cpp 从入门到汇编
简介: cpp 简要指北
mac 下的 c++ 头文件位置 /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX xx.xx.sdk/usr/include/c++
inline
When the program executes the function call instruction the CPU stores the memory address of the instruction following the function call, copies the arguments of the function on the stack and finally transfers control to the specified function. The CPU then executes the function code, stores the function return value in a predefined memory location/register and returns control to the calling function. This overhead occurs for small functions because execution time of small function is less than the switching time.
Inline function is a function that is expanded in line when it is called. When the inline function is called whole code of the inline function gets inserted or substituted at the point of inline function call. This substitution is performed by the C++ compiler at compile time. Inline function may increase efficiency if it is small. The syntax for defining the function inline is:
inline return-type function-name(parameters) |
Remember, inlining is only a request to the compiler, not a command. Compiler can ignore the request for inlining. Compiler may not perform inlining in such circumstances like: \1) If a function contains a loop. (for, while, do-while) \2) If a function contains static variables. \3) If a function is recursive. \4) If a function return type is other than void, and the return statement doesn’t exist in function body. \5) If a function contains switch or goto statement.
Inline functions provide following advantages: \1) Function call overhead doesn’t occur. \2) It also saves the overhead of push/pop variables on the stack when function is called. \3) It also saves overhead of a return call from a function. \4) When you inline a function, you may enable compiler to perform context specific optimization on the body of function. Such optimizations are not possible for normal function calls. Other optimizations can be obtained by considering the flows of calling context and the called context. \5) Inline function may be useful (if it is small) for embedded systems because inline can yield less code than the function call preamble and return.
Inline function disadvantages: \1) The added variables from the inlined function consumes additional registers, After in-lining function if variables number which are going to use register increases than they may create overhead on register variable resource utilization. This means that when inline function body is substituted at the point of function call, total number of variables used by the function also gets inserted. So the number of register going to be used for the variables will also get increased. So if after function inlining variable numbers increase drastically then it would surely cause an overhead on register utilization.
\2) If you use too many inline functions then the size of the binary executable file will be large, because of the duplication of same code.
\3) Too much inlining can also reduce your instruction cache hit rate, thus reducing the speed of instruction fetch from that of cache memory to that of primary memory.
\4) Inline function may increase compile time overhead if someone changes the code inside the inline function then all the calling location has to be recompiled because compiler would require to replace all the code once again to reflect the changes, otherwise it will continue with old functionality.
\5) Inline functions may not be useful for many embedded systems. Because in embedded systems code size is more important than speed.
\6) Inline functions might cause thrashing内存抖动 because inlining might increase size of the binary executable file. Thrashing in memory causes performance of computer to degrade.
Inline function and classes: It is also possible to define the inline function inside the class. In fact, all the functions defined inside the class are implicitly inline. Thus, all the restrictions of inline functions are also applied here. If you need to explicitly declare inline function in the class then just declare the function inside the class and define it outside the class using inline keyword. For example:
class S |
The above style is considered as a bad programming style. The best programming style is to just write the prototype of function inside the class and specify it as an inline in the function definition. For example:
class S |
What is wrong with macro?
C++ compiler checks the argument types of inline functions and necessary conversions are performed correctly. Preprocessor macro is not capable for doing this. One other thing is that the macros are managed by preprocessor and inline functions are managed by C++ compiler.
Remember: It is true that all the functions defined inside the class are implicitly inline and C++ compiler will perform inline call of these functions, but C++ compiler cannot perform inlining if the function is virtual. The reason is call to a virtual function is resolved at runtime instead of compile time. Virtual means wait until runtime and inline means during compilation, if the compiler doesn’t know which function will be called, how it can perform inlining?
整形提升 Integer Promotions
integer promotion is the implicit conversion of a value of any integer type with rank less or equal to rank of int or of a bit field of type _Bool, int, signed int, unsigned int, to the value of type int or unsigned int.
If int can represent the entire range of values of the original type (or the range of values of the original bit field), the value is converted to type int. Otherwise the value is converted to unsigned int.
Integer promotions preserve the value, including the sign:
thread
本篇主要对C++11中的线程std::thread作全面的梳理和总结,方便以后在工作中参考和使用。
1.std::thread介绍及示例
首先说明一下,对于以前的编译器, 若要使用C++11的特性,编译时要设定参数如下:
-std=c++11 |
这里先写一个简单的线程示例程序。
|
通过代码,我们创建了一个tt线程对象,其参数是函数thread_one,创建完成后被执行,tt.join()是等待子线程执行完成之后,主线程才继续执行,此时主线程会释放掉执行完成后的子线程的资源。
对于线程对象yy,我们传入了调用函数的两个参数,这里在线程yy执行时,主线程不想等待子线程,故使用了yy.detach()将子线程从主线程中分离出来,这样主线程就对子线程没有控制权了,子线程执行完成后会自己释放掉资源。
2.std::thread重要函数梳理
thread() noexcept:默认构造函数,创建一个空的
thread执行对象; explicit thread(Fn&&fn, Args&&...args):初始化构造函数,创建一个带函数调用参数的thread,这个线程是可joinable的; thread(const thread&) = delete:拷贝构造函数被禁用,意味着thread对象不可拷贝构造; thread(thread&& x) noexcept:移动构造函数,调用成功之后,x不代表任何thread执行对象;
其构造函数的使用示例如下:
|
3.thread中几个重要的成员函数
get_id():获取线程的ID,它将返回一个类型为std::thread::id的对象。joinable():检查线程是否可被join。
对于join这里值得注意:
在任意一个时间点上,线程是可结合joinable或者可分离detached的。一个可结合线程是可以被其它线程回收资源和杀死结束的,而对于detached状态的线程,其资源不能被其它线程回收和杀死,只能等待线程结束才能由系统自动释放。由默认构造函数创建的线程是不能被join的;另外,若某个线程已执行完任务,但是没有被join的话,该线程依然会被认为是一个活动的执行线程,因此是可以被join的。
detach():将当前线程对象所代表的执行实例与此线程对象分离,使得线程可以单独执行。swap():交换两个线程对象所代表的底层句柄,参数是两个线程对象;std::this_thread::getid():获取当前线程的ID;std::this_thread::yield():当前线程放弃执行,操作系统调度另一线程继续执行;sleep_until():线程休眠至某个指定的时刻,才被重新唤醒;sleep_for(): 线程休眠某个指定的时间片,才被重新唤醒;
4.thread中的互斥量
在多个线程同时访问共享资源时,就需要对资源进行加锁互斥访问,thread提供了四种不同的互斥量:
- 独占式互斥量:
std::mutex。独占工互斥量加解锁是成对的,同一个线程内独占式互斥量在没有解锁的情况下,再次对其加锁是不正确的,会得到一个未定义的行为。 - 递归式互斥量:
std::recursive_mutex。递归式互斥量是在同一个线程内互斥量没有解锁的情况下可以再次对其加锁,但其加解锁的次数需要保持一致。这种互斥量平时用得比较少。 - 允许超时的独占式互斥量:
std::timed_mutex - 允许超时的递归式互斥量:
std::recursive_timed_mutex
下面的代码示例了独占式互斥量的用法:
|
若线程1对共享资源的访问时间较长,这时线程2可能等不了那么久,故设定一个超时时间 ,在超时时间内若线程1中的互斥量还没有解锁,线程2就不等了,继续向下执行,这就是允许超时的互斥量。对于允许超时的互斥量,我们需要用unique_lock来包装。
下面代码示例了允许超时的互斥量的用法:
|
本文到此结束!
virtual function in compiling
three steps:
create vtb, declare vp, assign vp in constructor
The classes are (more or less) constructed as regular structs. The methods are (more or less...) converted into functions which first parameter is "this". References to the class variables are done as an offset to "this".
As far as inheritance, lets quote from the C++ FAQ LITE, which is mirrored here http://www.parashift.com/c++-faq-lite/virtual-functions.html#faq-20.4 . This chapter shows how Virtual functions are called in the real hardware (what does the compile make in machine code.)
Let's work an example. Suppose class Base has 5 virtual functions: virt0() through virt4().
// Your original C++ source code |
Step #1: the compiler builds a static table containing 5 function-pointers, burying that table into static memory somewhere. Many (not all) compilers define this table while compiling the .cpp that defines Base's first non-inline virtual function. We call that table the v-table; let's pretend its technical name is Base::__vtable. If a function pointer fits into one machine word on the target hardware platform, Base::__vtable will end up consuming 5 hidden words of memory. Not 5 per instance, not 5 per function; just 5. It might look something like the following pseudo-code(伪代码):
// Pseudo-code (not C++, not C) for a static table defined within file Base.cpp |
Step #2: the compiler adds a hidden pointer (typically also a machine-word) to each object of class Base. This is called the v-pointer. Think of this hidden pointer as a hidden data member, as if the compiler rewrites your class to something like this:
// Your original C++ source code |
Step #3: the compiler initializes this->__vptr within each constructor. The idea is to cause each object's v-pointer to point at its class's v-table, as if it adds the following instruction in each constructor's init-list:
Base::Base(...arbitrary params...) |
Now let's work out a derived class. Suppose your C++ code defines class Der that inherits from class Base. The compiler repeats steps #1 and #3 (but not #2). In step #1, the compiler creates a hidden v-table, keeping the same function-pointers as in Base::__vtable but replacing those slots that correspond to overrides. For instance, if Der overrides virt0() through virt2() and inherits the others as-is, Der's v-table might look something like this (pretend Der doesn't add any new virtuals):
// Pseudo-code (not C++, not C) for a static table defined within file Der.cpp |
In step #3, the compiler adds a similar pointer-assignment at the beginning of each of Der's constructors. The idea is to change each Der object's v-pointer so it points at its class's v-table. (This is not a second v-pointer; it's the same v-pointer that was defined in the base class, Base; remember, the compiler does not repeat step #2 in class Der.)
Finally, let's see how the compiler implements a call to a virtual function. Your code might look like this:
// Your original C++ code |
The compiler has no idea whether this is going to call Base::virt3() or Der::virt3() or perhaps the virt3() method of another derived class that doesn't even exist yet. It only knows for sure that you are calling virt3() which happens to be the function in slot #3 of the v-table. It rewrites that call into something like this:
// Pseudo-code that the compiler generates from your C++ |
I strongly recommend every C++ developer to read the FAQ. It might take several weeks (as it's hard to read and long) but it will teach you a lot about C++ and what can be done with it.
连续声明
Paddle* p1, * p2; |
指针!
class and typename
in template they are the same
template<typename T> /* class or function declaration */;
template<class T> /* class or function declaration */;typename unique
由于 C++ 允许在类内定义类型别名,且其使用方法与通过类型名访问类成员的方法相同。故而,在类定义不可知的时候,编译器无法知晓类似
Type::foo的写法具体指的是一个类型还是类内成员。class unique
?
class memory layout
Elements in Class
- Member variables
- Member function
- Static member variable
- Static member function
- Virtual function
- Pure virtual function
Factors affecting object size
- Member variables
- **Virtual function table pointer (_vftptr)**
- **Virtual base table pointer**(_vbtptr)****
- Memory alignment
A plain (non virtual) member function is just like a C function (except that it has this as an implicit, often first, parameter). For example your getA method is implemented like the following C function (outside of the object, e.g. in the code segment of the binary executable) :
A virtual member function is generally implemented thru a vtable (virtual method table). An object with some virtual member functions (including destructor) has generally as its first (implicit) member field a pointer to such a table (generated elsewhere by the compiler).
Single class
(1). Empty class

sizeof(CNull)=1(Used to identify the object)
(2). Class with only member variables

int nVarSize = sizeof(CVariable) = 12

Memory layout:

(3). Classes with only virtual functions

int nVFuntionSize = sizeof(CVFuction) = 4 (virtual table pointer)

Memory layout:

(4). Classes with member variables and virtual functions

int nParentSize = sizeof(CParent) = 8

Memory layout:

Single inheritance
(including member variables, virtual functions, and virtual function coverage)

int nChildSize = sizeof(CChildren) = 12
The result displayed in vc (Note: There is also a virtual function CChildren::g1 that is not displayed):

Memory layout:

Multiple inheritan
(including member variables, virtual functions, and virtual function coverage)

int nChildSize = sizeof(CChildren) = 20
The result displayed in vc (Note: There are two virtual functions CChildren::f2, CChildren::h2 is not displayed,this Pointer adjustor[Adjusted value] Did not print out):

Memory layout:

Inheritance with a depth of 2
(including member variables, virtual functions, and virtual function coverage)

int nGrandSize = sizeof(CGrandChildren) = 24
The result displayed in vc (note: there are three virtual functions CGrandChildren::f2, CChildren::h2, CGrandChildren::f3 are not displayed,thisPointeradjustor[Adjusted value] Did not print out):

Memory layout:

Repeated inheritance
(including member variables, virtual functions, and virtual function coverage)

int nGrandSize = sizeof(CGrandChildren) = 28

Memory layout:

Since there are two copies of m_nAge in the content, we cannot directly access this variable through pGrandChildrenA->m_nAge,
There will be ambiguity in this way, the compiler cannot know that it should accessCChildren1M_nAge in, orCChildren2M_nAge in.
In order to identify the unique m_nAge, you need to bring the class name of its scope. as follows:
1 pGrandChildrenA->CChildren1::m_nAge = 1; |
Single virtual inheritance
The diamond problem(what is virtual inheritance)
Virtual inheritance is a C++ technique that ensures that only one copy of a base class’s member variables are inherited by second-level derivatives (a.k.a. grandchild derived classes). Without virtual inheritance, if two classes B and C inherit from class A, and class D inherits from both B and C, then D will contain two copies of A’s member variables: one via B, and one via C. These will be accessible independently, using scope resolution.
Instead, if classes B and C inherit virtually from class A, then objects of class D will contain only one set of the member variables from class A.
As you probably guessed, this technique is useful when you have to deal with multiple inheritance and it’s a way to solve the infamous diamond inheritance.
(including member variables, virtual functions, and virtual function coverage)

int nChildSize = sizeof(CChildren) = 20
Memory layout:

Multiple virtual inheritance
(including member variables, virtual functions, and virtual function coverage)
- virtual CParent1, CParent2

int nChildSize = sizeof(CChildren) = 24
Memory layout:

- CParent1, virtual CParent2

int nChildSize = sizeof(CChildren) = 24
Memory layout:

- virtual CParent1, virtual CParent2

int nChildSize = sizeof(CChildren) = 28
Memory layout:

Diamond virtual multiple inheritance
(including member variables, virtual functions, and virtual function coverage)

int nGrandChildSize = sizeof(CGrandChildren) = 36
Memory layout:

sizeof
Depending on the computer architecture, a byte may consist of 8 or more bits, the exact number being recorded in CHAR_BIT.
sizeof(empty object) = 1
The following sizeof expressions always evaluate to 1:
- sizeof(char)
- sizeof(signed char)
- sizeof(unsigned char)
|
uml

