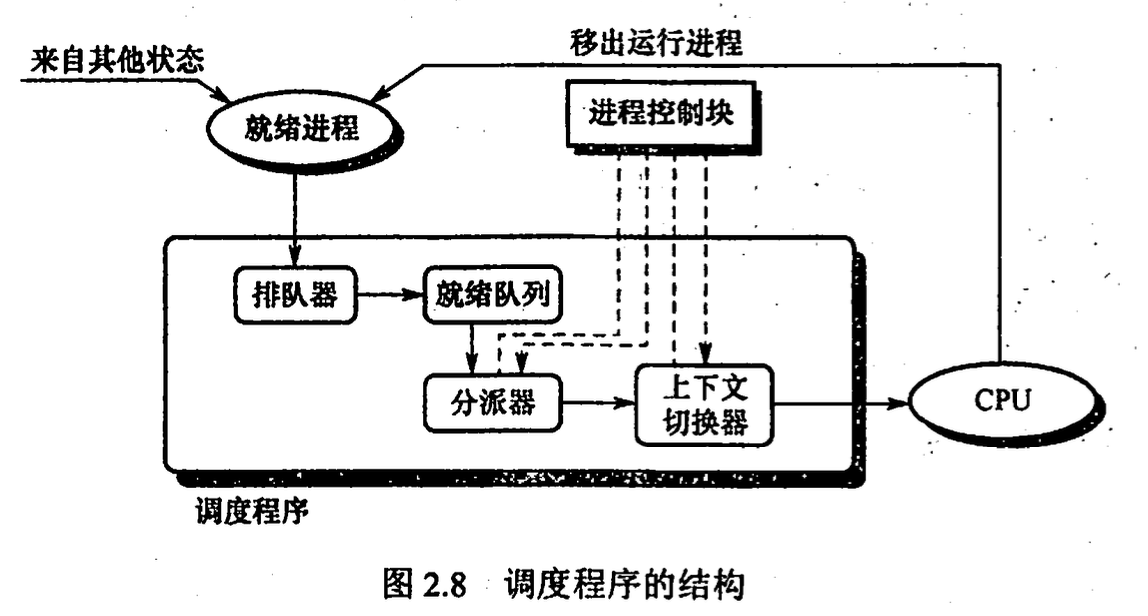
- 排队器: 将就绪进程插入相应就绪队列
- 分派器: 将 cpu 分配给进程
- 上下文切换器: 处理机进行切换时: 将当前进程上下文保存到其 pcb 中, 再将分派程序上下文装入处理机; 移出分派程序上下文, 将新进程上下文装入处理机
调度的时机
- 不能进行进程调度的时机
- 处理中断时: 逻辑上中断不属于某一进程
- 进程在操作系统内核临界区中: 加锁独占, 解锁前不应调度保证尽快释放临界区
- 其他需要完全屏蔽中断的原子操作时: 连中断都屏蔽, 进程调度也会停止
- 发生进程调度的时机
- 发生引起调度的条件而且当前进程无法继续进行时, 若操作系统只在这种情况调度, 称为非剥夺式调度
- 中断处理结束或自陷处理结束后, 返回执行现场前, 如果有请求标志马上进行进程调度, 若支持这种, 则实现了剥夺式调度
- 进程调度方式: 当有更高优先权的进程进入就绪队列该如何分配处理机
- 非剥夺式调度(非抢占调度): 在进程正在运行时, 若有更重要进程加入, 仍然继续执行直到阻塞
- 剥夺式调度(抢占调度): 根据某种原则暂停正在执行的进程
- 闲逛进程: 就绪队列空时执行闲逛进程(idle), 优先级最低, 不需要 cpu 以外的资源
- 两种线程调度:
- 用户级线程调度: 进程中的调度程序决定线程执行顺序
- 内核级线程调度: 内核选择执行的线程
2.2.4 典型的调度算法 (作业调度和进程调度)
先来先服务 FCFS 不可剥夺算法
短作业优先 SJF 容易饥饿(长作业不被调度) 未考虑紧迫程度 平均等待时间最少, 平均周转时间最少
优先级调度 分类
- 非抢占式 正在执行的不会被抢占
- 抢占式 立即停止被抢占
进程优先级
- 静态优先级: 进程优先级在进程创建时建立, 后保持不变
- 动态优先级: 运行过程中动态优先级
优先级设置原则
- 系统进程>用户进程
- 交互进程>非交互进程
- io 进程>计算进程
高响应比优先调度算法 主要用于作业调度
每次调度选择响应比最高的进程运行 \(响应比R_p = \frac{等待时间+要求服务时间}{要求服务时间}\)
综合了 FCFS 和 SJF
时间片轮转算法 按 FCFS 排序队列, 但每次只运行一个时间片, 运行完后置于队列末尾
多级队列调度算法 设置多个就绪队列, 每个队列使用不同调度方法
多级反馈队列调度算法 时间片轮转+优先级调度 实现:
- 设置多个就绪队列, 每个队列有不同优先级
- 每个队列的时间片大小不同, 优先级越高的队列时间片越小
- 每个队列都使用 FCFS, 如果一个时间片没执行完就放入优先级更低的队列的末尾
- 当优先级高的队列为空才调度优先级低的队列
2.2.5 进程切换
在内核中
上下文切换: 切换 cpu 到另一进程需要保存当前进程状态并且恢复另一进程状态 上下文: cpu 寄存器, 程序计数器
上下文切换流程
- 挂起进程, 保存上下文
- 更新 pcb
- 将 pcb 移到对应队列
- 选择另一进程执行, 更新 pcb
- 跳转到新pcb 的 pc 所指位置执行(?)
- 恢复处理机上下文
有些处理机有多个寄存器组, 这样上下文切换就只需要改变寄存器组指针
模式切换不是上下文切换, 上下文切换只能发生在内核态
2.3 同步与互斥
2.3.1 同步与互斥的基本概念
临界资源: 一次仅允许一个进程使用的资源 对临界资源的访问必须互斥进行 临界区: 访问临界资源的代码
do { |
同步: 多个进程协调工作次序
互斥(间接制约)
为了禁止两进程同时进入临界区, 同步机制需要以下准则:
- 空闲让进
- 忙则等待
- 有限等待: 保证在有限时间内可以进入临界区
- 让权等待: 当进程不能进入临界区时, 立即释放处理器
2.3.2 实现临界区互斥的基本方法
软件实现方法
单标志法 设置公共变量
int turn, turn的值为正在使用临界资源的进程 id// p0
while(turn!=0){} // wait for turn==0
critical section;
turn = 1;
remainder section;
// p1
while(turn!=1){}
critical section;
turn = 0;
remainder section;此方法违背了空闲让进原则, 如: p0 进入临界区后, 若p1 不进入临界区, p0 就无法再进入临界区
双标志法先检查
bool flag[], flag[i]==true 表示进程 pi 进入了临界区// pi
while(flag[j]){}
// all process may go into critical section
flag[i] = true;
critical section;
flag[i] = false;
remainder section;
// pj
while(flag[i]){}
// all process may go into critical section
flag[j] = true;
critical section;
flag[j] = false;
remainder section;可以连续进入, 但可能会同时进入临界区, 因为检查 flag 和切换自己的 flag 之间有一段时间
双标志位后检查
// pi
flag[i] = true;
// may dead lock
while(flag[j]){}
critical section;
flag[i] = false;
remainder section;
// pj
flag[j] = true;
// may dead lock
while(flag[i]){}
critical section;
flag[j] = false;
remainder section;可能发生死锁
peterson 算法 flag解决互斥访问, turn 解决死锁
// pi
flag[i] = true;
turn = j;
while(flag[j]&&turn==j){}
critical section;
flag[i] = false;
remainder section;
// pj
flag[j] = true;
turn = i;
while(flag[i]&&turn==i){}
critical section;
flag[j] = false;
remainder section;怎么理解变量turn呢?可以将turn变量理解成轮到谁进入临界区了。举个例子:turn = i,表示轮到Pi进入临界区。那么上面这个代码就可以理解为:首先,Pi想进入临界区(