+表示 public |
单向箭头关联 A-->B, A 有 B 类型的指针
虚线箭头依赖 A~~>B, A 依赖于 B
实心箭头组合 A<*>-->B, A 中有(聚合了) B, 且 B 不能独立于 A
空心箭头聚合 A◇-->B, A 中有(聚合了) B, B 能独立于 A
空心箭头继承 A--|>B, A 继承自 B
虚线空心箭头 A~~|>B, A 实现了 B 的接口
initialization
Depending on context, the initializer may invoke:
Value initialization, e.g. std::string s{}; This is the initialization performed when an object is constructed with an empty initializer.
struct T1
{
int mem1;
std::string mem2;
}; // implicit default constructor
struct T2
{
int mem1;
std::string mem2;
T2(const T2&) { } // user-provided copy constructor
}; // no default constructor
struct T3
{
int mem1;
std::string mem2;
T3() { } // user-provided default constructor
};
std::string s{}; // class => default-initialization, the value is ""
int main()
{
int n{}; // scalar => zero-initialization, the value is 0
double f = double(); // scalar => zero-initialization, the value is 0.0
int* a = new int[10](); // array => value-initialization of each element
// the value of each element is 0
T1 t1{}; // class with implicit default constructor =>
// t1.mem1 is zero-initialized, the value is 0
// t1.mem2 is default-initialized, the value is ""
// T2 t2{}; // error: class with no default constructor
T3 t3{}; // class with user-provided default constructor =>
// t3.mem1 is default-initialized to indeterminate value
// t3.mem2 is default-initialized, the value is ""
std::vector<int> v(3); // value-initialization of each element
// the value of each element is 0
delete[] a;
}Direct initialization, e.g. std::string s("hello"); Initializes an object from explicit set of constructor arguments.
struct Foo {
int mem;
explicit Foo(int n) : mem(n) {}
};
int main()
{
std::string s1("test"); // constructor from const char*
std::string s2(10, 'a');
std::unique_ptr<int> p(new int(1)); // OK: explicit constructors allowed
// std::unique_ptr<int> p = new int(1); // error: constructor is explicit
Foo f(2); // f is direct-initialized:
// constructor parameter n is copy-initialized from the rvalue 2
// f.mem is direct-initialized from the parameter n
// Foo f2 = 2; // error: constructor is explicit
std::cout << s1 << ' ' << s2 << ' ' << *p << ' ' << f.mem << '\n';
}Copy initialization, e.g. std::string s = "hello"; Initializes an object from another object.
struct A
{
operator int() { return 12;}
};
struct B
{
B(int) {}
};
int main()
{
std::string s = "test"; // OK: constructor is non-explicit
std::string s2 = std::move(s); // this copy-initialization performs a move
// std::unique_ptr<int> p = new int(1); // error: constructor is explicit
std::unique_ptr<int> p(new int(1)); // OK: direct-initialization
int n = 3.14; // floating-integral conversion
const int b = n; // const doesn't matter
int c = b; // ...either way
A a;
B b0 = 12;
// B b1 = a; // < error: conversion from 'A' to non-scalar type 'B' requested
B b2{a}; // < identical, calling A::operator int(), then B::B(int)
B b3 = {a}; // <
auto b4 = B{a}; // <
// b0 = a; // < error, assignment operator overload needed
}List initialization, e.g. std::string s{'a', 'b', 'c'}; Initializes an object from braced-init-list.
struct Foo {
std::vector<int> mem = {1,2,3}; // list-initialization of a non-static member
std::vector<int> mem2;
Foo() : mem2{-1, -2, -3} {} // list-initialization of a member in constructor
};
std::pair<std::string, std::string> f(std::pair<std::string, std::string> p)
{
return {p.second, p.first}; // list-initialization in return statement
}
int main()
{
int n0{}; // value-initialization (to zero)
int n1{1}; // direct-list-initialization
std::string s1{'a', 'b', 'c', 'd'}; // initializer-list constructor call
std::string s2{s1, 2, 2}; // regular constructor call
std::string s3{0x61, 'a'}; // initializer-list ctor is preferred to (int, char)
int n2 = {1}; // copy-list-initialization
double d = double{1.2}; // list-initialization of a prvalue, then copy-init
auto s4 = std::string{"HelloWorld"}; // same as above, no temporary created since C++17
std::map<int, std::string> m = { // nested list-initialization
{1, "a"},
{2, {'a', 'b', 'c'} },
{3, s1}
};
std::cout << f({"hello", "world"}).first // list-initialization in function call
<< '\n';
const int (&ar)[2] = {1,2}; // binds a lvalue reference to a temporary array
int&& r1 = {1}; // binds a rvalue reference to a temporary int
// int& r2 = {2}; // error: cannot bind rvalue to a non-const lvalue ref
// int bad{1.0}; // error: narrowing conversion
unsigned char uc1{10}; // okay
// unsigned char uc2{-1}; // error: narrowing conversion
Foo f;
std::cout << n0 << ' ' << n1 << ' ' << n2 << '\n'
<< s1 << ' ' << s2 << ' ' << s3 << '\n';
for(auto p: m)
std::cout << p.first << ' ' << p.second << '\n';
for(auto n: f.mem)
std::cout << n << ' ';
for(auto n: f.mem2)
std::cout << n << ' ';
}Aggregate initialization, e.g. char a[3] = {'a', 'b'}; Initializes an aggregate from braced-init-list.
struct S {
int x;
struct Foo {
int i;
int j;
int a[3];
} b;
};
int main()
{
S s1 = { 1, { 2, 3, {4, 5, 6} } };
S s2 = { 1, 2, 3, 4, 5, 6}; // same, but with brace elision 括号省略
S s3{1, {2, 3, {4, 5, 6} } }; // same, using direct-list-initialization syntax
S s4{1, 2, 3, 4, 5, 6}; // error until CWG 1270:
// brace elision only allowed with equals sign
int ar[] = {1,2,3}; // ar is int[3]
int ab[] (1, 2, 3); // (C++20) ab is int[3]
// char cr[3] = {'a', 'b', 'c', 'd'}; // too many initializer clauses
char cr[3] = {'a'}; // array initialized as {'a', '\0', '\0'}
int ar2d1[2][2] = {{1, 2}, {3, 4}}; // fully-braced 2D array: {1, 2}
// {3, 4}
int ar2d2[2][2] = {1, 2, 3, 4}; // brace elision: {1, 2}
// {3, 4}
int ar2d3[2][2] = {{1}, {2}}; // only first column: {1, 0}
// {2, 0}
std::array<int, 3> std_ar2{ {1,2,3} }; // std::array is an aggregate
std::array<int, 3> std_ar1 = {1, 2, 3}; // brace-elision okay
// int ai[] = { 1, 2.0 }; // narrowing conversion from double to int:
// error in C++11, okay in C++03
std::string ars[] = {std::string("one"), // copy-initialization
"two", // conversion, then copy-initialization
{'t', 'h', 'r', 'e', 'e'} }; // list-initialization
union U {
int a;
const char* b;
};
U u1 = {1}; // OK, first member of the union
// U u2 = { 0, "asdf" }; // error: too many initializers for union
// U u3 = { "asdf" }; // error: invalid conversion to int
[](auto...) { std::puts("Garbage unused variables... Done."); } (
s1, s2, s3, s4, ar, ab, cr, ar2d1, ar2d2, ar2d3, std_ar2, std_ar1, u1
);
}
// aggregate
struct base1 { int b1, b2 = 42; };
// non-aggregate
struct base2 {
base2() : b3(42) {}
int b3;
};
// aggregate in C++17
struct derived : base1, base2 { int d; };
derived d1{ {1, 2}, { }, 4}; // d1.b1 = 1, d1.b2 = 2, d1.b3 = 42, d1.d = 4
derived d2{ { }, { }, 4}; // d2.b1 = 0, d2.b2 = 42, d2.b3 = 42, d2.d = 4Reference initialization, e.g. char& c = a[0]; Binds a reference to an object.
struct S {
int mi;
const std::pair<int, int>& mp; // reference member
};
void foo(int) {}
struct A {};
struct B : A {
int n;
operator int&() { return n; }
};
B bar() { return B(); }
//int& bad_r; // error: no initializer
extern int& ext_r; // OK
int main() {
// Lvalues
int n = 1;
int& r1 = n; // lvalue reference to the object n
const int& cr(n); // reference can be more cv-qualified
volatile int& cv{n}; // any initializer syntax can be used
int& r2 = r1; // another lvalue reference to the object n
// int& bad = cr; // error: less cv-qualified
int& r3 = const_cast<int&>(cr); // const_cast is needed
void (&rf)(int) = foo; // lvalue reference to function
int ar[3];
int (&ra)[3] = ar; // lvalue reference to array
B b;
A& base_ref = b; // reference to base subobject
int& converted_ref = b; // reference to the result of a conversion
// Rvalues
// int& bad = 1; // error: cannot bind lvalue ref to rvalue
const int& cref = 1; // bound to rvalue
int&& rref = 1; // bound to rvalue
const A& cref2 = bar(); // reference to A subobject of B temporary
A&& rref2 = bar(); // same
int&& xref = static_cast<int&&>(n); // bind directly to n
// int&& copy_ref = n; // error: can't bind to an lvalue
double&& copy_ref = n; // bind to an rvalue temporary with value 1.0
// Restrictions on temporary lifetimes
std::ostream& buf_ref = std::ostringstream() << 'a'; // the ostringstream temporary
// was bound to the left operand of operator<<
// but its lifetime ended at the semicolon
// so buf_ref is a dangling reference
S a {1, {2, 3} }; // temporary pair {2, 3} bound to the reference member
// a.mp and its lifetime is extended to match
// the lifetime of object a
S* p = new S{1, {2, 3} }; // temporary pair {2, 3} bound to the reference
// member p->mp, but its lifetime ended at the semicolon
// p->mp is a dangling reference
delete p;
}
types in cpp
Object types
Scalars scalars are primitive objects which contain a single value and are not composed of other C++ objects.
arithmetic (integral, float)
pointers:
T *for any typeTenum
pointer-to-member
nullptr_tvoid f(std::nullptr_t nullp)
{
// Passed a null pointer
}
Arrays:
T[]orT[N]for any complete, non-reference typeTClasses:
class Fooorstruct Bar- Trivial classes
- Aggregates
- POD classes
- (etc. etc.)
Unions:
union Zip
References types:
T &,T &&for any object or free-function typeTFunction types
- Free functions:
R foo(Arg1, Arg2, ...) - Member functions:
R T::foo(Arg1, Arg2, ...)
- Free functions:
void
POD-classes, POD-unions, scalar types, and arrays of such types are collectively called POD-types.
aggregates and POD(plain old data)
c++03
An aggregate is
- an array or
- a class (clause 9) with no user-declared constructors (12.1), no private or protected non-static data members (clause 11), no base classes (clause 10), and no virtual functions (10.3).
- An aggregate class can have a user-declared/user-defined copy-assignment operator and/or destructor
- An array is an aggregate even if it is an array of non-aggregate class type.
- This does not mean an aggregate class cannot have constructors, in fact it can have a default constructor and/or a copy constructor as long as they are implicitly declared by the compiler, and not explicitly by the user
aggregate feature
They, unlike non-aggregate classes, can be initialized with curly braces
{}.We should understand that memberwise initialization with braces implies that the class is nothing more than the sum of its members.
POD
A POD-struct is an aggregate class that has no non-static data members of type non-POD-struct, non-POD-union (or array of such types) or reference, and has no user-defined copy assignment operator and no user-defined destructor. Similarly, a POD-union is an aggregate union that has no non-static data members of type non-POD-struct, non-POD-union (or array of such types) or reference, and has no user-defined copy assignment operator and no user-defined destructor. A POD class is a class that is either a POD-struct or a POD-union.
An aggregate class is called a POD if it has no user-defined copy-assignment operator and destructor and none of its nonstatic members is a non-POD class, array of non-POD, or a reference.
c++11
A POD struct is a non-union class that is both a trivial class and a standard-layout class, and has no non-static data members of type non-POD struct, non-POD union (or array of such types). Similarly, a POD union is a union that is both a trivial class and a standard layout class, and has no non-static data members of type non-POD struct, non-POD union (or array of such types). A POD class is a class that is either a POD struct or a POD union.
trivial classes
Basically this means that a copy or move constructor is trivial if it is not user-provided, the class has nothing virtual in it, and this property holds recursively for all the members of the class and for the base class.
standard layout
The standard mentions that these are useful for communicating with other languages, and that's because a standard-layout class has the same memory layout of the equivalent C struct or union.
const in function
A "const function", denoted with the keyword const after a function declaration, makes it a compiler error for this class function to change a member variable of the class. However, reading of a class variables is okay inside of the function, but writing inside of this function will generate a compiler error.
Another way of thinking about such "const function" is by viewing a class function as a normal function taking an implicit this pointer. So a method int Foo::Bar(int random_arg) (without the const at the end) results in a function like int Foo_Bar(Foo* this, int random_arg), and a call such as Foo f; f.Bar(4) will internally correspond to something like Foo f; Foo_Bar(&f, 4). Now adding the const at the end (int Foo::Bar(int random_arg) const) can then be understood as a declaration with a const this pointer: int Foo_Bar(const Foo* this, int random_arg). Since the type of this in such case is const, no modifications of member variables are possible.
const in pointer
int*- pointer to intint const *- pointer to const intint * const- const pointer to intint const * const- const pointer to const int
const int ci = 0; |
traits
Type traits are a clever technique used in C++ template metaprogramming that gives you the ability to inspect and transform the properties of types.
For example, given a generic type T — it could be int, bool, std::vector or whatever you want — with type traits you can ask the compiler some questions: is it an integer? Is it a function? Is it a pointer? Or maybe a class? Does it have a destructor? Can you copy it? Will it throw exceptions? ... and so on. This is extremely useful in conditional compilation, where you instruct the compiler to pick the right path according to the type in input. We will see an example shortly.
The beauty of these techniques is that everything takes place at compile time with no runtime penalties: it's template metaprogramming, after all.
typedef in stl
private 底下的那些,主要就是因为原类型名完整写出来太长,于是取个短名字。
public 底下那些,除了名字长以外,通常还有很重要一个原因:就是标准规定实现某种类型(典型的如容器,比如本例的 std::map),需要对外提供这些类型。最典型如图中的“iterator”和“const_iterator”,就是因为STL中的(正经)容器,需要对外提供“迭代器”类型和“常量迭代器”类型。 这样,当有一天你需要遍历一个 容器,比如map时,你才可以方便地这样写:
for ( std::map<std::string, int>::const_iterator it = m.cbegin(); it != m.cend(); ++it) |
那个 const_iterator 哪来的?就是在 map<K, V> 里定义的那个 typedef 。 链接:https://www.zhihu.com/question/441345616/answer/1699499726
ADL argument-dependent lookup
Argument-dependent lookup, also known as ADL, or Koenig lookup [1], is the set of rules for looking up the unqualified function names in function-call expressions, including implicit function calls to overloaded operators. These function names are looked up in the namespaces of their arguments in addition to the scopes and namespaces considered by the usual unqualified name lookup.
Argument-dependent lookup makes it possible to use operators defined in a different namespace. Example:
|
dependent name & name binding
inside the definition of a template (both class template and function template), the meaning of some constructs may differ from one instantiation to another. In particular, types and expressions may depend on types of type template parameters and values of non-type template parameters.
template<typename T> |
name binding
为模板显式或隐式使用的每个名字寻找其声明 的过程称为名字绑定
模板中使用的名字分为依赖性名字 dependent name, 非依赖性名字
dependent name 依赖于模板参数的名字, 在实例化点完成绑定 默认情况下, 编译器假定 dependent name 不是类型名, 如果需要, 必须用 typename 显式声明
template<typename Container>
void fct(Container& c){
Container::value_type v1 = c[7];//error
typename Container::value_type v2 = c[9];//coorect
auto v3 = c[11];//correct
}
//或者使用别名
template<typename T>
using Value_type<T> = typename T::value_type;independent name 不依赖于模板参数的名字, 在定义点完成绑定
qualified name
A qualified name is a name that appears on the right hand side of the scope resolution operator :: (see also qualified identifiers).
nested class
A nested class is a class which is declared in another enclosing class. A nested class is a member and as such has the same access rights as any other member.
typename
Where and why do I have to put the "template" and "typename" keywords?
(See here also for my C++11 answer)
In order to parse a C++ program, the compiler needs to know whether certain names are types or not. The following example demonstrates that:
t * f; |
How should this be parsed? For many languages a compiler doesn't need to know the meaning of a name in order to parse and basically know what action a line of code does. In C++, the above however can yield vastly different interpretations depending on what t means. If it's a type, then it will be a declaration of a pointer f. However if it's not a type, it will be a multiplication. So the C++ Standard says at paragraph (3/7):
Some names denote types or templates. In general, whenever a name is encountered it is necessary to determine whether that name denotes one of these entities before continuing to parse the program that contains it. The process that determines this is called name lookup.
How will the compiler find out what a name t::x refers to, if t refers to a template type parameter? x could be a static int data member that could be multiplied or could equally well be a nested class or typedef that could yield to a declaration. If a name has this property - that it can't be looked up until the actual template arguments are known - then it's called a *dependent name* (it "depends" on the template parameters).
You might recommend to just wait till the user instantiates the template:
Let's wait until the user instantiates the template, and then later find out the real meaning of
t::x \* f;.
This will work and actually is allowed by the Standard as a possible implementation approach. These compilers basically copy the template's text into an internal buffer, and only when an instantiation is needed, they parse the template and possibly detect errors in the definition. But instead of bothering the template's users (poor colleagues!) with errors made by a template's author, other implementations choose to check templates early on and give errors in the definition as soon as possible, before an instantiation even takes place.
So there has to be a way to tell the compiler that certain names are types and that certain names aren't.
The "typename" keyword
The answer is: We decide how the compiler should parse this. If t::x is a dependent name, then we need to prefix it by typename to tell the compiler to parse it in a certain way. The Standard says at (14.6/2):
A name used in a template declaration or definition and that is dependent on a template-parameter is assumed not to name a type unless the applicable name lookup finds a type name or the name is qualified by the keyword typename.
There are many names for which typename is not necessary, because the compiler can, with the applicable name lookup in the template definition, figure out how to parse a construct itself - for example with T *f;, when T is a type template parameter. But for t::x * f; to be a declaration, it must be written as typename t::x *f;. If you omit the keyword and the name is taken to be a non-type, but when instantiation finds it denotes a type, the usual error messages are emitted by the compiler. Sometimes, the error consequently is given at definition time:
// t::x is taken as non-type, but as an expression the following misses an operator between the two names or a semicolon separating them. |
The syntax allows typename only before qualified names - it is therefor taken as granted that unqualified names are always known to refer to types if they do so.
A similar gotcha exists for names that denote templates, as hinted at by the introductory text.
The "template" keyword
Remember the initial quote above and how the Standard requires special handling for templates as well? Let's take the following innocent-looking example:
boost::function< int() > f; |
It might look obvious to a human reader. Not so for the compiler. Imagine the following arbitrary definition of boost::function and f:
namespace boost { int function = 0; } |
That's actually a valid expression! It uses the less-than operator to compare boost::function against zero (int()), and then uses the greater-than operator to compare the resulting bool against f. However as you might well know, boost::function in real life is a template, so the compiler knows (14.2/3):
After name lookup (3.4) finds that a name is a template-name, if this name is followed by a <, the < is always taken as the beginning of a template-argument-list and never as a name followed by the less-than operator.
Now we are back to the same problem as with typename. What if we can't know yet whether the name is a template when parsing the code? We will need to insert template immediately before the template name, as specified by 14.2/4. This looks like:
t::template f<int>(); // call a function template |
Template names can not only occur after a :: but also after a -> or . in a class member access. You need to insert the keyword there too:
this->template f<int>(); // call a function template |
Dependencies
For the people that have thick Standardese books on their shelf and that want to know what exactly I was talking about, I'll talk a bit about how this is specified in the Standard.
In template declarations some constructs have different meanings depending on what template arguments you use to instantiate the template: Expressions may have different types or values, variables may have different types or function calls might end up calling different functions. Such constructs are generally said to depend on template parameters.
The Standard defines precisely the rules by whether a construct is dependent or not. It separates them into logically different groups: One catches types, another catches expressions. Expressions may depend by their value and/or their type. So we have, with typical examples appended:
- Dependent types (e.g: a type template parameter
T) - Value-dependent expressions (e.g: a non-type template parameter
N) - Type-dependent expressions (e.g: a cast to a type template parameter
(T)0)
Most of the rules are intuitive and are built up recursively: For example, a type constructed as T[N] is a dependent type if N is a value-dependent expression or T is a dependent type. The details of this can be read in section (14.6.2/1) for dependent types, (14.6.2.2) for type-dependent expressions and (14.6.2.3) for value-dependent expressions.
Dependent names
The Standard is a bit unclear about what exactly is a dependent name. On a simple read (you know, the principle of least surprise), all it defines as a dependent name is the special case for function names below. But since clearly T::x also needs to be looked up in the instantiation context, it also needs to be a dependent name (fortunately, as of mid C++14 the committee has started to look into how to fix this confusing definition).
To avoid this problem, I have resorted to a simple interpretation of the Standard text. Of all the constructs that denote dependent types or expressions, a subset of them represent names. Those names are therefore "dependent names". A name can take different forms - the Standard says:
A name is a use of an identifier (2.11), operator-function-id (13.5), conversion-function-id (12.3.2), or template-id (14.2) that denotes an entity or label (6.6.4, 6.1)
An identifier is just a plain sequence of characters / digits, while the next two are the operator + and operator type form. The last form is template-name <argument list>. All these are names, and by conventional use in the Standard, a name can also include qualifiers that say what namespace or class a name should be looked up in.
A value dependent expression 1 + N is not a name, but N is. The subset of all dependent constructs that are names is called dependent name. Function names, however, may have different meaning in different instantiations of a template, but unfortunately are not caught by this general rule.
Dependent function names
Not primarily a concern of this article, but still worth mentioning: Function names are an exception that are handled separately. An identifier function name is dependent not by itself, but by the type dependent argument expressions used in a call. In the example f((T)0), f is a dependent name. In the Standard, this is specified at (14.6.2/1).
Additional notes and examples
In enough cases we need both of typename and template. Your code should look like the following
template <typename T, typename Tail> |
The keyword template doesn't always have to appear in the last part of a name. It can appear in the middle before a class name that's used as a scope, like in the following example
typename t::template iterator<int>::value_type v; |
In some cases, the keywords are forbidden, as detailed below
On the name of a dependent base class you are not allowed to write
typename. It's assumed that the name given is a class type name. This is true for both names in the base-class list and the constructor initializer list:template <typename T>
struct derive_from_Has_type : /* typename */ SomeBase<T>::type
{ };In using-declarations it's not possible to use
templateafter the last::, and the C++ committee said not to work on a solution.template <typename T>
struct derive_from_Has_type : SomeBase<T> {
using SomeBase<T>::template type; // error
using typename SomeBase<T>::type; // typename *is* allowed
};
size_t
每一个标准C实现应该选择足够大的无符号整形来代表该平台上最大可能出现的对象大小。
适当地使用size_t还会使你的代码变得如同自带文档。当你看到一个对象声明为size_t类型,你马上就知道它代表字节大小或数组索引,而不是错误代码或者是一个普通的算术值。
compiler default
default constructor
If no user-declared constructors of any kind are provided for a class type (struct, class, or union), the compiler will always declare a default constructor as an inline public member of its class.
it has the same effect as a user-defined constructor with empty body and empty initializer list.
destructor
If no user-declared prospective (since C++20)destructor is provided for a class type (struct, class, or union), the compiler will always declare a destructor as an inline public member of its class.
This implicitly-defined destructor has an empty body.
copy constructor
This implicitly-declared copy constructor has the form T::T(const T&) if all of the following are true:
- each direct and virtual base
BofThas a copy constructor whose parameters are const B& or const volatile B&; - each non-static data member
MofTof class type or array of class type has a copy constructor whose parameters are const M& or const volatile M&.
For non-union class types (class and struct), the constructor performs full member-wise copy of the object's bases and non-static members, in their initialization order, using direct initialization.
copy assignment
For non-union class types (class and struct), the operator performs member-wise copy assignment of the object's bases and non-static members, in their initialization order, using built-in assignment for the scalars and copy assignment operator for class types.
move assignment
For non-union class types (class and struct), the move assignment operator performs full member-wise move assignment of the object's direct bases and immediate non-static members, in their declaration order, using built-in assignment for the scalars, memberwise move-assignment for arrays, and move assignment operator for class types (called non-virtually).
UNIX Linux GNU
- UNIX 非开源 AT&T
- BSD 为 UNIX 一个开源版本
- GNU(GNU is not UNIX) 开源软件项目
- Linux Linus 写的内核, 属于类 UNIX, 兼容 POSIX
运算符重载 operator overload
|
注:
<< >> 运算符重载
These operators must be overloaded as a global function. And if we want to allow them to access private data members of the class, we must make them friend.
Why these operators must be overloaded as global? In operator overloading, if an operator is overloaded as a member, then it must be a member of the object on the left side of the operator. For example, consider the statement “ob1 + ob2” (let ob1 and ob2 be objects of two different classes). To make this statement compile, we must overload ‘+’ in a class of ‘ob1’ or make ‘+’ a global function. The operators ‘<<‘ and ‘>>’ are called like ‘cout << ob1’ and ‘cin >> ob1’. So if we want to make them a member method, then they must be made members of ostream and istream classes, which is not a good option most of the time. Therefore, these operators are overloaded as global functions with two parameters, cout and object of user-defined class.
public or private?
(+, +=)Binary operators are typically implemented as non-members to maintain symmetry (for example, when adding a complex number and an integer, if
operator+is a member function of the complex type, then only complex+integer would compile, and not integer+complex).Since for every binary arithmetic operator there exists a corresponding compound assignment operator, canonical forms of binary operators are implemented in terms of their compound assignments:Standard algorithms such as std::sort and containers such as std::set expect operator< to be defined, by default
++ --++
++lvalue ⇒ lvalue+=1 ⇒ lvalue = lvalue+1
y=x++ ⇒ y=(t=x, x=x+1, t)
自引用 this
状态更新函数, 一种很有用的技术是令他们返回已更新对象的返回值
Date& Date::add_year(int n){ |
在类 X 的 nonconst 成员函数中, this 的类型时 X*
在类 X 的 const 成员函数中, this 的类型时 const X*
explicit
explicit的作用是用来声明类构造函数是显示调用的,而非隐式调用,所以只用于修饰单参构造函数。因为无参构造函数和多参构造函数本身就是显示调用的。再加上explicit关键字也没有什么意义。
internal linkage
When you write an implementation file (.cpp, .cxx, etc) your compiler generates a translation unit. This is the source file from your implementation plus all the headers you #include in it.
Internal linkage refers to everything only in scope of a translation unit.
External linkage refers to things that exist beyond a particular translation unit. In other words, accessible through the whole program, which is the combination of all translation units (or object files).
You can explicitly control the linkage of a symbol by using the extern and static keywords. If the linkage is not specified then the default linkage is extern (external linkage) for non-const symbols and static (internal linkage) for const symbols.
Note that instead of using static (internal linkage), it is better to use anonymous namespaces into which you can also put classes. Though they allow extern linkage, anonymous namespaces are unreachable from other translation units, making linkage effectively static.
重载
重载解析与函数声明的次序无关
重载解析过程中不考虑函数的返回类型, 独立于上下文
对象与引用
对象
临时对象
除非我们把临时对象绑定到引用上或者用它初始化一个命名对象, 否则大多数时候在临时对象所在的完整表达式末尾, 他就被销毁了
普通对象
对象(object) --> 一段内存空间
引用
左值引用
有身份的对象的引用
右值引用
可移动的对象的引用
左值右值引用