flag[i] = True),然后,还是和前面的代码一样,Pi会先把进入临界区的机会让给Pj(turn = j),同样地,当Pj想进入临界区时,也会将进入临界区的权利先让给Pi。紧接着,变量turn的作用就显现出来了,当Pj把进入临界区的机会又让给Pi的时候(注意:这是发生在Pi将进入临界区的优先权让给Pj之后),Pi这次就会直接进入临界区。就不会再次出现一直互相谦让,最终导致均无法进入临界区的情况了。
硬件实现方法(低级方法, 元方法) 硬件方法进入临界区需要消耗处理机时间
中断屏蔽方法 cpu 只有在发生中断时进行进程切换, 屏蔽中断可以保证互斥
关中断;
临界区;
开中断;硬件指令
注意: 以下两条原子指令都是硬件逻辑直接实现, 不是软件定义
TestAndSet, 这条指令是原子操作, 读出 lock 值然后置为 truebool TestAndSet(bool *lock){
bool old = *lock;
*lock = true;
return old;
}每个临界资源有一个 lock 共享变量, lock==true 表示正在占用
while (TestAndSet(&lock)){}
critical section;
lock = falseSwap交换2个字的内容 每个临界资源有一个 lock 共享变量(初值为 false), 每一个进程有一个 key 局部变量key = true;
while(key!=false)
Swap(&lock, &key);
cirtical section;
lock = false;
2.3.3 互斥锁
bool available
acquire(){ |
获得锁和释放锁都是原子操作, 通常用硬件机制实现
但是可能忙等待: 一个进程在临界区时, 另一个进程必须循环获得锁, 浪费 cpu 周期
2.3.4 信号量
标准原语: P 操作(wait), V 操作(signal) 信号量的值表示相关资源当前可用量
整型信号量
P wait(S){
while (S<=0);
S=S-1;
}
V signal(S){
S=S+1;
}可能忙等
记录型信号量 除了信号量
value, 还有一个等待进程的链表list实现了让权等待typedef struct{
int value;
process* list;
}semaphore;
void wait(semaphore s){
s.value--;
if(s.value<0){
s.list.add(this process);
block(s.list);
}
}
void signal(semaphore s){
s.value++;
if(s.value<=0){
s.list.remove(p);
wakeup(p);
}
}信号量实现同步
semaphore s;
process1(){
do something;
V(s);
}
process2(){
P(s);
do something;
}信号量实现互斥
semaphore s = 1;
process1() {
P(s);
critical section;
V(s);
}
process2() {
P(s);
critical section;
V(s);
}信号量实现前驱关系
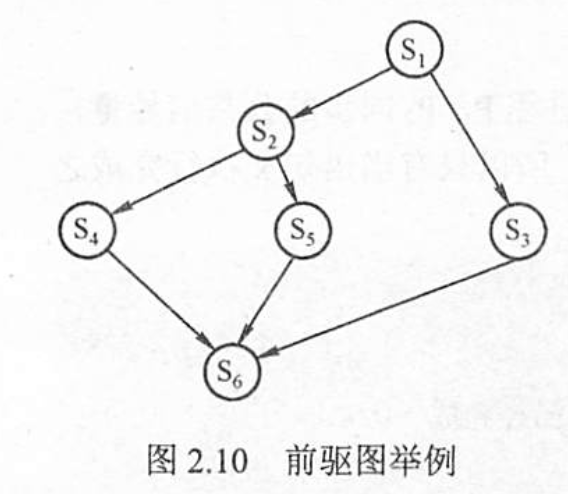
semaphore s12=s13=s24=s25=s36=s56=s36=0;
s1(){
V(s12);V(s13);
}
s2(){
P(s12);
V(s24);V(s25);
}
s3(){
P(s13);
V(s36);
}
s4(){
P(s24);
V(s46);
}
s5(){
P(s25);
V(s56);
}
s6(){
P(s36);P(s46);P(s56);
}
2.3.5 管程
管程定义了一个数据结构和能为并发进程所执行的一组操作
monitor Demo{ |
每次仅允许一个进程进入管程, 各个进程只能串行执行管程内的过程
条件变量 进程进入管程后如果因为条件变量 x 被阻塞, 每个条件变量 x 有一个等待队列
monitor Demo{ |
2.3.6 经典同步问题
生产者消费者
int buffer[MAX];
int fill = 0;
int use = 0;
void put(int value){
buffer[fill] = value;
fill = (fill+1)%MAX;
}
int get(){
int tmp = buffer[use];
use = (use+1)%MAX;
return tmp;
}
sem_t empty = MAX;
sem_t full = 0;
sem_t mutex = 1;
void *producer(void *arg){
int i;
for(i=0; i<loops; i++){
sem_wait(&empty);
sem_wait(&mutex);
put(i);
sem_post(&mutex);
sem_post(&full)
}
}
void *consumer(void *arg){
int i, tmp=0;
while (tmp!=-1)
{
sem_wait(&full);
sem_wait(&mutex);
tmp = get();
sem_post(&mutex);
sem_post(&empty);
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]){
sem_init(&empty, 0, MAX);
sem_init(&full, 0, 0);
sem_init(&mutex, 0, 1);
}读写问题
// read 进程优先
int reader_ct = 0;
semaphore mutex = 1; // reader_ct
semaphore rw = 1; // read write
void writer() {
while (1) {
P(rw);
writing;
V(rw);
}
}
void reader() {
while (1) {
P(mutex);
if (reader_ct == 0)
P(rw);
reader_ct++;
V(mutex);
reading;
P(mutex);
reader_ct--;
if (reader_ct == 0)
V(rw);
V(mutex);
}
}// write 进程优先
int reader_ct = 0;
semaphore mutex = 1; // reader_ct
semaphore rw = 1; // read write
semaphore w = 1; // write first
void writer() {
while (1) {
P(w);
P(rw);
writing;
V(rw);
V(w);
}
}
void reader() {