有身份 i
可移动 m
The original definition of lvalues and rvalues from the earliest days of C is as follows: An lvalue is an expression e that may appear on the left or on the right hand side of an assignment, whereas an rvalue is an expression that can only appear on the right hand side of an assignment.
An lvalue is an expression that refers to a memory location and allows us to take the address of that memory location via the & operator. An rvalue is an expression that is not an lvalue.
X foo(); |
其中x = foo()包括以下步骤
- clones the resource from the temporary returned by
foo, - destructs the resource held by
xand replaces it with the clone, - destructs the temporary and thereby releases its resource.
move action is aimed to swap the resource instead of clone it
you can overload in different ways
void foo(X& x); // lvalue reference overload |
string var {"hello"}; |
除非我们把临时对象绑定到引用上或者用它初始化一个命名对象, 否则大多数时候在临时对象所在的完整表达式末尾, 他就被销毁了
临时量可以用作 const 引用或者命名对象的初始化器(见why rvalue is allowed to passed by const reference)
void fs(string& s1, string& s2){ |
why rvalue is allowed to passed by const reference
C++ deliberately specifies that binding a temporary object to a reference to const on the stack lengthens the lifetime of the temporary to the lifetime of the reference itself
// Example 1 legal |
only lvalues can be bound to references to non-const.
初始化
使用=进行初始化可能会发生窄化转换, 使用初始化列表不会, 所以推荐使用初始化列表, 但是 auto 不推荐, 因为会得到 list 类型.
X a1 {v}; |
缺少初始化容器
- 全局变量, 局部 static 变量, static 成员会执行{} 初始化
- 局部变量, 堆对象, 除非位于默认构造函数中, 否则不会进行默认初始化
raw string
C++11 引入了原始字符串。最基本的用法是R"(...)",由R开头,双引号内包围着(...),实际的字符序列是小括号内的内容,小括号是字符序列的定界符。当然,左小括号和右小括号是首位对应的。
“原始”(raw)体现在字符串里的字符一就是一,二就是二,不会给你转义。也就是说,传统的"\\n"除了字符串结尾符,仅包含换行符,而原始字符串R"(\\n)"则包含反斜杠和字符n,这是明显的不同。
从现在来看,貌似已经很好的解决问题了,但如果字符序列里包含)",如R"(坐标: "(x,y)")",此时编译器是懵的,因为"(对应了两个)"。在这种情况下,我们可以选择其他定界符,如,R"&(坐标: "(x,y)")&"。语法如下:R"delim(...)delim",delim的选取比较灵活,最长不超过16个字符,且不为小括号、空白、控制字符和反斜杠。