while (1) {
P(w);
P(mutex);
if (reader_ct == 0)
P(rw);
reader_ct++;
V(mutex);
V(w);
reading;
P(mutex);
reader_ct--;
if (reader_ct == 0)
V(rw);
V(mutex);
}
}哲学家进餐问题
semaphore chopsticks[5] = {1, 1, 1, 1, 1};
// may dead lock
void philosopher(int i) // 第 i 个哲学家
{
while(1){
P(chopsticks[i]);
P(chopsticks[(i+1)%5])
eat;
V(chopsticks[i]);
V(chopsticks[(i+1)%5]);
think;
}
}
// with mutex, no dead lock
semaphore mutex = 1;
void clever_philosopher(int i) // 第 i 个哲学家
{
while(1){
P(mutex);
P(chopsticks[i]);
P(chopsticks[(i+1)%5])
V(mutex);
eat;
V(chopsticks[i]);
V(chopsticks[(i+1)%5]);
think;
}
}吸烟者问题 问题描述:假设一个系统有三个抽烟者进程和一个供应者进程。每个抽烟者不停地卷烟并抽 掉它,但要卷起并抽掉一支烟,抽烟者需要有三种材料:烟草、纸和胶水。三个抽烟者中,第一 个拥有烟草,第二个拥有纸,第三个拥有胶水。供应者进程无限地提供三种材料,供应者每次将 两种材料放到桌子上,拥有剩下那种材料的抽烟者卷一根烟并抽掉它,并给供应者一个信号告诉 己完成,此时供应者就会将另外两种材料放到桌上,如此重复(让三个抽烟者轮流地抽烟)。
int num = 0;
semaphore mutex_paper_tab = 0;
semaphore mutex_tab_glue = 0;
semaphore mutex_glue_paper = 0;
semaphore finish = 1;
void all_provider() {
while (1) {
num++;
num %= 3;
if (num == 0)
v(mutex_paper_tab);
else if (num == 1)
v(mutex_glue_paper);
else
v(mutex_tab_glue);
p(finish);
}
}
void paper_provider(){
while(1){
p(mutex_tab_glue);
v(finish);
}
}
void tab_provider(){
while(1){
p(mutex_glue_paper);
v(finish);
}
}
void glue_provider(){
while(1){
p(mutex_paper_tab);
v(finish);
}
}
2.4 死锁
2.4.1 死锁的概念
死锁产生的原因:
- 系统资源竞争 对不可剥夺资源的竞争
- 进程推进顺序非法 请求和释放资源顺序不当
死锁产生的必要条件
- 互斥条件 资源具有排他性
- 不剥夺条件 资源不可剥夺
- 请求并保持 进程已经保持了一个资源, 又提出了新的资源请求
- 循环等待 存在进程资源的循环等待链
死锁处理
- 死锁预防
- 避免死锁
- 死锁检测和解除
2.4.2 死锁预防
- 破坏互斥条件 允许资源共享使用(有限)
- 破坏不剥夺条件 常用于易恢复保存的如 cpu 寄存器, 不适用于如打印机
- 破坏请求并保持条件 采用预先静态分配, 进程在运行前一次性申请完所需资源
- 破坏循环等待条件 顺序资源分配法, 给资源编号, 规定每个进程必须按编号递增顺序请求资源, 即申请了Ri, 就只能申请 Ri+n
2.4.3 死锁避免
系统安全状态 允许进程动态申请资源, 但系统在分配资源前应先计算此次分配的安全性 安全状态: 系统能按某种进程推进顺序, 为每个进程分配所需资源, 直至满足每个进程对资源的最大需求
银行家算法 进程运行前声明对资源的最大需求量, 申请资源时若超过最大需求量则不分配资源, 若未超过, 且不能按当前申请量分配资源, 则延迟分配 安全状态一定无死锁, 不安全状态不一定死锁, 不是预防死锁是避免死锁
const int m = 100; // 资源类数
const int n = 10; // 进程数
int available[m];
int demand_matrix[n][m];
int alloc_matrix[n][m];
int need_matrix[n][m];
// need_matrix = demand_matrix - alloc_matrix
int request[n][m];
int banker(int pro_i, int re_j) {
if (!(request[pro_i][re_j] <= need_matrix[pro_i][re_j]))
return -1;
if (!(request[pro_i][re_j] <= available[re_j]))
wait(pro_i);
try allocate : {
available[re_j] -= request[pro_i][re_j];
alloc_matrix[pro_i][re_j] += request[pro_i][re_j];
need_matrix[pro_i][re_j] -= request[pro_i][re_j];
}
check_is_safe();
}
void check_is_safe() {
int work[m] = available[m];
int safe_sequece[n];
while (safe_sequece.size() != n) {
find process in need_matrix, where process isnot in safe_sequece,
and need_matrix[process] <= work {
safe_sequece.add(process);
work = work + alloc_matrix[process];
}
}
}
2.4.4 死锁检测和解除
资源分配图
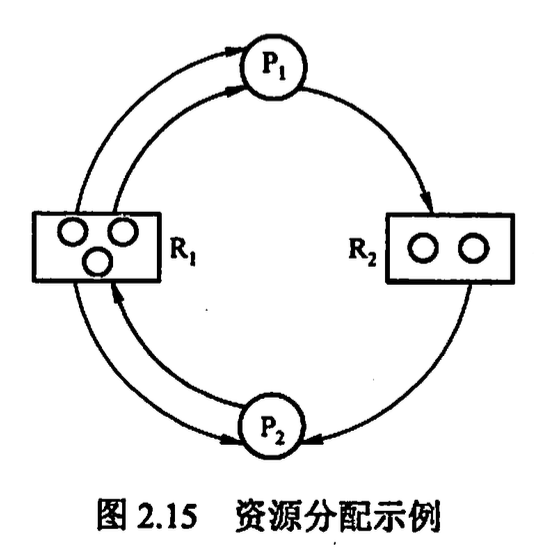
死锁定理 根据资源分配图判断死锁 空闲资源 = 资源数-出度 死锁条件为: 资源图不可完全简化(即边无法全部删除)
死锁解除
- 资源剥夺法
- 撤销进程法
- 进程回退法
鸽巢原理
若有n个笼子和kn+1只鸽子,所有的鸽子都被关在鸽笼里,那么至少有一个笼子有至少k+1只鸽子。
第3章 内存管理