变量与类型
- 类型 type: 定义一组可能的值以及一组操作
- 对象 object: 存放某类型的内存空间
- 值 value: 一组二进制位, 含义由其类型决定
- 变量 variable: 是一个命名的对象
函数对象(函子)
template<typename T> |
模板 template
模板类声明
template<typename T> |
模板函数声明
template <typename T> |
enum
使用 enum class 定义枚举类型时不能与 int 类型互相转换, 运算只有> < ==, 而且 enum class 的枚举值名字位于 enum 局部作用域内
enum class Traffic_light {red, yellow, green}; |
literal type
Literal types are the types of constexpr variables and they can be constructed, manipulated, and returned from constexpr functions.
struct A { constexpr A(int) = delete; char c; }; // A is a literal type |
constexpr
编译时求值
|
const int array_size1 (int x) { |
c-v qualified class
const and volatile class
// non cv_qualified |
For any type T (including incomplete types), other than function type or reference type, there are three more distinct types in the C++ type system: const-qualified T, volatile-qualified T, and const-volatile-qualified T.
- const object - an object whose type is const-qualified, or a non-mutable subobject of a const object. Such object cannot be modified: attempt to do so directly is a compile-time error, and attempt to do so indirectly (e.g., by modifying the const object through a reference or pointer to non-const type) results in undefined behavior.
- volatile object - an object whose type is volatile-qualified, or a subobject of a volatile object, or a mutable subobject of a const-volatile object. Every access (read or write operation, member function call, etc.) made through a glvalue(A glvalue expression is either lvalue or xvalue.) expression of volatile-qualified type is treated as a visible side-effect for the purposes of optimization (that is, within a single thread of execution, volatile accesses cannot be optimized out or reordered with another visible side effect that is sequenced-before or sequenced-after the volatile access. This makes volatile objects suitable for communication with a signal handler, but not with another thread of execution, see std::memory_order). Any attempt to refer to a volatile object through a glvalue of non-volatile type (e.g. through a reference or pointer to non-volatile type) results in undefined behavior.
- const volatile object - an object whose type is const-volatile-qualified, a non-mutable subobject of a const volatile object, a const subobject of a volatile object, or a non-mutable volatile subobject of a const object. Behaves as both a const object and as a volatile object.
accumulation
#include <numeric>
c++11 vscode
"clang.cxxflags": ["-std=c++14"]
setting.json
C++ Clang Command Adapter 删除!!!! 原因应该是这个插件不继承c_cpp_properties.json中设置的C++版本
mid
mid = (l+r)/2;
mid = l+(r-l)/2;
防溢出
std::vector<bool>
vector
首先vector< bool> 并不是一个通常意义上的vector容器,这个源自于历史遗留问题。 早在C++98的时候,就有vector< bool>这个类型了,但是因为当时为了考虑到节省空间的想法,所以vector< bool>里面不是一个Byte一个Byte储存的,它是一个bit一个bit储存的!
因为C++没有直接去给一个bit来操作,所以用operator[]的时候,正常容器返回的应该是一个对应元素的引用,但是对于vector< bool>实际上访问的是一个"proxy reference"而不是一个"true reference",返回的是"std::vector< bool>:reference"类型的对象。 而一般情况情况下
vector<bool> c{ false, true, false, true, false }; |
对于b的初始化它其实暗含了一个隐式的类型转换。
此时 auto 代表的是一个右值引用
而对于d,它的类型并不是bool,而是一个vector< bool>中的一个内部类。
而此时如果修改d的值,c中的值也会跟着修改
d = true; |
而如果c被销毁,d就会变成一个悬垂指针,再对d操作就属于未定义行为。
而为什么说vector< bool>不是一个标准容器,就是因为它不能支持一些容器该有的基本操作,诸如取地址给指针初始化操作
vector<bool> c{ false, true, false, true, false }; |
The std::vector<bool> specialization defines std::vector<bool>::reference as a publicly-accessible nested class. std::vector<bool>::reference proxies the behavior of references to a single bit in std::vector<bool>.
The primary use of std::vector<bool>::reference is to provide an l-value that can be returned from operator[].
Any reads or writes to a vector that happen via a std::vector<bool>::reference potentially read or write to the entire underlying vector.
for 循环
for(auto i : array){ |
varient type in for range loop
std::vector<bool> v{false, false, false}; |
After the loop ends, v will contain true, true, true, which is clearly something you would not expect. See this blog post for more details. Here, instead of using auto, it is better to explicitly specify the type (bool). With bool, it will work as expected: the contents of the vector will be left unchanged.
Using just auto will not work when iterating over ranges containing move-only types, such as std::unique_ptr. As auto creates a copy of each element in the range, the compilation will fail because move-only types cannot be copied.
const auto (dont use)
for(const auto x : range) |
The use of const auto may suggest that you want to work with an immutable copy of each element. However, when would you want this? Why not use const auto&? Why creating a copy when you will not be able to change it? And, even if you wanted this, from a code-review standpoint, it looks like you forgot to put & after auto. Therefore, I see no reason for using const auto. Use const auto& instead.
auto&
for(auto& x : range) |
Use auto& when you want to modify elements in the range in non-generic code. The first part of the previous sentence should be clear as auto& will create references to the original elements in the range. To see why this code should not be used in generic code (e.g. inside templates), take a look at the following function template:
// Sets all elements in the given range to the given value. |
It will work. Well, most of the time. Until someone tries to use it on the dreaded std::vector<bool>. Then, the example will fail to compile because dereferencing an iterator of std::vector<bool> yields a temporary proxy object, which cannot bind to an lvalue reference (auto&). As we will see shortly, the solution is to use “one more &” when writing generic code.
(error: non-const lvalue reference to type '__bit_reference<...>' cannot bind to a temporary of type '__bit_reference<...>')
const auto& (read only)
for(const auto& x : range) |
Use const auto& when you want read-only access to elements in the range, even in generic code. This is the number one choice for iterating over a range when all you want to is read its elements. No copies are made and the compiler can verify that you indeed do not modify the elements.
Nevertheless, keep in mind that even though you will not be able to modify the elements in the range directly, you may still be able to modify them indirectly. For example, when the elements in the range are smart pointers:
struct Person { |
In such situations, you have to pay close attention to what you are doing because the compiler will not help you, even if you write const auto&.
auto&&
The essence of the issue is that “
&&” in a type declaration sometimes means rvalue reference, but sometimes it means either rvalue reference or lvalue reference. As such, some occurrences of “&&” in source code may actually have the meaning of “&”, i.e., have the syntactic appearance of an rvalue reference (“&&”), but the meaning of an lvalue reference (“&”). References where this is possible are more flexible than either lvalue references or rvalue references. Rvalue references may bind only to rvalues, for example, and lvalue references, in addition to being able to bind to lvalues, may bind to rvalues only under restricted circumstances.[1] In contrast, references declared with “&&” that may be either lvalue references or rvalue references may bind to anything. Such unusually flexible references deserve their own name. I call them universal references.If a variable or parameter is declared to have type
T&&for some deduced(推断) typeT, that variable or parameter is a universal reference.In practice, almost all universal references are parameters to function templates.Because the type deduction rules for
auto-declared variables are essentially the same as for templates, it’s also possible to haveauto-declared universal references.i.e. auto&&
i.e. template<typename T> void f(T&& param)
for (auto&& x : range) |
Use auto&& when you want to modify elements in the range in generic code. To elaborate, auto&& is a forwarding reference, also known as a universal reference. It behaves as follows:
- When initialized with an lvalue, it creates an lvalue reference.
- When initialized with an rvalue, it creates an rvalue reference.
A detailed explanation of forwarding references is outside of scope of the present post. For more details, see this article by Scott Meyers. Anyway, the use of auto&& allows us to write generic loops that can also modify elements of ranges yielding proxy objects, such as our friend (or foe?) std::vector<bool>:
// Sets all elements in the given range to the given value.// Now working even with std::vector<bool>. |
Now, you may wonder: if auto&& works even in generic code, why should I ever use auto&? As Howard Hinnant puts it, liberate use of auto&& results in so-called confuscated code: code that unnecessarily confuses people. My advice is to use auto& in non-generic code and auto&& only in generic code(generic programming 泛型编程).
By the way, there was a proposal for C++1z to allow writing just for (x : range), which would be translated into for (auto&& x : range). Such range-based for loops were called terse. However, this proposal was removed from consideration and will not be part of C++.
const auto&&(dont use)
for(const auto&& x : range) |
This variant will bind only to rvalues, which you will not be able to modify or move because of the const. This makes it less than useless. Hence, there is no reason for choosing this variant over const auto&.
decltype(auto)
for(decltype(auto) x : range) // C++14 |
C++14 introduced decltype(auto). It means: apply automatic type deduction, but use decltype rules. Whereas auto strips down top-level cv qualifiers and references, decltype preserves them.
see more for auto and decltype
As is stated in this C++ FAQ, decltype(auto) is primarily useful for deducing the return type of forwarding functions and similar wrappers. However, it is not intended to be a widely used feature beyond that. And indeed, there seems to be no reason for using it in range-based for loops.
Summary
To summarize:
- Use
autowhen you want to work with a copy of elements in the range.(except for bool, use bool instead of auto) - Use
auto&when you want to modify elements in the range in non-generic code. - Use
auto&&when you want to modify elements in the range in generic code. - Use
const auto&when you want read-only access to elements in the range (even in generic code).
Other variants are generally less useful.
decltype
|
reverse iterator
std::reverse_iterator produces a new iterator that moves from the end to the beginning of the sequence defined by the underlying bidirectional iterator.