3.1 内存管理概念
3.1.1 内存管理的基本原理和要求
内存管理的主要内容
- 内存空间的分配与回收
- 地址转换
- 内存空间扩充
- 内存共享
- 存储保护
程序的链接与装入
- 编译
- 链接
- 静态链接 程序运行前将模块及其库函数链接成完整模块
- 装入时动态链接 装入内存时边装入边链接
- 运行时动态链接
- 装入(内存)
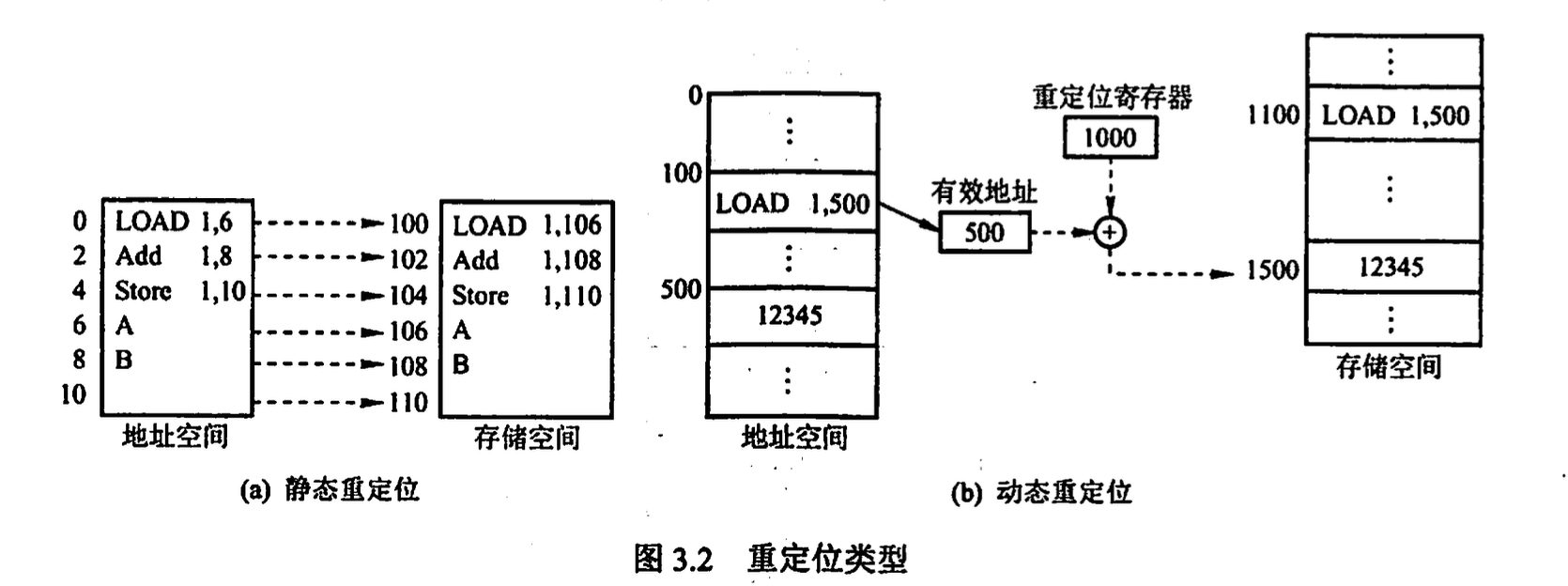
- 绝对装入 对于单道程序环境, 编译时知道程序在内存的绝对地址, 程序中的逻辑地址与实际内存地址相同, 不需要修改
- 可重定位装入 多道程序环境, 目标模块起始地址从 0 开始, 程序中的地址都是相对了起始地址的, 装入时对程序中的地址进行重定位(静态重定位), 装入时一次性完成地址变换
- 动态运行时装入 动态重定位, 地址转换推迟到运行时
进程的内存映像
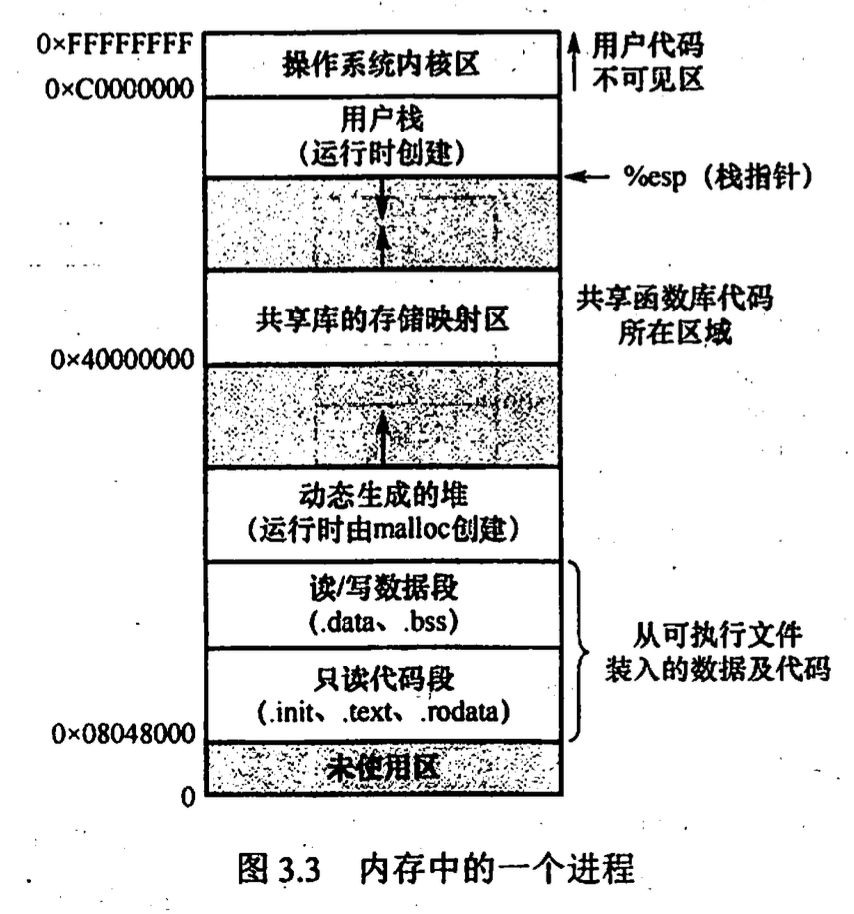
- 代码段: 只读
- 数据段: 静态变量, 全局变量
- PCB: 存放在系统区
- 堆栈
内存保护 保证每个进程有单独的内存空间, 进程之间不彼此影响
- cpu 中设置一对上下限寄存器, 存放作业在 MM 中的上限地址和下限地址, 当 CPU 访问地址时先判断是否越界
- 重定位寄存器(基地址寄存器)和界地址寄存器(限长寄存器) 重定位寄存器存放最小的物理地址值, 界地址寄存器存放逻辑地址的最大值 如果给定逻辑地址小于界地址寄存器, 则未越界, 加上重定位寄存器得到物理地址, 交给MM 加载这两个寄存器是特权指令
内存 共享 可重入代码(纯代码): 允许多个进程同时访问但不允许被任何进程修改的代码
内存分配与回收
*3.1.2 覆盖与交换
3.1.3 连续分配管理方式
- 单一连续分配 此方式下的内存分为系统区和用户区, 系统区一般在低地址, 整个内存仅有一道用户程序
- 固定分区分配 将用户控件划分为若干固定大小(大小相等或不等)区域, 每个分区装入一道作业, 通常有一检索表:
分区号, 大小, 起址, 分配状态会有碎片(内部碎片, 碎片在分区内), 大小可能不够容放 - 动态分区分配 随着时间推移会产生碎片(外部碎片), 这些碎片在分区外 外部碎片可以用紧凑技术解决, 即时不时对进程进行整理移动 动态分区分配算法
- 首次适应(first fit): 空闲分区按地址递增排序, 分配按地址顺序查找
- 临近适应(next fit, 循环首次适应): 分配内存从上次结束位置开始继续查找
- 最佳适应(best fit): 空闲分区按容量大小递增排序, 找到能满足要求且最小的空间分配 会产生很小的外部碎片
- 最坏适应(worst fit): 空闲分区按容量大小递减排序, 找到满足要求的最大的空间分配 会导致很快没有大内存块可用
3.1.4 基本分页存储管理
把 MM 空间划分为固定大小的块(page), 进程也是
进程中的叫页(页面)page, MM 中的叫页框(页帧) page frame, 外存中的叫块(盘块) block
virtual address |
页表, 页表寄存器 PTR(页表起始地址, 页表长度), TLB 快表 多级页表 如此进程的内存中就只需存放一级页表, 减小了页表所占空间
virtual address |
3.1.5 基本分段存储管理
3.1.6 段页式管理
3.2 虚拟内存管理
3.2.1 虚拟内存的基本概念
虚拟存储器特征
- 多次性: 无须一次性将整个作业装入内存, 可以分成多次导入内存, 是虚拟存储器的最重要特征
- 对换性: 允许将暂时不用的数据从内存换出到外存, 使用时再从外存换进到内存
- 虚拟性: 逻辑上扩充内存容量
硬件支持:
- 一定的内存外存
- 页表机制
- 中断机构
- 地址变换机构
3.2.2 请求分页管理方式
在请求分页系统中,只要求将当前需要的一部分页面装入内存,便可以启动作业运行。在作 业执行过程中,当所要访问的页面不在内存中时,再通过调页功能将其调入,同时还可通过置换 功能将暂时不用的页面换出到外存上,以便腾出内存空间。
请求页表项(和 page table 项有不同): key=virtual_page_number, physical_page_address, 状态位 P(是否已调入 MM), 访问字段 A(记录访问次数用于置换算法), 修改位 M(脏位), 外存地址(物理块号调入时使用)
缺页中断: 内部中断, 发生在指令执行时, 一条指令执行中可能发生多次缺页中断
3.2.3 页框分配
内存分配策略
固定分配局部置换 每个进程分配一定数量的物理块, 运行期间不改变, 发生缺页时进行置换 难以确定每个进程应该分配多少物理块
可变分配全局置换
每个进程分配一定数量的物理块, 运行期间适当改变, 发生缺页时从空闲物理块队列分配给该进程一块
可变分配局部置换
每个进程分配一定数量的物理块, 运行期间适当改变, 发生缺页时进行置换, 根据缺页频率增加或减少分配的物理块
固定分配的物理块调入算法
- 平均分配
- 按比例分配
- 优先权分配
调入页面时机
- 预调页策略: 根据空间局部性预测调入的页面
- 请求调页策略:仅在缺页时调入
请求分页系统的外存分为两部分: 存放文件的文件区; 存放对换页面的对换区 从何处将缺页调入 MM
- 系统有足够的对换空间: 从对换区
- 系统没有足够大对换空间: 凡是不会被修改的文件都直接从文件区调入;而当换出这 些页面时,由于它们未被修改而不必再将它们换出。但对于那些可能被修改的部分,在 将它们换出时须调到对换区,以后需要时再从对换区调入(因为读比写的速度快)。
- UNIX 方式: 与进程有关的文件都放在文件区,因此未运行过的页面都应从文件区调入。 曾经运行过但又被换出的页面,由于是放在对换区,因此在下次调入时应从对换区调入。 进程请求的共享页面若被其他进程调入内存,则无须再从对换区调入。
3.2.4 页面置换算法
最佳(OPT)置换算法 淘汰最长时间内不再被访问的页面, 该算法为理想算法无法实现
先进先出 FIFO, 会有 belady 异常, 缺页次数随分配的页框数增加而增加
LRU
时钟(clock)置换算法
简单的 clock 算法 每个页设置一个访问位, 当某页被替换时, 将替换指针设置为此页的下一页, 当需要淘汰时开始遍历, 如果访问位=1, 则置 0 继续遍历, 如果访问位=0 则直接淘汰
改进的 clock 算法 考虑到替换脏页代价更大, 设置修改位, 按顺序遍历四种页(修改位访问位两两组合)
由 访问位A 和 修改位M 可以组合成下面四种类型的页面:
1类(A=0, M=0):表示该页最近既未被访问,又未被修改,是最佳淘汰页。 2类(A=0, M=1):表示该页最近未被访问,但已被修改,并不是很好的淘汰页。 3类(A=1, M=0):最近已被访问, 但未被修改,该页有可能再被访问。 4类(A=1, M=1):最近已被访问且被修改,该页可能再被访问。