.c&.h文件 .h文件里不要定义变量,可以声明!!
一个经典错误。3a222 在a.h头文件中定义变量temp并初始化,即显式初始化。int temp = 0;
a.c b.c文件中都包含了a.h头文件,则在编译时会出现:multiple definition of `a’的错误。
a.h中定义变量temp,不初始化为0即为不显示初始化。
不显示初始化不出错原因: —— 不显式的初始化,在C语言中(C++中不是这样的),则先假定为声明,多次声明是没错的,最后才是定义。
内置变量
bool: 所占字节数:1 最大值:1 最小值:0 |
Extern
用extern来声明在别的文件中已经存在的变量和函数,而且格式必须严格一致(比如数组不等价于指针)
extern int x; |
其实相当于只声明, 不定义.
- static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
传参
| 调用类型 | 描述 |
|---|---|
| 传值调用 | 该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数对实际参数没有影响。 |
| 指针调用 | 该方法把参数的地址复制给形式参数。在函数内,该地址用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
| 引用调用 | 该方法把参数的引用复制给形式参数。在函数内,该引用用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
- 参数可以有默认值
lambda表达式
[capture](parameters)->return_type{body} |
每当你定义一个lambda表达式后,编译器会自动生成一个匿名类(这个类当然重载了()运算符),我们称为闭包类型(closure type)。那么在运行时,这个lambda表达式就会返回一个匿名的闭包实例,其实一个右值。所以,我们上面的lambda表达式的结果就是一个个闭包。闭包的一个强大之处是其可以通过传值或者引用的方式捕捉其封装作用域内的变量,前面的方括号就是用来定义捕捉模式以及变量,我们又将其称为lambda捕捉块。
捕获列表[]: [&]通过引用捕获, [=]通过值捕获, [this]成员通过引用捕获
int main() |
虚函数 虚基类
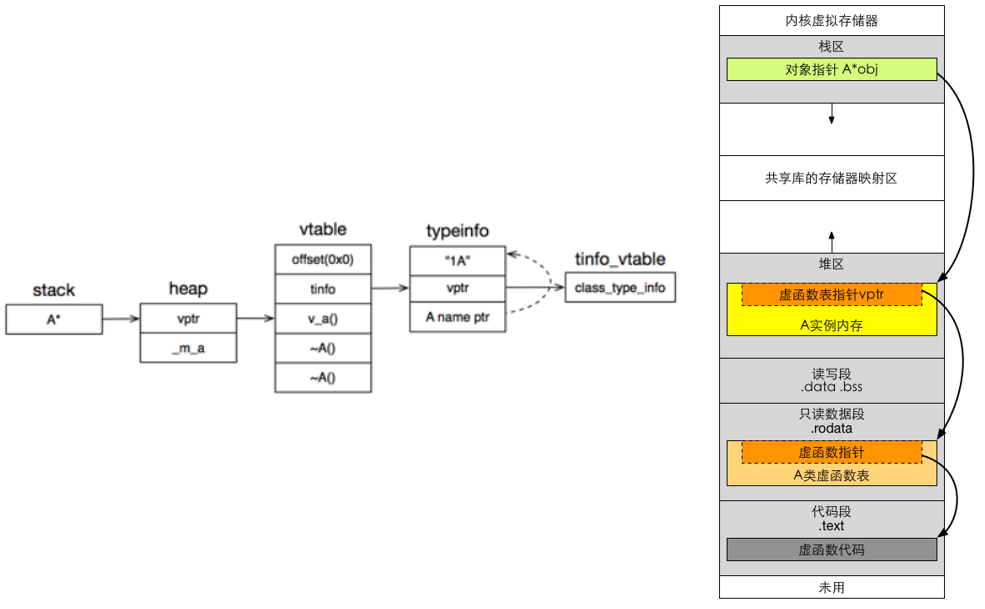
虚函数
➢ 编译程序为有虚函数的类创建一个虚函数入口地址表VFT,
➢ 表首地址存放在对象的起始单元中。
➢ 当对象调用虚函数时,通过其起始单元得到VFT首址,
动态绑定到相应的函数成员。