- 查找00,有,淘汰,算法结束!未找到,下一步;
- 查找01,有,淘汰,算法结束!未找到,下一步;(在查找过程中将A位复位为“0”)
- 重复第一步。
3.2.5 抖动和工作集
抖动: 刚换入的要换出, 刚换出的要换入
工作集: 某段时间间隔内进程要访问的页面集合 例如工作集窗口为 6, 进程访问页面序列如下: 1 3 4 5 6 0 3 2 3 2 则序列完毕后, 工作集为{6 0 3 2}
操作系统为进程分配大于工作集的物理块, 防止抖动
3.2.6 内存映射文件 memory-mapped files
将磁盘文件的部分或全部与进程虚拟地址空间的某个区域建立映射关系 都是在内存中发生的
3.2.7 虚拟存储器性能影响因素
缺页率
写回磁盘频率
3.2.8 地址翻译
第4章文件管理
4.1 文件系统基础
4.1.1 文件的基本概念
文件时用户输入输出的基本单位
文件组成: 存储空间, 标签和索引, 权限
4.1.2 文件控制块和索引结点
文件的属性:
- 名称
- 类型
- 创建者 id
- 所有者 id
- 位置(指针)
- 大小
- 保护
- 创建时间, 最后修改时间, 最后访问时间
文件控制块 FCB FCB 的有序集合叫文件目录, 一个文件目录也被视为一个文件称为目录文件, 文件目录通常存放在磁盘上, 查找目录时, 现将文件目录调入内存, 然后根据文件名逐一比较 FCB 主要包括:
- 基本信息: 文件名, 文件物理地址, 文件逻辑结构, 文件物理结构
- 存取控制信息: 存取权限
- 使用信息: 创建时间, 最后修改时间等
| Offset | Byte size | Contents |
|---|---|---|
| 0x00 | 1 | Drive number — 0 for default, 1 for A:, 2 for B:, ... |
| 0x01 | 8 | File name |
| 0x09 | 3 | and extension — together these form a 8.3 file name. |
| 0x0C | 20 | Implementation dependent — should be initialised to zero before the FCB is opened. |
| 0x20 | 1 | Record number in the current section of the file — used when performing sequential access. |
| 0x21 | 3 | Record number to use when performing random access. |
The 20-byte-long field starting at offset 0x0C contained fields which (among others) provided further information about the file:[2]
| Offset | Byte size | Contents |
|---|---|---|
| 0x0E | 2 | File's record length in bytes. |
| 0x10 | 4 | Total file size in bytes. |
| 0x14 | 2 | Date of last modification to file contents. |
| 0x16 | 2 | Time of last modification. |
索引结点 查找目录时只用到了文件名, 因此目录中的 entry 简化为文件名, 索引节点inode 的指针, 其中索引节点存放文件描述信息 索引节点分为两种, 磁盘索引节点和内存索引节点
4.1.3 文件的操作
基本操作
- 创建文件: 分配空间, 创建目录项
- 读写文件
- 文件定位: 在目录中搜索, 重定位文件指针
- 删除文件: 删除目录项, 释放空间
- 截断文件: 仅释放空间
文件 open close 操作系统维护一个 打开文件表 , 打开文件时将文件属性复制到打开文件表, 将打开文件表的索引返回给用户
系统打开文件表为每个文件关联一个打开计数器(open count) 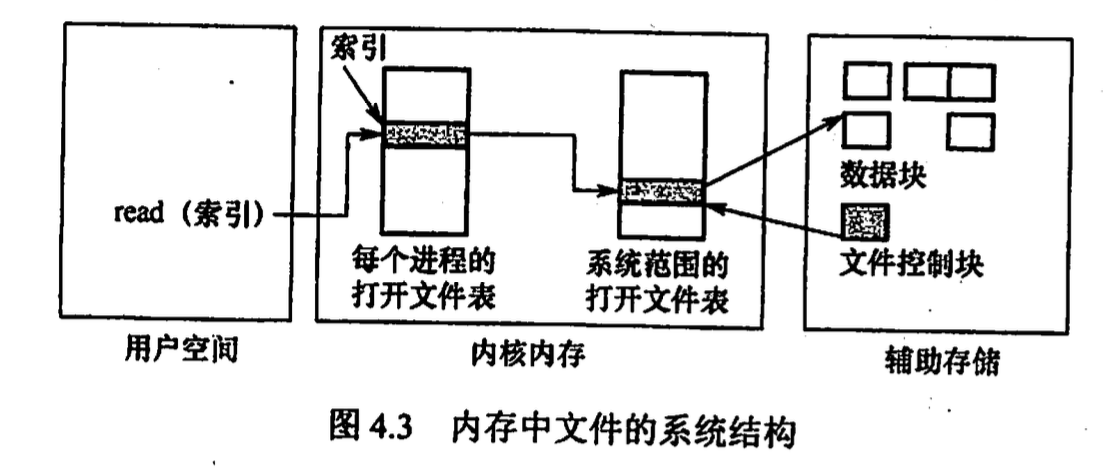
4.1.4 文件保护
访问控制 为每个文件和目录增加一个访问控制表 ACL(access-control list) 规定每个用户及其允许的访问类型 ACL 采用: 拥有者, 组, 其他 三个域表示用户权限
4.1.5 文件的逻辑结构
无结构文件(流式文件) 以 byte 为单位, 将数据按顺序组织
有结构文件(记录式文件)
顺序文件 文件中的记录通常定长, 按顺序排列
- 串结构, 检索必须按顺序依次查找
- 顺序结构, 按关键字排序, 可以折半查找
索引文件
根据索引表查找记录, 索引表项
索引号, 长度, 指针索引顺序文件 为顺序文件建立索引表, 索引表项
key, 逻辑地址散列文件 hash file 根据 key 和散列函数直接决定物理地址
4.1.6 文件的物理结构
- 连续分配 每个文件在磁盘上占有连续的块 但文件长度不宜动态增加, 插入删除困难, 可能产生外部碎片, 一般用于固定大小的文件
- 链接分配
- 隐式链接 目录中含有文件的第一块指针和最后一块指针, 每个盘块都有指向下一盘块的指针 可以将几个盘块组成簇(cluster)减少查找时间
- 显示链接 将所有块的指针都放在链接表中, 该表称为文件分配表 FAT(file allocation table) 根据目录在 FAT 中找到起始盘块, 然后自索引找到最后一块 每个磁盘块有一个 FAT 表 FAT 的每个表项存放下一个簇号
- 索引分配 将每个文件的所有盘块号集中到一个索引块表中, 缺点: 索引表需要占用空间
- 混合索引分配 为了同时适配大文件和小文件 采用多级索引
- 直接地址 <=40KB 在索引节点 inode 中直接存放盘块号
- 一次间接地址 <=4MB 在 inode 中有一次间接地址, 一个间接地址块可存放 1024 个盘块号
- 多次间接地址
4.2目录
4.2.1 目录的基本概念
4.2.2 目录结构
- 单级目录结构 一个文件系统一张目录表, 每个文件占一个目录项
- 两级目录结构 将文件目录分为主文件目录MFD(master file directory), 用户文件目录UFD(user file directory) MFD 中的项为 UFD, UFD 中的项为文件 FCB
- 树形目录结构 根据路径构造树结构, 如 linux 系统