vtbl (virtual function table) 指明了每个类在运行时应该调用 which 虚函数
每个类有一个自己的vtbl
开销: 每个对象需要一个额外的指针即指向 vtbl 的指针, 每个类需要一个 vtbl
https://stackoverflow.com/questions/3324721/virtual-tables-and-virtual-pointers-for-multiple-virtual-inheritance-and-type-ca
question:
I am little confused about vptr and representation of objects in the memory, and hope you can help me understand the matter better.
- Consider
Binherits fromAand both define virtual functionsf(). From what I learned the representation of an object of class B in the memory looks like this:[ vptr | A | B ]and thevtblthatvptrpoints to containsB::f(). I also understood that casting the object fromBtoAdoes nothing except ignoring theBpart at the end of the object. Is it true? Doesn't this behavior is wrong? We want that object of typeAto executeA::f()method and notB::f(). - Are there a number of
vtablesin the system as the number of classes? - How will a
vtableof class that inherits from two or more classes look like? How will the object of C be represented in the memory? - Same as question 3 but with virtual inheritance.
answer:
The following is true for GCC (and it seems true for LLVM link), but may also be true for the compiler you're using. All these is implementation-dependent, and is not governed by C++ standard. However, GCC write its own binary standard document, Itanium ABI.
I tried to explain basic concepts of how virtual tables are laid out in more simple words as a part of my article about virtual function performance in C++, which you may find useful. Here are answers to your questions:
A more correct way to depict internal representation of the object is:
| vptr | ======= | ======= | <-- your object
|----A----| |
|---------B---------|Bcontains its base classA, it just adds a couple of his own members after its end.Casting from
B*toA*indeed does nothing, it returns the same pointer, andvptrremains the same. But, in a nutshell, virtual functions are not always called via vtable. Sometimes they're called just like the other functions.Here's more detailed explanation. You should distinguish two ways of calling member function:
A a, *aptr;
a.func(); // the call to A::func() is precompiled!
aptr->A::func(); // ditto
aptr->func(); // calls virtual function through vtable.
// It may be a call to A::func() or B::func().The thing is that it's known at compile time how the function will be called: via vtable or just will be a usual call. And the thing is that the type of a casting expression is known at compile time, and therefore the compiler chooses the right function at compile time.
B b, *bptr;
static_cast<A>(b)::func(); //calls A::func, because the type
// of static_cast<A>(b) is A!It doesn't even look inside vtable in this case!
Generally, no. A class can have several vtables if it inherits from several bases, each having its own vtable. Such set of virtual tables forms a "virtual table group" (see pt. 3).
Class also needs a set of construction vtables, to correctly distpatch virtual functions when constructing bases of a complex object. You can read further in the standard I linked.
Here's an example. Assume
Cinherits fromAandB, each class definingvirtual void func(), as well asa,borcvirtual function relevant to its name.The
Cwill have a vtable group of two vtables. It will share one vtable withA(the vtable where the own functions of the current class go is called "primary"), and a vtable forBwill be appended:| C::func() | a() | c() || C::func() | b() |
|---- vtable for A ----| |---- vtable for B ----|
|--- "primary virtual table" --||- "secondary vtable" -|
|-------------- virtual table group for C -------------|The representation of object in memory will look nearly the same way its vtable looks like. Just add a
vptrbefore every vtable in a group, and you'll have a rough estimate how the data are laid out inside the object. You may read about it in the relevant section of the GCC binary standard.Virtual bases (some of them) are laid out at the end of vtable group. This is done because each class should have only one virtual base, and if they were mingled with "usual" vtables, then compiler couldn't re-use parts of constructed vtables to making those of derived classes. This would lead to computing unnecessary offsets and would decrease performance.
Due to such a placement, virtual bases also introduce into their vtables additional elements:
vcalloffset (to get address of a final overrider when jumping from the pointer to a virtual base inside a complete object to the beginning of the class that overrides the virtual function) for each virtual function defined there. Also each virtual base addsvbaseoffsets, which are inserted into vtable of the derived class; they allow to find where the data of the virtual base begin (it can't be precompiled since the actual address depends on the hierarchy: virtual bases are at the end of object, and the shift from beginning varies depending on how many non-virtual classes the current class inherits.).
Woof, I hope I didn't introduce much unnecessary complexity. In any case, you may refer to the original standard, or to any document of your own compiler.
虚基类
Virtual inheritance is there to solve this problem(菱形继承). When you specify virtual when inheriting your classes, you're telling the compiler that you only want a single instance.
class A { public: void Foo() {} }; |
声明 定义
区分声明与定义
1、一种是需要建立存储空间的。例如:int a 在声明的时候就已经建立了存储空间。
2、另一种是不需要建立存储空间的。 例如:extern int a 其中变量a是在别的文件中定义的
声明是向编译器介绍名字--标识符。它告诉编译器“这个函数或变量在某处可找到。
而定义是说:“在这里建立变量”或“在这里建立函数”。它为名字分配存储空间。无论定义的是函数还是变量,编译器都要为它们在定义点分配存储空间。对于变量,编译器确定变量的大小,然后在内存中开辟空间来保存其数据,对于函数,编译器会生成代码,这些代码最终也要占用一定的内存。
基本类型变量的声明和定义是同时产生的, 对于对象来说则是分开的
A a; //对象声明 |
所谓定义就是(编译器)创建一个对象,为这个对象分配一块内存,并给它取上一个名字,这个名字就是就是我们经常所说的变量名或对象名。
声明有2重含义:
(1) 告诉编译器,这个名字已经匹配到一块内存上,下面的代码用到变量或者对象是在别的地方定义的。声明可以出现多次。
(2) 告诉编译器,这个名字已经被预定了,别的地方再也不能用它来作为变量名或对象名。
*定义和声明的最重要区别就是:*
*定义创建对象并为这个对象分配了内存,声明没有分配内存。*
函数原型: 在计算机编程中,函数原型(英语:Function prototype)或函数接口(英语:Function interface)是用于指定函数的名称和类型特征(元数,参数的数据类型和返回值类型)的一种省略了函数体的函数声明。
strcut和class的区别
- 默认的继承访问权。class默认的是private,strcut默认的是public(union 也是 public)。
- 默认访问权限:struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的。
- “class”这个关键字还用于定义模板参数,就像“typename”。但关建字“struct”不用于定义模板参数
- class和struct在使用大括号{ }上的区别 关于使用大括号初始化 1.)class和struct如果定义了构造函数的话,都不能用大括号进行初始化 2.)如果没有定义构造函数,struct可以用大括号初始化。 3.)如果没有定义构造函数,且所有成员变量全是public的话,class可以用大括号初始化
namespace
类的头文件应该是自己形成一个命名空间, 然后 cpp 文件因为是相当于在类外进行定义所以要使用命名空间指明函数定义
explicit implicit
上面的代码中, "CxString string2 = 10;" 这句为什么是可以的呢? 在C++中, 如果的构造函数只有一个参数时, 那么在编译的时候就会有一个缺省的转换操作:将该构造函数对应数据类型的数据转换为该类对象. 也就是说 "CxString string2 = 10;" 这段代码, 编译器自动将整型转换为CxString类对象, 实际上等同于下面的操作:
CxString string2(10);
即隐式转换
当使用 explicit 关键字修饰构造函数以后, 就能避免这种操作
默认情况下构造函数都是 implicit 的
friend 友元
原则上, 类的私有(private)和受保护(protected)成员不能从声明它们的同一类外部访问。但是, 此规则不适用于友元 "friends"。
以friend关键字修饰的函数或类称为友元函数或友元类。
友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字friend,其格式如下:
friend 类型 函数名(形式参数);
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。定义友元类的语句格式如下:
friend class 类名;
其中:friend和class是关键字,类名必须是程序中的一个已定义过的类。
使用友元类时注意:
1、友元关系不能被继承。
2、友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
3、友元关系具有非传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明。
public protect private 继承
类继承方式 -> 基类成员的访问权限
继承无法访问父变量的 private 成员
访问权限
private:私有成员
仅可被本类的函数成员访问
不能被派生类、其它类和普通函数访问
protected:受保护成员
可被本类和派生类的函数成员访问
不能被其它类函数成员和普通函数访问
public:公有成员
可被任何函数成员和普通函数访问
继承权限 public继承 派生类通过public继承,基类的各种权限不变 。 派生类的成员函数,可以访问基类的public成员、protected成员,但是无法访问基类的private成员。 派生类的实例变量,可以访问基类的public成员,但是无法访问protected、private成员,仿佛基类的成员之间加到了派生类一般。 可以将public继承看成派生类将基类的public,protected成员囊括到派生类,但是不包括private成员。
protected继承 派生类通过protected继承,基类的public成员在派生类中的权限变成了protected 。protected和private不变。 派生类的成员函数,可以访问基类的public成员、protected成员,但是无法访问基类的private成员。 派生类的实例变量,无法访问基类的任何成员,因为基类的public成员在派生类中变成了protected。 可以将protected继承看成派生类将基类的public,protected成员囊括到派生类,全部作为派生类的protected成员,但是不包括private成员。 private成员是基类内部的隐私,除了友元,所有人员都不得窥探。派生类的友元,都不能访问
private继承 派生类通过private继承,基类的所有成员在派生类中的权限变成了private。 派生类的成员函数,可以访问基类的public成员、protected成员,但是无法访问基类的private成员。 派生类的实例变量,无法访问基类的任何成员,因为基类的所有成员在派生类中变成了private。 可以将private继承看成派生类将基类的public,protected成员囊括到派生类,全部作为派生类的private成员,但是不包括private成员。 private成员是基类内部的隐私,除了友元,所有人员都不得窥探。派生类的友元,都不能访问
总结:继承修饰符,就像是一种筛子,将基类的成员筛到派生类。public、protected、private,就是筛子的眼。 通过public继承,所有基类成员(除了private),public、protected都到了派生类里面,public筛眼比较大,不会改变访问权限。 通过protected继承,所有基类成员(除了private),public、protected都到了派生类里面,protected筛眼大小适中,所有过来的成员都变成了protected。 通过private继承,所有基类成员(除了private),public、protected都到了派生类里面,private筛眼最小,所有过来的成员都变成了private。
隐式转换和显式转换
隐式转换: 比如 double = int, 或者调用构造函数的那种(见explicit implicit)
显式转换: 又称强制类型转换. 比如 int(), static_cast
保护值不被改变的隐式类型转换称为"提升", 如整型提升
浮点到整数发生截断, -1.6 → -1
返回引用
当返回的值不是引用型时,编译器会专门给返回值分配出一块内存的
T function1(){ |
这里的过程是: 1.创建命名对象t 2.拷贝构造一个无名的临时对象,并返回这个临时对象 3.由临时对象拷贝构造对象x 4.T x=function1();这句语句结束时,析构临时对象 这里一共生成了3个对象,一个命名对象t,一个临时对象作为返回值,一个命名对象x。
返回引用, 其实就是返回了一个对象的引用, 新对象 = 返回的引用, 调用了拷贝构造函数
静态数据成员
静态成员变量必须?要在类外部定义(c++11 整型可在内), 因为要在对象创建之前就分配内存
They can't be initialised inside the class, but they can be initialised outside the class, in a source file:
// inside the class |
Essentially it's because x exists independently of the number of instances of A that are created.
So storage for x needs to be defined somewhere - you can't rely on an instance of A to do that, and that's what
in exactly one translation unit, does.
When the const qualifier is present, the static variable can be considered as a constant expression. Initializing it in the class definition goes to that effect. It's just some constant value, may not even need any storage.
But in the other case, it's not a constant expression. It definitely needs storage. And as @Bathsheba points out, it needs to be defined in only one translation unit (pre-C++17). Generally speaking, a declaration that contains an initializer is also a definition. So it just can't be initialized when declared.
缺省参数 (默认参数)
带缺省值的参数必须放在参数列表的最后面。因为传参是从右向左的(arguments are pushed onto the stack from right to left)。
即默认参数往右必须全是默认参数
缺省参数不能同时在函数声明和定义中出现,只能二者留其一。
构造函数
在构造函数体前初始化:只读成员、引用成员、对象成员, 包括在声明时初始化和在列表中初始化
作用域
从小到大可以分为五级:
① 作用于表达式内 (常量)
② 作用于函数成员内 (函数参数、局部变量、局部类型)
③ 作用于类或派生类内 (数据/函数/类型 成员)
④ 作用于基类内 (数据/函数/类型 成员)
⑤ 作用于虚基类内 (数据/函数/类型 成员)
虚基类 > 基类 > 类/派生类 > 成员函数 > 表达式内
成员指针
Class Student { |
对于普通指针变量来说,其值是它所指向的地址,0表示空指针。 而对于数据成员指针变量来说,其值是数据成员所在地址相对于对象起始地址的偏移值,空指针用-1表示
struct X { |
堆与栈
https://zhuanlan.zhihu.com/p/344377490
int main() { |
预备知识—程序的内存分配
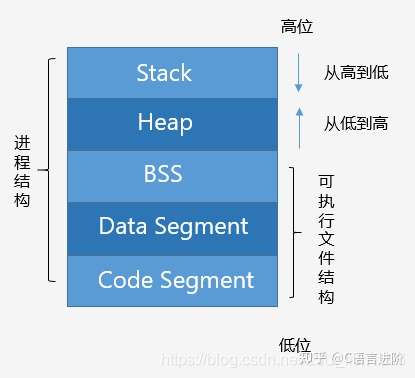
一个由C/C++编译的程序占用的内存分为以下几个部分
关于 bss 和数据段的区别https://zhuanlan.zhihu.com/p/28659560
data段 :用于存放在编译阶段(而非运行时)就能确定的数据,可读可写。也是通常所说的静态存储区,赋了初值的全局变量、常量和静态变量都存放在这个域。
而bss段不在可执行文件中,由系统初始化。
int ar[30000]; |
发现程序2编译之后所得的可执行文件比程序1大得多。
区别很明显,程序1位于bss段,程序2位于data段,两者的区别在于:
全局的未初始化变量存在于bss段中,具体体现为一个占位符,全局的已初始化变量存于data段中,而函数内的自动变量都在栈上分配空间。
bss不占用可执行文件空间,其内容由操作系统初始化(清零),裸机程序需要自行手动清零。
而data段则需要占用可执行文件空间,其内容由程序初始化,因此造成了上述情况。
注意:
bss段(未手动初始化的数据)并不给该段的数据分配空间,只是记录数据所需空间的大小。
data段(已手动初始化的数据)为数据分配空间,数据保存在目标文件中。
data段包含经过初始化的全局变量以及它们的值。
BSS段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段后面。当这个内存区进入程序的地址空间后全部清零,包含data和bss段的整个区段此时通常称为数据区。
Code Segment(代码区)
也称Text Segment,存放可执行程序的机器码。
Data Segment (数据区)
存放已初始化的全局和静态变量, 常量数据(如字符串常量)。
BSS(Block started by symbol) better save space
存放未初始化的全局和静态变量。(默认设为0)
Heap(堆)
从低地址向高地址增长。容量大于栈,程序中动态分配的内存在此区域。
Stack(栈)
从高地址向低地址增长。由编译器自动管理分配。程序中的局部变量、函数参数值、返回变量等存在此区域。
//main.cpp |
堆和栈的理论知识
申请方式
- stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
- heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = new char[10];
但是注意p1、p2本身是在栈中的。
申请后系统的响应
- 栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- 堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序 ,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。 另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部 分重新放入空闲链表中。
申请大小的限制
- 栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
- 堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
申请效率的比较:
- 栈由系统自动分配,速度较快。但程序员是无法控制的。
- 堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS 下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈, 是直接在进程的地址空间中保留一块内存,虽然用起来最不方便。但是速度快,也最灵活。
堆和栈中的存储内容
- 栈:在函数调用时,第一个进栈的是主函数中的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
- 堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容由程序员安排。
存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。 比如:
void main() |
对应的汇编代码
10: a = c[1]; |
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,再根据edx读取字符,显然慢了。
各自优点
堆(heap)
堆是一个内存空间,这个内存控件可以由程序员分配和释放,当然部分语言自带 GC( Garbage Collection 垃圾回收),部分堆内存可以由 GC 回收。
堆是程序在运行的时候请求操作系统分配给自己内存。由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率相对栈来说略低。但是堆的优点在于,编译器不必知道要从堆里分配多少内存空间,也不必知道存储的数据要在堆里停留多长的时间,因此用堆保存数据时会得到更大的灵活性。因此,为达到这种灵活性,在堆里分配存储空间时会花掉相对更长的时间,这也是效率低于栈的原因。
栈(stack)
栈是由编译器自动分配和释放的,存放函数的参数值,局部变量的值等。也请注意,这里说的栈 不是数据结构中的栈,大家千万不要混淆。这里请注意,栈是由由系统自动分配。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
类型转换
const_cast , static_cast , dynamic_cast , reinterpret_cast
C风格的强制转换
C风格的强制转换(Type Cast)容易理解,不管什么类型的转换都可以使用使用下面的方式.
TypeName b = (TypeName)a;1 |
当然,C++也是支持C风格的强制转换,但是C风格的强制转换可能带来一些隐患,让一些问题难以察觉.所以C++提供了一组可以用在不同场合的强制转换的函数.
C++ 四种强制转换类型函数
const_cast
1、常量指针被转化成非常量的指针,并且仍然指向原来的对象; 2、常量引用被转换成非常量的引用,并且仍然指向原来的对象; 3、const_cast一般用于修改指针。如const char *p形式。
|
注意:对于在定义为常量的参数,使用const_cast可能会有不同的效果.类似代码如下
|
未定义行为:C++标准对此类行为没有做出明确规定.同一份代码在使用不同的编译器会有不同的效果.在 vs2017 下, 虽然代码中 c_val , use_val , ptr_val 看到的地址是一样的.但是c_val的值并没有改变.有可能在某种编译器实现后,这一份代码的c_val 会被改变.也有可能编译器对这类行为直接 error 或 warning.
static_cast
- static_cast 作用和C语言风格强制转换的效果基本一样,由于没有运行时类型检查来保证转换的安全性,所以这类型的强制转换和C语言风格的强制转换都有安全隐患。
- 用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换。注意:进行上行转换(把派生类的指针或引用转换成基类表示)是安全的;进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的。
- 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性需要开发者来维护。
- static_cast不能转换掉原有类型的const、volatile、或者 __unaligned属性。(前两种可以使用const_cast 来去除)
- 在c++ primer 中说道:c++ 的任何的隐式转换都是使用 static_cast 来实现。
/* 常规的使用方法 */ |
dynamic_cast
dynamic_cast强制转换,应该是这四种中最特殊的一个,因为他涉及到面向对象的多态性和程序运行时的状态,也与编译器的属性设置有关.所以不能完全使用C语言的强制转换替代,它也是最常有用的,最不可缺少的一种强制转换.
|
从上边的代码和输出结果可以看出: 对于从子类到基类的指针转换 ,dynamic_cast 成功转换,没有什么运行异常,且达到预期结果 而从基类到子类的转换 , dynamic_cast 在转换时也没有报错,但是输出给 base2sub 是一个 nullptr ,说明dynami_cast 在程序运行时对类型转换对“运行期类型信息”(Runtime type information,RTTI)进行了检查. 这个检查主要来自虚函数(virtual function) 在C++的面对对象思想中,虚函数起到了很关键的作用,当一个类中拥有至少一个虚函数,那么编译器就会构建出一个虚函数表(virtual method table)来指示这些函数的地址,假如继承该类的子类定义并实现了一个同名并具有同样函数签名(function siguature)的方法重写了基类中的方法,那么虚函数表会将该函数指向新的地址。此时多态性就体现出来了:当我们将基类的指针或引用指向子类的对象的时候,调用方法时,就会顺着虚函数表找到对应子类的方法而非基类的方法。因此注意下代码中 Base 和 Sub 都有声明定义的一个虚函数 ” i_am_virtual_foo” ,我这份代码的 Base 和 Sub 使用 dynami_cast 转换时检查的运行期类型信息,可以说就是这个虚函数
reinterpret_cast
reinterpret_cast 运算符并不会改变括号中运算对象的值,而是对该对象从位模式上进行重新解释”
reinterpret_cast是强制类型转换符用来处理无关类型转换的,通常为操作数的位模式提供较低层次的重新解释!但是他仅仅是重新解释了给出的对象的比特模型,并没有进行二进制的转换! 他是用在任意的指针之间的转换,引用之间的转换,指针和足够大的int型之间的转换,整数到指针的转换,在下面的文章中将给出. 请看一个简单代码
|
上述代码将指针ptr的地址的值转换成了 unsigned int 类型的ptr_addr 的整数值. 提供下IBM C++ 对 reinterpret_cast 推荐使用的地方 A pointer to any integral type large enough to hold it (指针转向足够大的整数类型) A value of integral or enumeration type to a pointer (从整形或者enum枚举类型转换为指针) A pointer to a function to a pointer to a function of a different type (从指向函数的指针转向另一个不同类型的指向函数的指针) A pointer to an object to a pointer to an object of a different type (从一个指向对象的指针转向另一个不同类型的指向对象的指针) A pointer to a member to a pointer to a member of a different class or type, if the types of the members are both function types or object types (从一个指向成员的指针转向另一个指向类成员的指针!或者是类型,如果类型的成员和函数都是函数类型或者对象类型)
下面这个例子来自 MSDN 的一个哈希函数辅助
// expre_reinterpret_cast_Operator.cpp |
结尾
在使用强制转换的时候,请先考虑清楚我们真的需要使用强制转换和我们应该使用那种强制转换. 我这只是简单的介绍这四种强制转换的用途,以上是自己的理解,文章中肯定有各种问题错误,希望大家帮忙指出矫正,本文仅供参考. 谢谢阅读.
Effective c++
绪论
声明式: 告诉编译器某个东西的名称和类型
签名式(signature): 每个函数的声明揭示其签名式, 也就是参数和返回类型
定义式: 提供给编译器 一些声明式的细节, 对对象而言, 定义式是编译器为此对象拨发内存的地址; 对函数或者函数模板而言, 定义式提供了代码本体; 对于 class 而言定义式列出他们的成员
copy 构造函数定义了一个对象如何 passed by value
接口: 函数的签名或 class 内可访问的元素
const 成员函数
不会对这个类的对象的数据成员作出任何改变, 即在 const 成员函数中无法赋值
| 对象可否调用函数 | const 对象 | noconst 对象 |
|---|---|---|
| const 成员函数 | yes | yes |
| noconst 成员函数 | no | yes |
const 成员函数也不要提供修改途径(比如返回引用), 虽然可以通过编译
可以通过 mutable 在 const 函数中改变对象的数据
构造函数
在构造函数中赋值相当于先初始化再赋值, 有开销 所以要用初始化列表赋值, 对象成员的初始化是在进入构造函数本体之前
调用构造函数初始化成员
避免编译器自动生成的 copy 构造函数和 copy 运算符, 声明为 private
析构函数
析构函数的运作方式是, 最深层派生(most derived)的那个 class 其虚构函数最先被调用, 然后是调用其每一个 base class 的析构函数
How does the compiler then call the base destructors?
The process of destructing an object takes more operations than those you write inside the body of the destructor. When the compiler generates the code for the destructor, it adds extra code both before and after the user defined code.
Before the first line of a user defined destructor is called, the compiler injects code that will make the type of the object be that of the destructor being called. That is, right before ~derived is entered, the compiler adds code that will modify the vptr to refer to the vtable of derived, so that effectively, the runtime type of the object becomes derived (*).
After the last line of your user defined code, the compiler injects calls to the member destructors as well as base destructor(s). This is performed disabling dynamic dispatch, which means that it will no longer come all the way down to the just executed destructor. It is the equivalent of adding this->~mybase(); for each base of the object (in reverse order of declaration of the bases) at the end of the destructor.
With virtual inheritance, things get a bit more complex, but overall they follow this pattern.
EDIT (forgot the ()): () The standard mandates in §12/3:
When a virtual function is called directly or indirectly from a constructor (including from the mem-initializer for a data member) or from a destructor, and the object to which the call applies is the object under construction or destruction, the function called is the one defined in the constructor or destructor’s own class or in one of its bases, but not a function overriding it in a class derived from the constructor or destructor’s class, or overriding it in one of the other base classes of the most derived object.
That requirement implies that the runtime type of the object is that of the class being constructed/destructed at this time, even if the original object that is being constructed/destructed is of a derived type. A simple test to verify this implementation can be:
struct base { |
运算符
调用 base 的运算符
Base::operator = (target); |