- 无环图目录结构 在树形上实现了共享(不同路径能找到同一文件)
4.2.3 目录的操作
- 搜索
- 创建删除文件
- 创建删除目录
- 移动修改目录
- 显示目录
*4.2.4 目录实现
4.2.5 文件共享
- 基于索引节点 inode 的共享方式(硬链接) count 计数
- 利用符号链实现文件共享(软链接) link类型新文件, 新文件中只包含链接文件的路径名
软链接 count 复制, 硬链接 count+1 删除文件时, 对软链接不可见, 如果发现文件被删除则软连接直接删除 创建硬链接对软链接也不可见 对硬链接只会使 count-1, 如果 count!=0 则不会删除文件
4.3 文件系统
4.3.1 文件系统结构
- io 控制
- 向驱动发送命令, 管理内存缓冲
- 文件组织
4.3.2 文件系统布局
在磁盘中 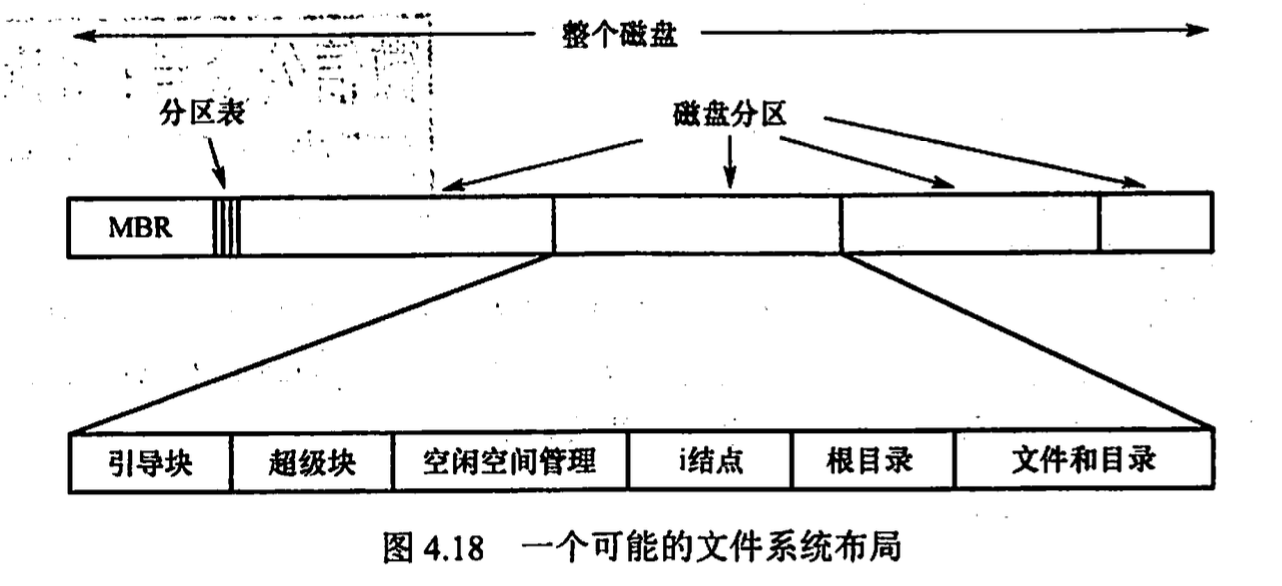
- 主引导记录 MBR(master boot record) 位手磁盘的0号扇区,MBR 后面是分区表,该表给出每个分区的起始和结束地址。 表中的一个分区被标记为活动分区,当计算机启动时,BIOS 读入并执行 MBR。MBR 做的第一件事是确定活动分区,读入它的第一块,即引导块。
- 引导块(boot block) 该块中的程序负责启动该分区中的操作系统 每个分区(即使不含操作系统)都以一个引导块开始
- 超级块(super block) 包含文件系统的所有关键信息, 在计算机启动或文件系统首次被使用时, 超级块被读入 MM, 其中的信息包括: 分区块的数量, 块的大小, 空闲块的数量和指针, 空闲 FCB 的数量和指针等
- 文件系统中空闲块的信息 可以使用位示图或指针链接的形式给出。后面也许跟的是一 组inode. 接着可能是根目录, 它存放文件系统目录树的根部。最后,磁盘的其他部分存放了其他所有的目录和文件。
在内存中
- 内存中的安装表(mount table) 包含每个已安装文件系统分区的有关信息。
- 内存中的目录结构的缓存包含最近访问目录的信息 对安装分区的目录,它可以包括一 个指向分区表的指针。
- 整个系统的打开文件表 包含每个打开文件的 FCB 副本及其他信息。
- 每个进程的打开文件表 包含一个指向整个系统的打开文件表中的适当条目的指针,以及其他信息。
文件创建读写流程 为了创建新的文件,应用程序调用逻辑文件系统。 它将为文件分配一个新的 FCB。 系统将相应的目录读入内存,使用新的文件名和 FCB 进行更新,并将它写回磁盘。 首先要打开文件。系统调用 open()将文件名传递给 逻辑文件系统。调用 open()首先搜索系统打开文件表,以确定这个文件是否已被其他进程使用。
- 如果己被使用,则在单个进程打开文件表中创建一个条目,让其指向系统打开文件表的相应条目。该算法在文件已打开时,能节省大量开销。
- 如果这个文件尚未打开,则根据文件名来搜素目录结构。(部分目录结构通常缓存在内存中以加快目录操作)找到文件后,它的 FCB 会复制到系统打开文件表中。该表不但存储FCB,而且跟踪打开该文件的进程的数量。 然后, 在单个进程的打开文件表中创建一个条目,并且通过指针将系统打开文件表的条目与其他域 (如文件当前位置的指针和文件访问模式等)相连。
调用 open()返回的是一个指向单个进程打开文件表中条目的指针。一旦文件被打开,内核就 不再使用文件名来访问文件,而使用文件描述符(Wiadows 称之为文件句柄)。 当进程关闭一个文件时,就会删除单个进程打开文件表中的相应条目,整个系统的打开文件 表的文件打开数量也会递减。当所有打开某个文件的用户都关闭该文件后,任何更新的元数据将 复制到磁盘的目录结构中,并且整个系统的打开文件表的对应条目也会被删除。
4.3.3 外存空闲空间管理
一个磁盘可以划分为4个分区, 每个分区都可以有单独的文件系统。 包含文件系统的分区通常称为卷(volume)。卷可以是磁盘的一 部分,也可以是整个磁盘,还可以是多个磁盘组成 RAID 集 在一个卷中,存放文件数据的空间(文件区)和FCB 的空间(目录区)是分离的。 卷在提供文件服务前,必须由对应的文件程序进行初始化,划分好目录区和文件区,建立空闲空间管理表格及存放卷信息的超级块。 文件存储设备的 管理实质上是对空闲块的组织和管理,它包括空闲块的组织、分配与回收等问题。 空闲块的管理方法
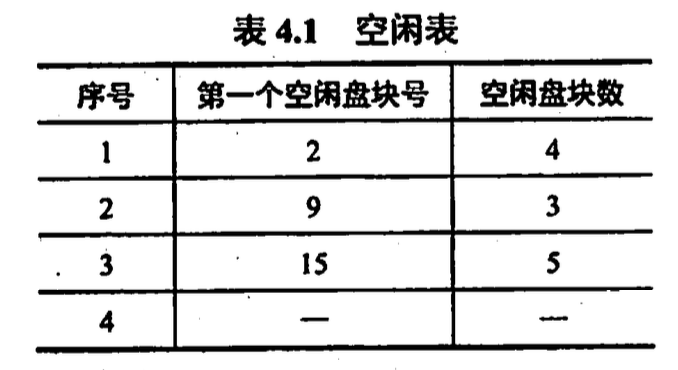
- 空闲表法 是一种连续分配法, 为每个文件分配一块连续的存储空间, 为外存的所有空闲区建一张空闲表
- 空闲链表法 将所有空闲盘区组成一个空闲链表, 根据构成链的元素分为
- 空闲盘块链 以盘块为单位组成链表
- 空闲盘区链 以盘区为单位组成链表
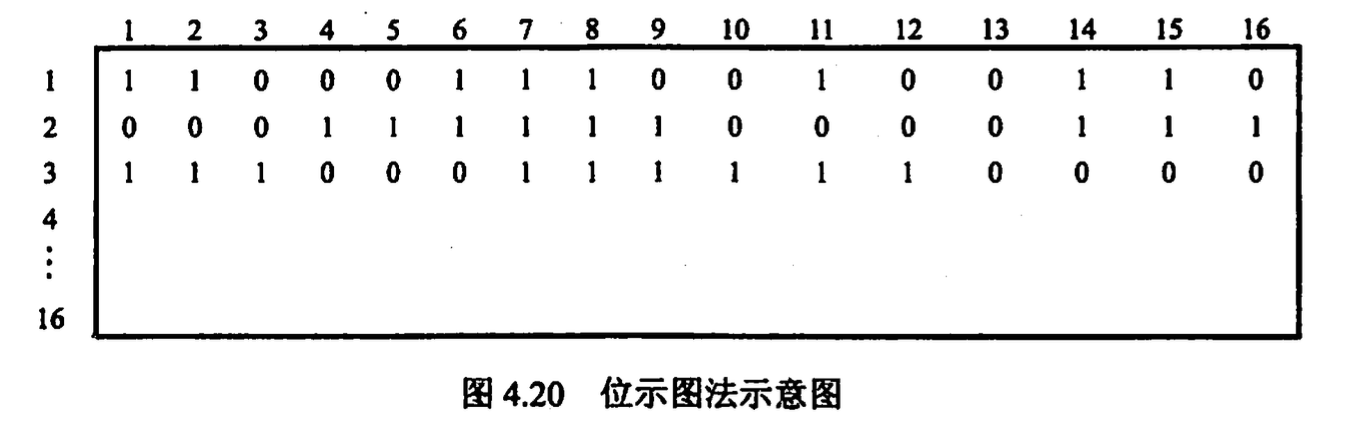
- 位示图 用一位二进制表示磁盘中一个盘块的使用情况 所有的二进制位组成一个表
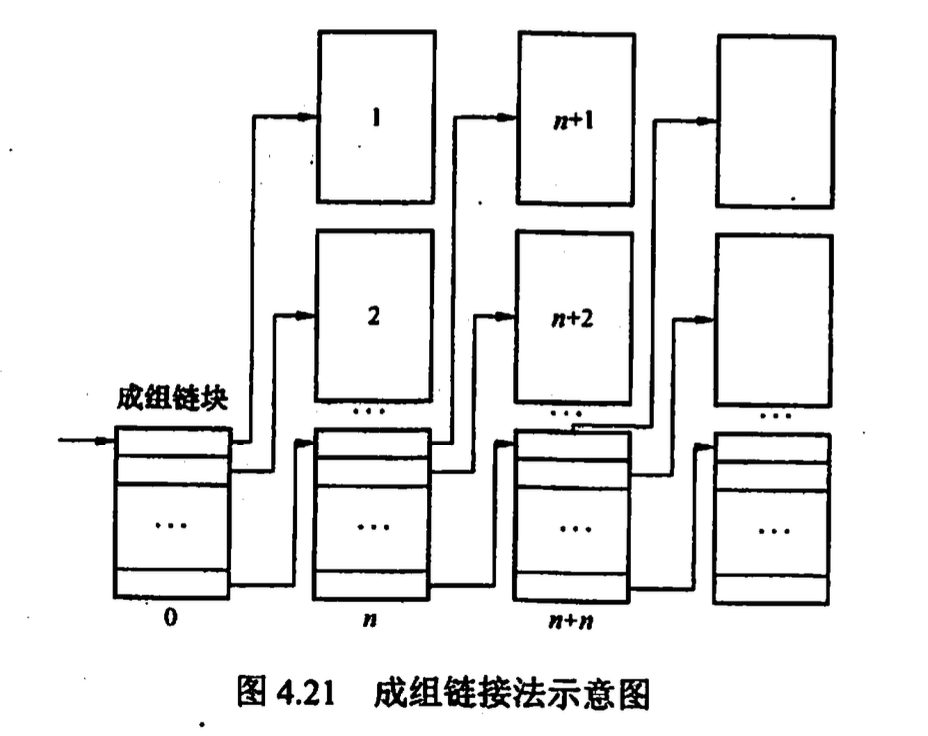
- 成组链接法 UNIX 使用, 结合空闲表和空闲链表 把顺序的n个空闲盘块号保存在第一个成组链块中,其最后一个空闲盘块(作为成组链块) 则用于保存另一组空闲盘块号 系统只需保存指向第 一个成组链块的指针
4.3.4 虚拟文件系统 VFS
linux 对 vfs 进行了以下抽象(数据结构)
- 超级块对象: 一个已安装的文件系统
- 索引节点对象: 一个文件
- 目录项对象: 一个目录项
- 文件对象: 一个与进程相关的已打开文件
4.3.5 分区和安装
4.4 文件系统的类型
磁盘文件系统
磁盘文件系统是一种设计用来利用数据存储设备来保存计算机文件的文件系统,最常用的数据存储设备是磁盘驱动器,可以直接或者间接地连接到计算机上。例如:档案配置表(FAT12、FAT16、FAT32、exFAT)、New Technology File System、分层档案系统HFS、HFS Plus、延伸档案系统(ext1、ext2、ext3、ext4)、ODS、btrfs、XFS、UFS、ZFS。有些文件系统是行程文件系统(也有译作日志文件系统)或者追踪文件系统。
闪存文件系统是一种设计用来在闪存上储存文件的文件系统。随着移动设备的普及和闪存容量的增加,这类文件系统越来越流行。
尽管磁盘文件系统也能在闪存上使用,但闪存文件系统是闪存设备的首选,理由如下:
- 擦除区块:闪存的区块在重新写入前必须先进行擦除。擦除区块会占用相当可观的时间。因此,在设备空闲的时候擦除未使用的区块有助于提高速度,而写入数据时也可以优先使用已经擦除的区块。
- 随机访问:由于在磁盘上寻址有很大的延迟,磁盘文件系统有针对寻址的优化,以尽量避免寻址。但闪存没有寻址延迟。
- 写入平衡(Wear levelling):闪存中经常写入的区块往往容易损坏。闪存文件系统的设计可以使数据均匀地写到整个设备。
日志文件系统具有闪存文件系统需要的特性,这类文件系统包括JFFS2和YAFFS。也有为了避免日志频繁写入而导致闪存寿命衰减的非日志文件系统,如exFAT。
第5章输入输出 (I/O)管理
5.1 I/O管理概述
5.1.1 I/O设备
io 设备分类
- 按信息交换单位
- 块设备: 以数据块为单位, 是有结构设备, 如磁盘, 可以随机读写
- 字符设备: 以字符为单位, 无结构, 如打印机, 不可寻址
- 按传输速率
- 低速: 键鼠
- 中速: 激光打印机
- 高速: 磁盘, 光盘
io 接口(设备控制器)组成
- 设备控制器与cpu的接口 包括数据线, 地址线, 控制线 数据线连接了数据寄存器和控制寄存器
- 设备控制器与设备的接口 一个设备控制器可以连接多个设备
- io 逻辑 用于对设备的控制, 对从 cpu 收到的 io 命令进行译码
设备控制器的功能
- 接收识别来自 cpu 的命令
- 数据交换
- 标识报告设备状态
- 地址识别
- 数据缓冲
- 差错控制
io 端口: 设备控制器中可被 cpu 直接访问的寄存器, 主要包括
- 数据寄存器
- 状态寄存器
- 控制寄存器
cpu 与 io 端口通信的方法
- 独立编址: 每个端口分配一个端口号
- 统一编址: 内存映射 io, 每个端口被分配唯一内存地址
5.1.2 I/O控制方式
程序直接控制方式 cpu 对外设状态进行循环检查 但 cpu 和 io 只能串行工作, cpu 利用率低
中断驱动方式 io 设备主动打断你 cpu 请求服务 但MM 和 io 设备传输的数据都要经过cpu
DMA 方式 开辟 io 设备和 MM 之间直接的数据通路
- 基本单位是数据块
- 传送数据从设备直接到内存
- 仅在传送的开始和结束需要 cpu 干预(数据块大小, 内存位置), 整个数据的传送由 dma 控制器控制
DMA 控制器中包括:
- 命令/状态寄存器 CR: 接收cpu 的 io 命令, 设备的控制信息, 设备状态
- 内存地址寄存器 MAR: 输入到内存的目标地址, 或者输入到设备的源地址
- 数据寄存器 DR: 暂存数据
- 数据计数器 DC: 存放要传输的字节数
通道控制方式 io channel io 通道是指专门负责输入输出的处理机, I/O通道通常由专门的硬件设备或芯片来实现,例如网络接口卡、磁盘控制器等
当 CPU 要完成一组相关的读(或写)操作及有关控制时,只需向 io 通道发送一条 io 指令,以给出其所要执行的通道程序的首地址和要访问的 io 设备,通道找到该指令后,执行 通道程序便可完成 CPU 指定的 io 任务,数据传送结束时向 CPU 发中断请求。 io 通道与一般处理机的区别是:通道指令的类型单一,没有自己的内存,通道所执行的通道程序是放在内存中的,通道与CPU 共享内存。 io 通道与 DMA 方式的区别是:通道方式中这些信息是由通道控制的。另外,每个DMA 控制器对应一台设备与内存 传递数据,而一个通道可以控制多台设备与内存的数据交换。
5.1.3 I/O 软件层次结构
- 用户层 io 软件 用户调用在用户层提供的库函数, 通过系统调用获取操作系统服务
- 设备独立性软件 使程序独立于具体使用的物理设备, 在驱动程序之上设置一层设备独立性软件, 其功能包括
- 执行所有设备的共有操作, 如分配回收, 逻辑设备到物理设备的映射, 缓冲, 差错控制
- 向用户层提供统一接口
- 设备驱动程序 与硬件直接相关, 是 io 进程与设备控制器之间的通信程序, 通常以进程形式存在
- 中断处理程序 进行上下文切换
5.1.4 应用程序 I/O 接口
根据设备类型分为以下接口
- 字符设备接口 以字符为单位, 不可寻址, 输入输出通常用中断方式
- 块设备接口 以块为数据单位, 通常采用 DMA 方式
- 网络设备接口 网络套接字接口
- 阻塞/非阻塞 io 操作系统大多数 io 接口是阻塞 io
5.2 设备独立性软件
5.2.1 与设备无关的软件
5.2.2 高速缓存与缓冲区
磁盘高速缓冲 disk cache 利用内存对磁盘进行缓冲, 有两种形式
- 在内存中开辟单独空间, 大小固定
- 把未利用的内存空间作为缓冲池, 供分页系统和磁盘 io 共享
缓冲区 buffer 缓冲的目的
- 缓和 cpu 与 io 之间的速度矛盾
- 减少对 cpu 的中断
- 解决数据粒度不匹配的问题
- 提高 cpu 与 io 设备的并行性
实现方法
- 硬件缓冲器
- 缓冲区(位于内存)
缓冲技术分类
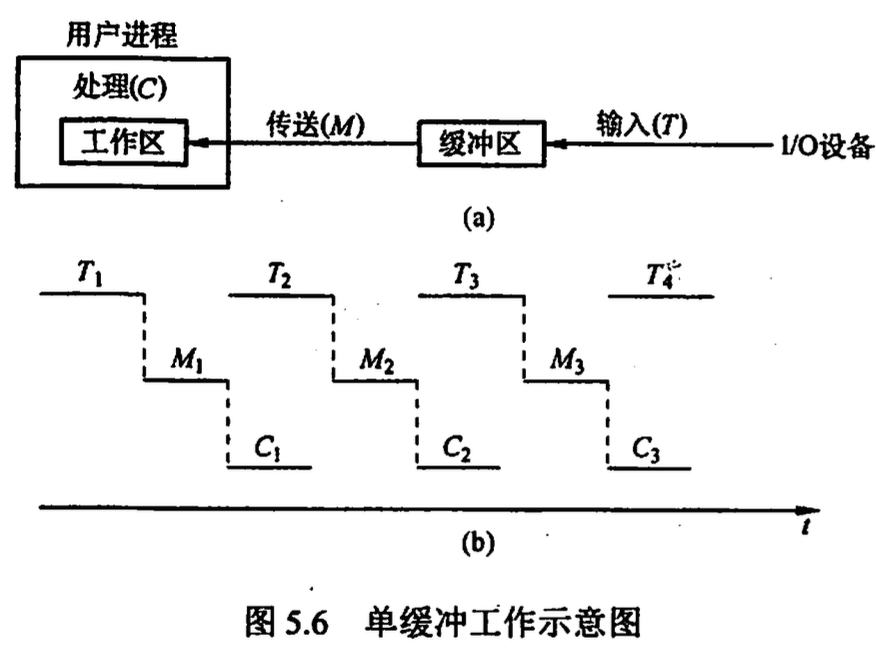
单缓冲 max(C, T) + M
双缓冲
max(C+M, T) 由于cpu 在 M 段处于空闲, 引入双缓冲 io 输入数据时先装填入缓冲 1, 缓冲 1 满后装入缓冲2, 此时缓冲 1 中数据已可以使用
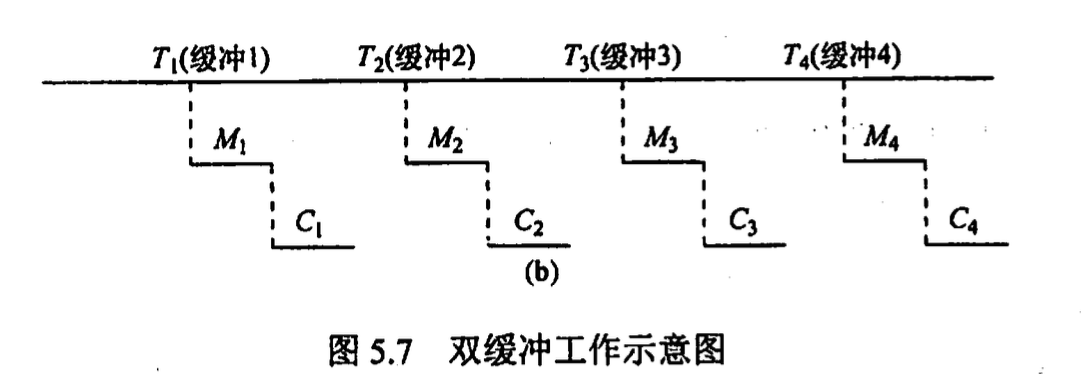
缓冲循环 设置多个大小相等缓冲区, 形成环形链表, in 指针指向第一个空缓冲区, out 指针指向第一个满缓冲区
缓冲池 多个系统公用缓冲区组成, 按使用状况形成三个队列: 空缓冲队列, 装满数据输入队列, 装满数据输出队列 当输入进程需要输入数据时,便从空缓冲队列的队首摘下一个空缓冲区,把它作为收容输入 工作缓冲区,然后把输入数据输入其中,装满后再将它挂到输入队列队尾。当计算进程需要输入 数据时,便从输入队列取得一个缓冲区作为提取输入工作缓冲区,计算进程从中提取数据,数据 用完后再将它挂到空缓冲队列尾。当计算进程需要输出数据时,便从空缓冲队列的队首取得一个 空缓冲区,作为收容输出工作缓冲区,当其中装满输出数据后,再将它挂到输出队列队尾。当要 输出时,由输出进程从输出队列中取得一个装满输出数据的缓冲区,作为提取输出工作缓冲区, 当数据提取完后,再将它挂到空缓冲队列的队尾。
5.2.3 设备分配与回收
设备按使用方式分为:
- 独占式使用设备: 进程分配到设备后独占, 直到进程释放该设备
- 分时式共享使用设备: 分时给多个进程同时使用
- 以 spooling 方式使用外部设备: 将设备同时分配给多个进程, 实质上是实现了对设备的 io 操作批处理
设备分配的数据结构:
- 设备控制表 DCT: 表项是设备的各个属性
设备类型, 设备标识符, 设备状态, 指向控制器表的指针, 重复执行次数或时间, 设备队列的队首指针 - 控制器控制表 COCT:
控制器标识符, 控制器状态, 与控制器连接的通道表指针, 控制器队列的队首指针, 控制器队列的队尾指针 - 通道控制表CHCT:
通道标识符, 通道状态, 与通道连接的控制器表首址, 通道队列的队首指针, 通道队列的队尾指针 - 系统设备表 SDT 整个系统只有一个 SDT 表, 记录所有物理设备的情况
设备类, 设备标识符, DCT, 驱动程序入口
设备分配的安全性: 设备分配中应防止死锁
逻辑设备名到物理设备名的映射 在系统中设置一张逻辑设备表 LUT (logical unit table), 将逻辑名映射为物理名 逻辑设备名, 物理设备名, 设备驱动程序入口地址
5.2.4 SPOOLing 技术(假脱机技术)
将独享设备改造成共享设备的技术 组成: 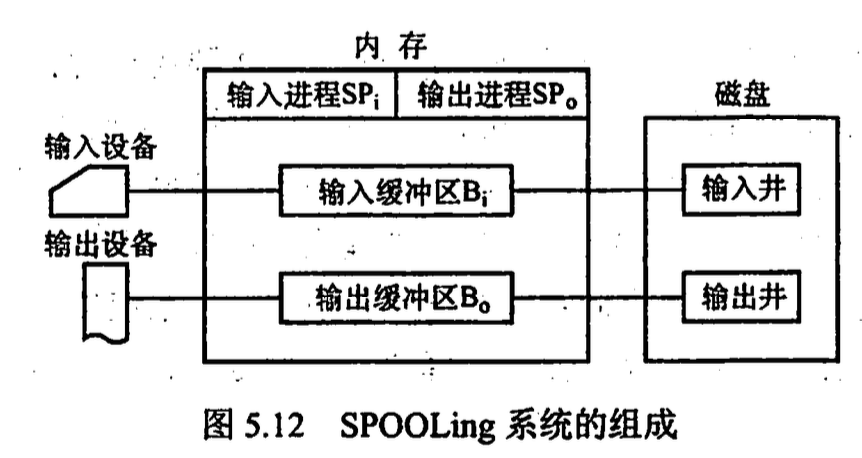
- 输入井输出井 输入井模拟脱机输入时的磁盘, 输出井模拟脱机输出时的磁盘
- 输入缓冲区输出缓冲区
- 输入进程输出进程
例如打印机, 用户进程请求打印输出时,SPOOLing 系统同意打印;但是并不真正立即把打印机分配给该进程,而由假脱机管理进程完成两项任务: 1)在磁盘缓冲区中为之申请一个空闲盘块,并将要打印的数据送入其中暂存。 2)为用户进程申请一张空白的用户请求打印表,并将用户的打印要求填入其中,再将该表挂到假脱机文件队列上。 这两项工作完成后,虽然还没有任何实际的打印输出,但是对于用户进程而言,其打印任务已经完成。对用户而言,系统并非立即执行真实的打印操作,而只是立即将数据输出到缓冲区,真正的打印操作是在打印机空闲且该打印任务已排在等待队列队首时进行的。
5.2.5 设备驱动程序接口
驱动程序中通常含有一张表格, 表格中具有针对这些函数指向驱动程序自身的指针
5.3 磁盘和固态硬盘
5.3.1 磁盘
5.3.2 磁盘的管理
- 磁盘初始化 存储数据前必须划分扇区使其能进行读写(低级格式化, 物理格式化)
- 分区 将磁盘分为由多个柱面组成的分区, 每个分区的信息记录在 MBR 的分区表中 对磁盘逻辑格式化(创建文件系统) 操作系统为提高效率将多个相邻扇区组合成簇cluster, 文件占用空间为 cluster 的整数倍
- 引导块 计算机启动需要自举程序(初始化程序) 自举程序通常存放在 ROM 中, 完整功能的引导程序放在磁盘的启动块上, 具有启动分区的磁盘称为启动磁盘或系统磁盘
- 坏块 损坏的扇区
5.3.3 磁盘调度算法
5.3.4 固态硬盘 SSD
操作系统历史
open shop
1954 IBM 701 open shop
手工操作
batch processing
BKS system
纸带, 磁带
multiprogramming
1960 Altas Supervisor
spooling 假脱机 (Spooling is a process in which data is temporarily held to be used and executed by a device, program or the system. Data is sent to and stored in memory or other volatile storage until the program or computer requests it for execution. "Spool" is technically an acronym for simultaneous peripheral operations online. For example, in printer spooling, the documents/files that are sent to the printer are first stored in the memory or printer spooler. Once the printer is ready, it fetches the data from that spool and prints it.)
demand paging(512words) (It suggests keeping all pages of the frames in the secondary memory until they are required. In other words, it says that do not load any page in the main memory until it is required.)
supervisor calls
programmed in machine language
1964 B5000 master control program
high-level language
stack instructions
virtual memory
multiprogramming multiprocessing
随意访存(unprotected)
1966 Exec II system
shortest job first
1966 Egdon system
timesharing
1963 CTSS
1964 Multics file system
hierarchical file system
1967 Titan file system
passwords
file authorization(execute read delete update)
1974 Unix
concurrent programming
1968 THE multiprogramming system
1969 RC 4000 multiprogramming system
concept of kernal: The system has no built-in assumptions about program scheduling and resource allocation; it allows any program to initiate other programs in a hierarchal manner.5 Thus, the system provides a general frame[work] for different scheduling strategies, such as batch processing, multiple console conversation, real-time scheduling, etc.
message communication
1972 Venus system
semaphores and layers of abstraction.
1975 Boss 2 system
1975 Solo system
concurrent pascal
1976 Solo program text
implemented in abstract data types(classes monitors processes)
易于修改
personal computer
1972 OS6
BCPL 语言






